

Some websites use proprietary web fonts with custom encoding techniques, which can make text extraction from web fonts challenging. Possible solution? Reverse Engineering. This article provides an overview of reverse engineering for proprietary web font extraction.
How Web Fonts Work
Standard web fonts (like WOFF2, WOFF, TTF, or OTF) use common character encoding schemes, primarily Unicode. A Character Map (CMAP) table within the font file links Unicode code points (e.g., U+0041 for ‘A’) to specific glyphs—the visual representation of the character.
The browser uses this CMAP to display the correct glyphs while rendering a web page.
Proprietary web fonts, however, can deviate from this standard by:
- Custom Character Encoding (Private Use Areas – PUA): Instead of standard Unicode points, the font maps glyphs to Unicode’s Private Use Areas or uses an entirely non-standard internal mapping. This means copying text might yield incorrect characters because the underlying codes don’t correspond to their standard visual representations.
- Glyph Reordering/Renaming: The internal names or order of glyphs might be scrambled.
- JavaScript-based Rendering/Mapping: Sometimes, JavaScript is used to dynamically map character codes to glyphs or to render text using these fonts, adding another layer of complexity.
Reverse engineering reconstructs the correct mapping between the visual glyphs displayed on the screen and their standard Unicode characters.
What You Need
Reverse engineering proprietary fonts requires a combination of tools and analytical skills:
- Browser Developer Tools
- Network Tab: To identify and download the font files (WOFF2, WOFF, TTF, etc.).
- Elements/Inspector Tab: To examine the HTML structure and CSS rules (@font-face) that apply the font.
- Sources/Debugger Tab: To inspect JavaScript code that might be involved in font rendering or character mapping.
- Font Editors
- FontForge (Open Source): A powerful tool for viewing and editing font files, including their CMAP tables, glyph outlines, and other metadata.
- Glyphr Studio (Web-based, Open Source): Good for inspecting glyphs and basic font properties.
- Command-Line Font Tools
- FontTools (Python library): An extensive library for manipulating and analyzing font files. It can convert fonts between formats (e.g., WOFF2 to TTF) and dump font tables (like CMAP) into human-readable XML (TTX format).
Proprietary Web Font Extraction: The Process
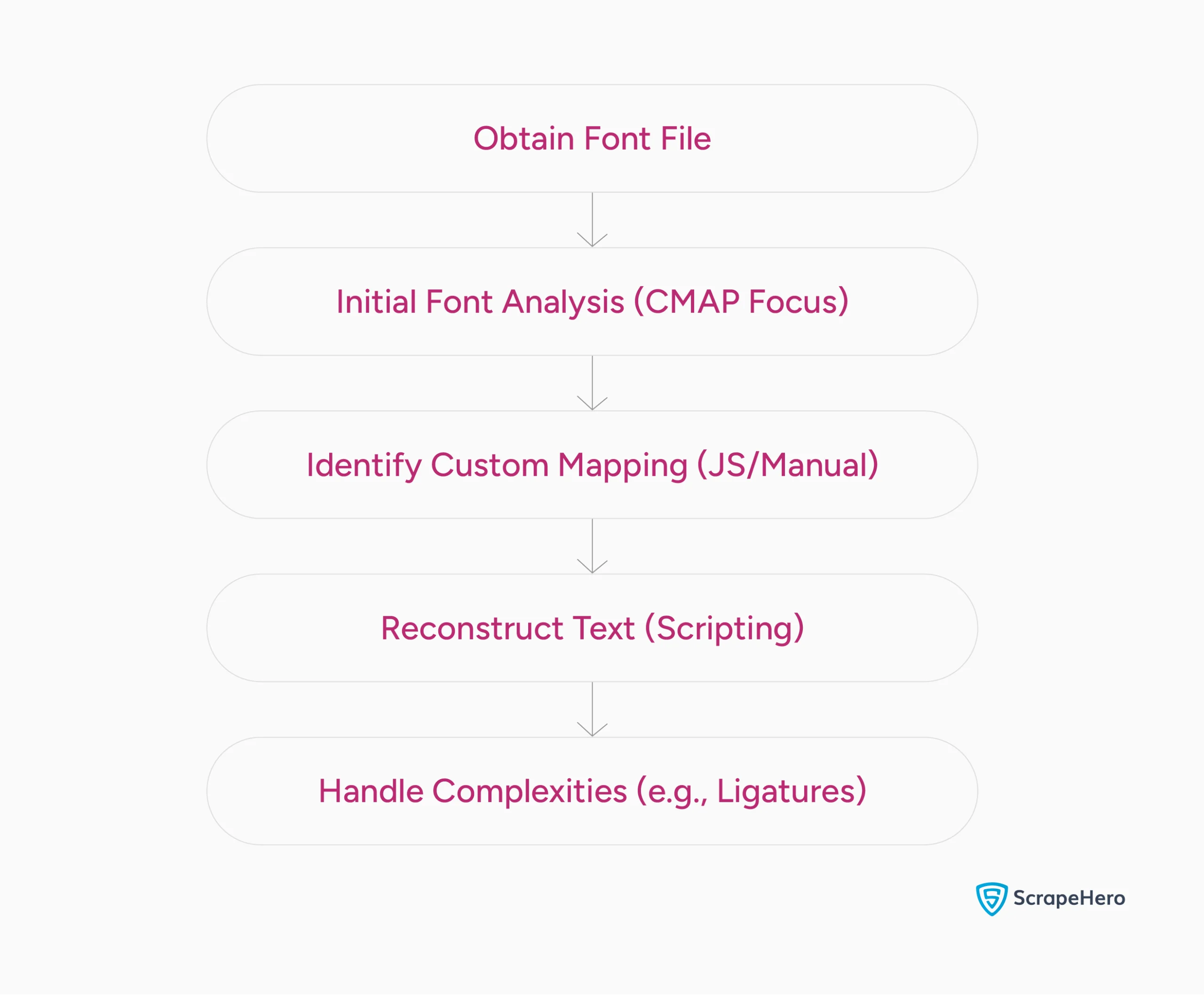
The exact process to reverse engineer web fonts depends on the proprietary font, but you generally need these steps:
Step 1: Obtain the Font File(s)
- Use your browser’s developer tools (Network tab) to identify the web font files being loaded. They often have extensions like .woff, .woff2, or sometimes .ttf or .otf.
- Download these files. If they are WOFF or WOFF2, you might want to convert them to TTF/OTF using FontTools for easier inspection in some font editors, as TTF/OTF is a more foundational format.
Step 2: Initial Font Analysis
- Open the font file (preferably converted to TTF/OTF if necessary) in a font editor like FontForge.
- Examine the CMAP:
- Look for standard Unicode mappings. If you see glyphs for ‘A’, ‘B’, ‘C’ mapped to U+0041, U+0042, U+0043 respectively, the encoding might be standard.
- Pay close attention to glyphs mapped to the Unicode Private Use Area (PUA), which ranges from U+E000 to U+F8FF, U+F0000 to U+FFFFD, and U+100000 to U+10FFFD. If meaningful glyphs are here, it’s a strong indicator of custom encoding.
- Note the number of glyphs and compare it to what you see on the website.
Step 3: Identify the Custom Mapping Logic
Here you’ll manually identify the mapping logic by:
- Visual Comparison and Manual Mapping:
- Take screenshots of text on the website.
- Try to copy-paste the text from the website into a simple text editor.
- If it pastes as readable text, the mapping might be simpler than expected.
- If it pastes as incorrect characters, these are the actual Unicode (likely PUA) codes being used.
- Create a table. In one column, put the visual character (e.g., ‘A’). In another, put the character code you get when copy-pasting (e.g., ” which might be U+E0A0). In a third, put the intended Unicode character (e.g., U+0041).
- Systematically go through the alphabet, numbers, and common punctuation used on the site.
- JavaScript Analysis:
- If the mapping is not straightforward, JavaScript is often involved.
- Look for scripts that:
- Manipulate strings or character codes before they are displayed.
- Reference the font name or CSS classes associated with the proprietary font.
- Contain large arrays or objects that look like lookup tables.
- Use the browser’s debugger to set breakpoints and inspect variables to understand how characters are being processed and mapped.
- Pattern Recognition:
- Sometimes, the custom mapping isn’t random. It might be a simple shift cipher (e.g., ‘A’ is mapped to PUA_START + 0, ‘B’ to PUA_START + 1), a reversal, or some other algorithmic transformation.
Step 4: Reconstruct the Text
Once you have a reliable mapping, you can extract the text:
- Get the “Raw” Encoded Text: This is the sequence of character codes as they are stored in the HTML or as you obtained them from copy-pasting (the PUA codes, for example).
- Apply the Reverse Map: Write a script to iterate through the raw encoded text. For each character code, look up its corresponding standard Unicode character in your custom map.
- Assemble the Corrected Text: Concatenate the translated characters to form the readable text.
Step 5: Handling Ligatures and Complex Glyphs
Some fonts use ligatures (e.g., “fi” combined into a single glyph) or other complex substitutions. Your mapping needs to account for ligatures and complex substitutions if the goal is to get the constituent characters. Font editors can help identify ligatures and complex substitutions.
Ethical and Legal Considerations
Reverse engineering font software and extracting text can have significant legal and ethical implications.
- Font Licensing Agreements: Most commercial fonts, even when used as web fonts, are protected by licenses that explicitly prohibit reverse engineering, modification, or unauthorized copying. Violating these terms can lead to legal action.
- Copyright Law: Font software is often protected by copyright as computer programs. The visual design of a typeface can also be subject to design patents or other forms of intellectual property protection in some jurisdictions.
- Website Terms of Service: Many websites have Terms of Service that prohibit scraping, data extraction, or reverse engineering of their assets.
- Intended Use: Do not use these techniques to pirate fonts, circumvent legitimate security measures for malicious purposes, or infringe on copyright.
- Legitimate Scenarios: Ensure that the reason for text extraction is legitimate, such as
- Accessibility: If a website’s font choices render content inaccessible and the site owner is unresponsive
- Personal Data Recovery/Archiving: If it’s your own data or publicly available data that is difficult to access
Wrapping Up: Why Use a Web Scraping Service
Reverse engineering for proprietary web font extraction requires a methodical approach, the right set of tools, and a good understanding of how fonts and web technologies interact. Moreover, you need to have a strong understanding of the ethical and legal landscape besides having the technical knowledge.
Therefore, if your goal is to get text from a website, it’s better to use a web scraping service. A web scraping service like ScrapeHero can take care of all the technical, legal, and ethical aspects of web scraping.
ScrapeHero is an enterprise-grade web scraping service. For businesses that need high-quality data, ScrapeHero provides Data-as-a-Service, so you can focus on your core business operations.


