
Web scraping using Python in Windows was tough. Installing pip in windows and using it to install packages useful for web scraping was the hardest part of all. Fortunately, those days are over. Python 3 now ships with PIP built-in. It can be installed easily in Windows by downloading Python 3 from Python.org. Follow the steps below to setup python 3 on your Windows 10 computer.
Installing Python 3 and PIP on Windows
Here are the steps
-
- Download Python 3 from Python.org. Python 3.6.4 is the latest stable release at the time of writing this article. You can download it here https://www.python.org/downloads/release/python-364/
- Start the installer. The installation is straightforward. Its good to just verify if PIP is selected in Optional Features (It must be). pip is a package management system used to install and manage software packages written in Python. Many packages can be found in the Python Package Index (PyPI). Make sure you select Add Python3.6 to PATH to add python environment variables to your PATH making Python and PIP accessible from PowerShell or Command Prompt. We will need this to install packages via pip and run scripts from command line using
python <script>
Below is a GIF of the installation process.
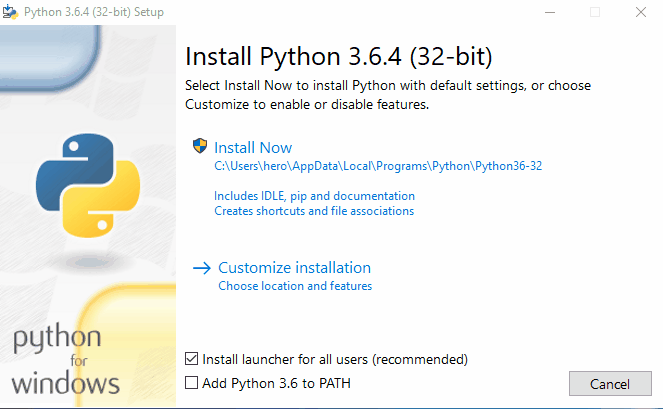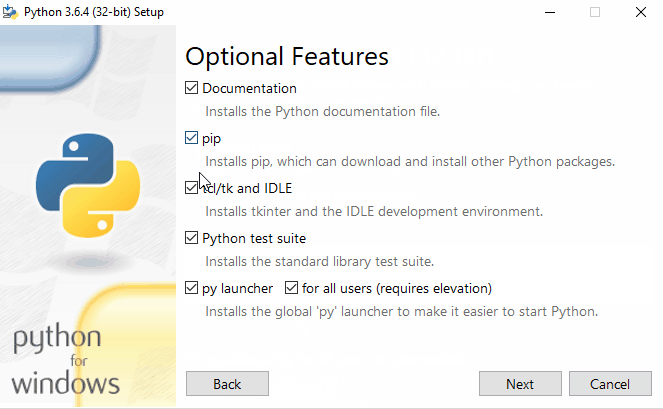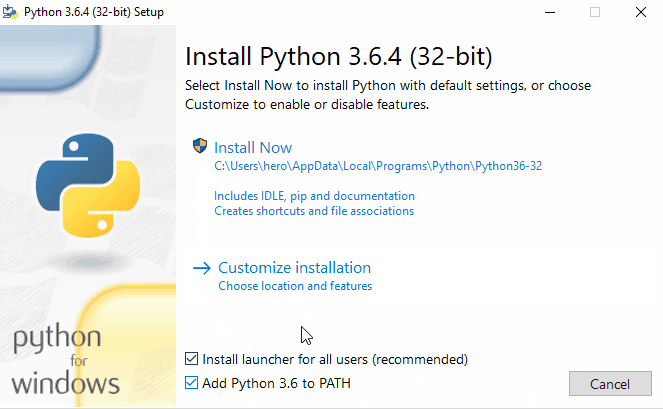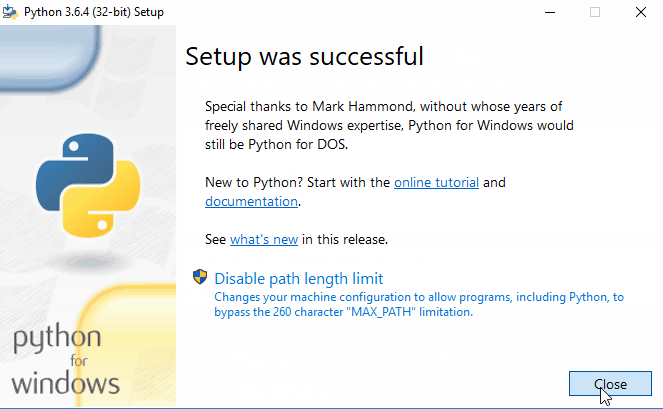
- After setup is successful, Disable path length python limit. If python was installed in a directory with a path length greater than 260 characters, adding it to the path could fail.
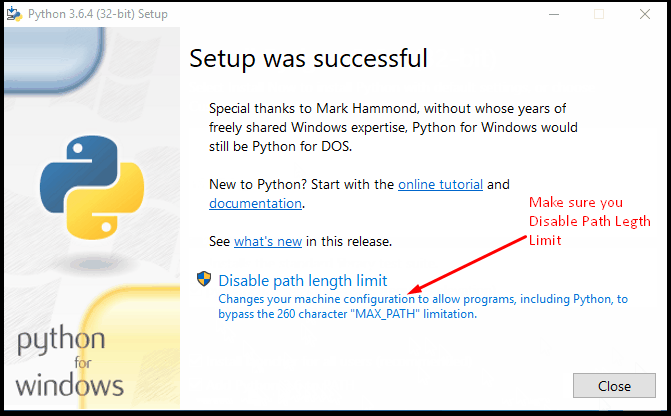
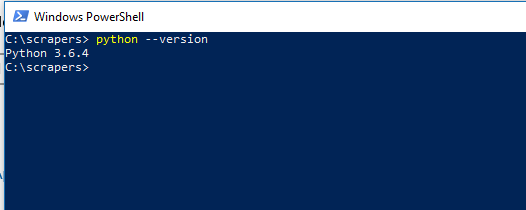
You can close the window now. - Verify Python Installation – Let us verify if it really worked. Open PowerShell (or Command Prompt) and type
python --versionand press enter. You should see a screen similar to the one below with the version of python you installed printed below.
- Verify Pip Installation – Now let’s verify if pip is also installed. In PowerShell (or Command Prompt) type
pip -Vand you should see something like this
That’s it. You’ve set up Python and PIP in windows. Let’s continue to install packages.
Installing Python Packages for Web Scraping
Installing Python Packages is a breeze with PIP. All you have to do is open PowerShell or Command Prompt and type:
pip install <pypi package name>
Here are some of the most common packages we use in our web scraping tutorials
BeautifulSoup
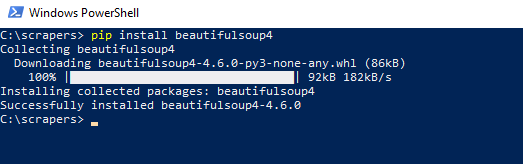
BeautifulSoup is a library for pulling data out of HTML and XML files. It works with your favorite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work. Install BeautifulSoup in Windows with this command:
pip install BeautifulSoup4
You’ll get a screen similar to this when done.
LXML
LXML is the most feature-rich and easy-to-use library for processing XML and HTML in the Python language. We use LXML to parse HTML content downloaded from web pages by converting it into a Tree Like structure that can be navigated programmatically using semi-structured Query Languages like XPaths or CSS Selectors.
Install it using
pip install lxml
You’ll get a screen similar to this when done.
Requests – HTTP for Humans
Although python has its own HTTP Libraries, requests cut down lots of manual labor that comes with urllib. Requests allow you to send organic, grass-fed HTTP/1.1 requests, without the need for manual labor. There’s no need to manually add query strings to your URLs or to form-encode your POST data. Keep-alive and HTTP connection pooling are 100% automatic, thanks to urllib3. Install it using
pip install requests
Once done it would look like this
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



