
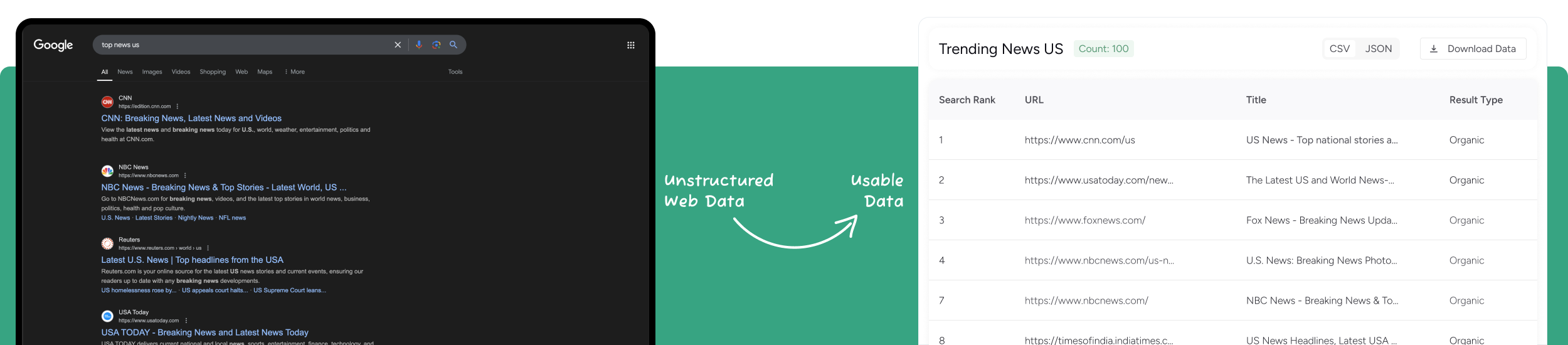
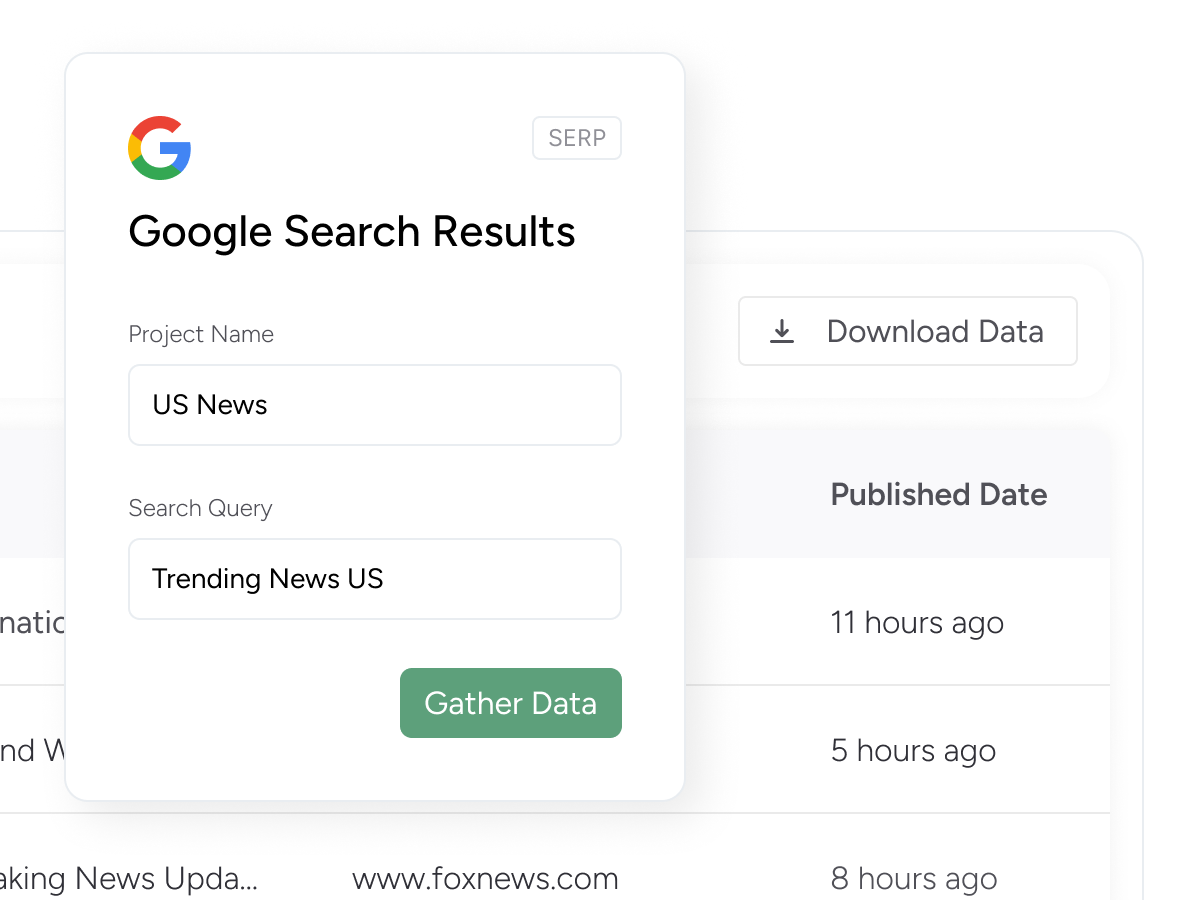
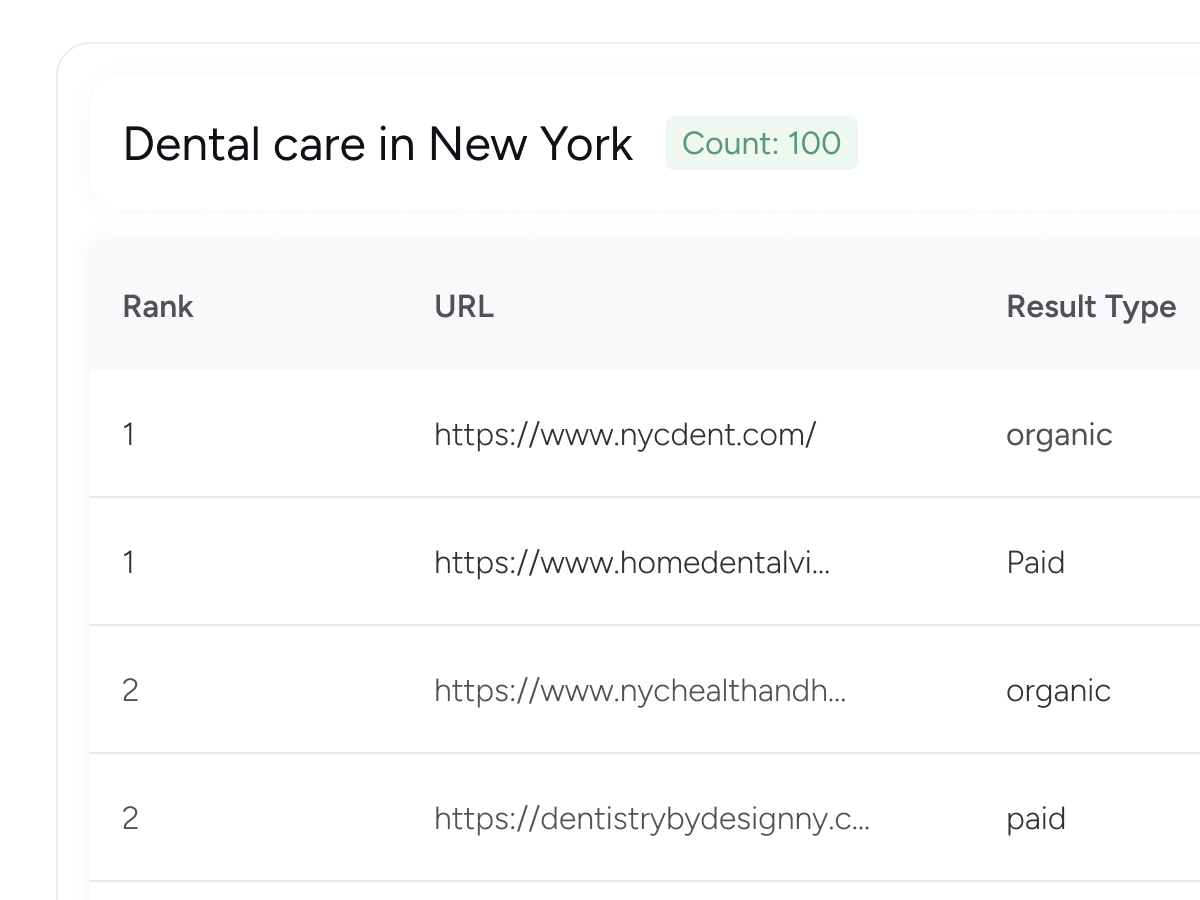
Scrape Google search results page (SERP) data. Gather details like Google Ranking, Organic and Paid Results, Description, Website, Infobox, and more.
It’s as easy as Copy and Paste
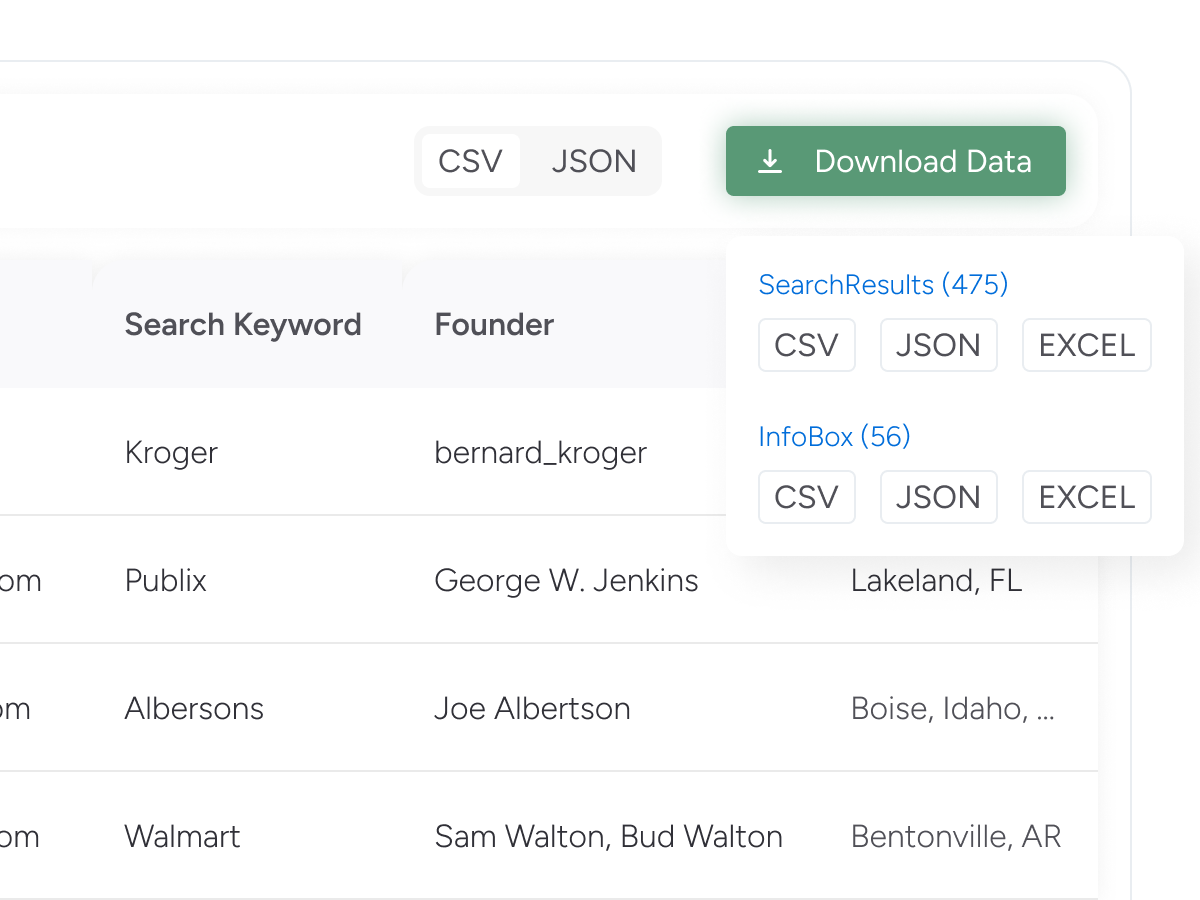
Download the data in Excel, CSV, or JSON formats. Link a cloud storage platform like Dropbox to store your data.
Schedule automated crawls to deliver fresh data to Dropbox, AWS S3, Google Drive, or to your app via API. Choose hourly, daily, or weekly updates to stay current.
| Rank | Result Type | Title | URL | Breadcrumbs | Description | Published Date | Rating | Search Keyword | Page |
|---|---|---|---|---|---|---|---|---|---|
| 12 | organic | What's the deal with the McDonald's on Causeway St? | https://www.reddit.com/r/boston/comments/1iq3v8r/whats_the_deal_with_the_mcdonalds_on_causeway_st/ | 10+ comments * 3 days ago | McDonald's forgot they own it, they don't care. Instead Boston should raise the taxes on vacant properties. | - | - | mcdonald in boston | 2 |
| 2 | organic | Fast Food in Boston, MA at 329 Washington St | https://www.mcdonalds.com/us/en-us/location/ma/boston/329-washington-st/31643.html | https://www.mcdonalds.com > en-us > location > 329-w... | Looking for Fast food near you? Visit McDonald's in Boston, MA at 329 Washington St , for breakfast, burgers, fries, and more, or order online! | - | - | mcdonald in boston | 1 |
| 3 | organic | Fast Food in Boston, MA at 540 Commonwealth Ave | https://www.mcdonalds.com/us/en-us/location/ma/boston/540-commonwealth-ave/17677.html | https://www.mcdonalds.com > en-us > location > 540-c... | Looking for Fast food near you? Visit McDonald's in Boston, MA at 540 Commonwealth Ave , for breakfast, burgers, fries, and more, or order online! | - | - | mcdonald in boston | 1 |
| 17 | organic | McDonald's - CLOSED, 100 Legends Way, Boston, MA ... | https://www.mapquest.com/us/massachusetts/mcdonalds-529037701 | https://www.mapquest.com > ... > Massachusetts > Boston | Get more information for McDonald's in Boston , MA. See reviews, map, get the address, and find directions. | - | - | mcdonald in boston | 2 |
| 7 | organic | Fast Food in East Boston, MA at 178 Border St | https://www.mcdonalds.com/us/en-us/location/ma/east-boston/178-border-st/2845.html | https://www.mcdonalds.com > en-us > location > 178-b... | Looking for Fast food near you? Visit McDonald's in East Boston, MA at 178 Border St , for breakfast, burgers, fries, and more, or order online! | - | - | mcdonald in boston | 1 |
| 18 | organic | McDonald's North Station Update : r/boston | https://www.reddit.com/r/boston/comments/1b2yir1/mcdonalds_north_station_update/ | 80+ comments * 11 months ago | The mcdonalds is going in across from the takeout window, next to the old ticket booths. I don't know if it will have an entrance on that side, ... | - | - | mcdonald in boston | 2 |
| 4 | organic | MCDONALD'S, Boston - 540 Commonwealth Ave, Fenway ... | https://www.tripadvisor.com/Restaurant_Review-g60745-d4718723-Reviews-McDonald_s-Boston_Massachusetts.html | https://www.tripadvisor.com > ... > Boston Restaurants | You get reliable burgers and fries here, but there is so much ore on the expanded menu, so stretch a bit. Reliable and predictable. 3.5 (33) * Price range: $ | - | - | mcdonald in boston | 1 |
| 5 | organic | Ronald McDonald House Boston Harbor | https://rmhbostonharbor.org/ | https://rmhbostonharbor.org | Ronald McDonald House Boston Harbor is a place families of critically ill children can stay to be close to their child who is receiving treatment in Boston. | - | - | mcdonald in boston | 1 |
| 6 | organic | McDonald's Downtown, Boston, MA 02228 | https://m.yelp.com/search?find_desc=mcdonald%27s&find_loc=Downtown%2C+Boston%2C+MA+02228 | https://m.yelp.com > Restaurants > Mcdonald's | mcdonald's Downtown, Boston, MA 02228 * 1. McDonald's. 2.2 (58 reviews). 0.1 mi. 329 Washington St, Boston, MA 02108 * 2. McDonald's. 2.0 (83 reviews). 0.3 mi. | - | - | mcdonald in boston | 1 |
[
{
"breadcrumbs": "10+ comments * 3 days ago",
"description": "McDonald's forgot they own it, they don't care. Instead Boston should raise the taxes on vacant properties.",
"page": "2",
"published_date": null,
"rank": "12",
"rating": null,
"result_type": "organic",
"search_keyword": "mcdonald in boston",
"title": "What's the deal with the McDonald's on Causeway St?",
"url": "https://www.reddit.com/r/boston/comments/1iq3v8r/whats_the_deal_with_the_mcdonalds_on_causeway_st/"
},
{
"breadcrumbs": "https://www.mcdonalds.com > en-us > location > 329-w...",
"description": "Looking for Fast food near you? Visit McDonald's in Boston, MA at 329 Washington St , for breakfast, burgers, fries, and more, or order online!",
"page": "1",
"published_date": null,
"rank": "2",
"rating": null,
"result_type": "organic",
"search_keyword": "mcdonald in boston",
"title": "Fast Food in Boston, MA at 329 Washington St",
"url": "https://www.mcdonalds.com/us/en-us/location/ma/boston/329-washington-st/31643.html"
},
{
"breadcrumbs": "https://www.mcdonalds.com > en-us > location > 540-c...",
"description": "Looking for Fast food near you? Visit McDonald's in Boston, MA at 540 Commonwealth Ave , for breakfast, burgers, fries, and more, or order online!",
"page": "1",
"published_date": null,
"rank": "3",
"rating": null,
"result_type": "organic",
"search_keyword": "mcdonald in boston",
"title": "Fast Food in Boston, MA at 540 Commonwealth Ave",
"url": "https://www.mcdonalds.com/us/en-us/location/ma/boston/540-commonwealth-ave/17677.html"
},
{
"breadcrumbs": "https://www.mapquest.com > ... > Massachusetts > Boston",
"description": "Get more information for McDonald's in Boston , MA. See reviews, map, get the address, and find directions.",
"page": "2",
"published_date": null,
"rank": "17",
"rating": null,
"result_type": "organic",
"search_keyword": "mcdonald in boston",
"title": "McDonald's - CLOSED, 100 Legends Way, Boston, MA ...",
"url": "https://www.mapquest.com/us/massachusetts/mcdonalds-529037701"
},
{
"breadcrumbs": "https://www.mcdonalds.com > en-us > location > 178-b...",
"description": "Looking for Fast food near you? Visit McDonald's in East Boston, MA at 178 Border St , for breakfast, burgers, fries, and more, or order online!",
"page": "1",
"published_date": null,
"rank": "7",
"rating": null,
"result_type": "organic",
"search_keyword": "mcdonald in boston",
"title": "Fast Food in East Boston, MA at 178 Border St",
"url": "https://www.mcdonalds.com/us/en-us/location/ma/east-boston/178-border-st/2845.html"
},
{
"breadcrumbs": "80+ comments * 11 months ago",
"description": "The mcdonalds is going in across from the takeout window, next to the old ticket booths. I don't know if it will have an entrance on that side, ...",
"page": "2",
"published_date": null,
"rank": "18",
"rating": null,
"result_type": "organic",
"search_keyword": "mcdonald in boston",
"title": "McDonald's North Station Update : r/boston",
"url": "https://www.reddit.com/r/boston/comments/1b2yir1/mcdonalds_north_station_update/"
},
{
"breadcrumbs": "https://www.tripadvisor.com > ... > Boston Restaurants",
"description": "You get reliable burgers and fries here, but there is so much ore on the expanded menu, so stretch a bit. Reliable and predictable. 3.5 (33) * Price range: $",
"page": "1",
"published_date": null,
"rank": "4",
"rating": null,
"result_type": "organic",
"search_keyword": "mcdonald in boston",
"title": "MCDONALD'S, Boston - 540 Commonwealth Ave, Fenway ...",
"url": "https://www.tripadvisor.com/Restaurant_Review-g60745-d4718723-Reviews-McDonald_s-Boston_Massachusetts.html"
},
{
"breadcrumbs": "https://rmhbostonharbor.org",
"description": "Ronald McDonald House Boston Harbor is a place families of critically ill children can stay to be close to their child who is receiving treatment in Boston.",
"page": "1",
"published_date": null,
"rank": "5",
"rating": null,
"result_type": "organic",
"search_keyword": "mcdonald in boston",
"title": "Ronald McDonald House Boston Harbor",
"url": "https://rmhbostonharbor.org/"
},
{
"breadcrumbs": "https://m.yelp.com > Restaurants > Mcdonald's",
"description": "mcdonald's Downtown, Boston, MA 02228 * 1. McDonald's. 2.2 (58 reviews). 0.1 mi. 329 Washington St, Boston, MA 02108 * 2. McDonald's. 2.0 (83 reviews). 0.3 mi.",
"page": "1",
"published_date": null,
"rank": "6",
"rating": null,
"result_type": "organic",
"search_keyword": "mcdonald in boston",
"title": "McDonald's Downtown, Boston, MA 02228",
"url": "https://m.yelp.com/search?find_desc=mcdonald%27s&find_loc=Downtown%2C+Boston%2C+MA+02228"
}
]
Enrich your database using data from the Google Knowledge Graph (Infobox). You can get key information about People, Companies, and Places such as:
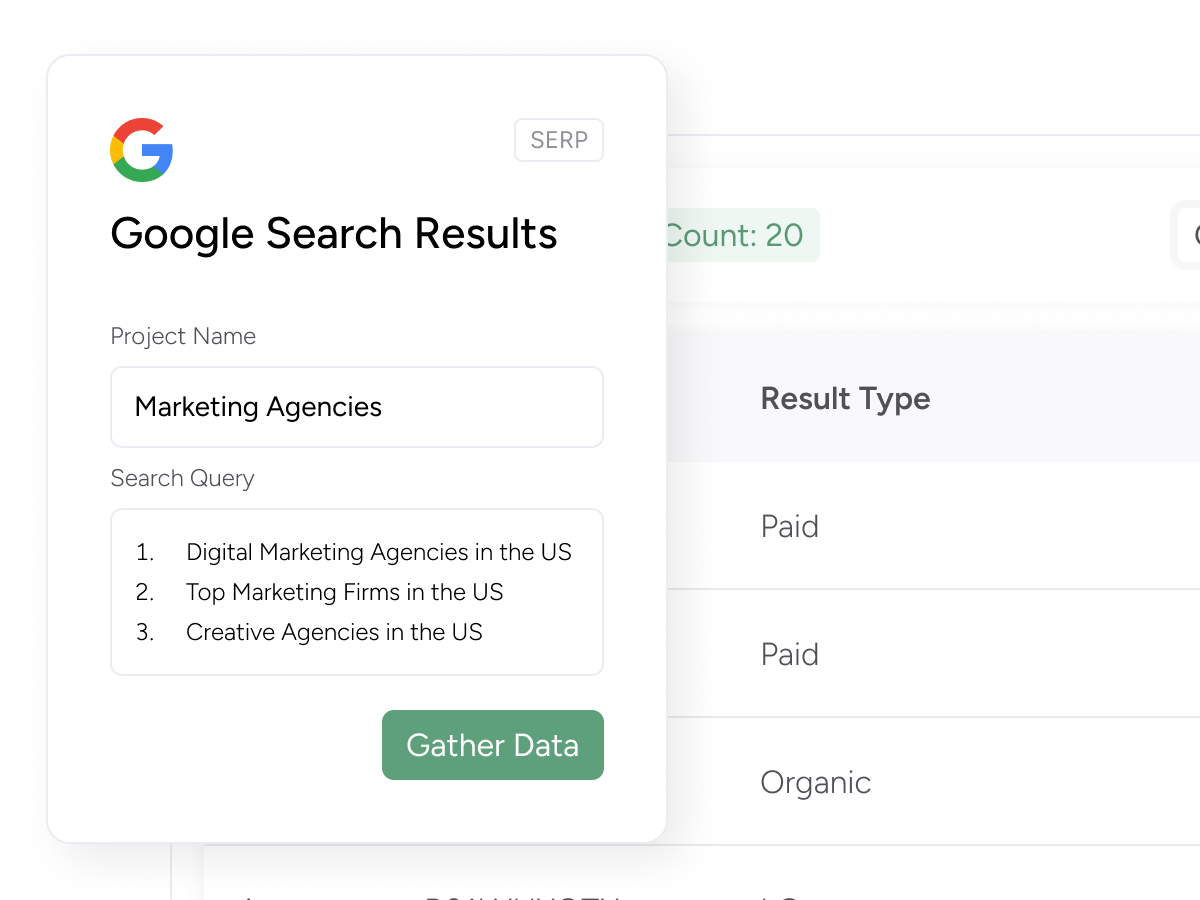
You can gather both paid and organic results from Google for any search term. Just provide the search term as input to start scraping data.
Example:
We have a wide variety of Google scrapers and Real-Time APIs available in our Marketplace. You can use these web scraping tools to extract more data from Google.
Does not renew
Compare all features &
choose what works best for you
Need More?
Contact us for a custom plan based on your needs.
Join 12400+ customers who love working with ScrapeHero
A few mouse clicks and copy/paste is all that it takes!
Get data like the pros without knowing programming at all.
The crawlers are easy to use, but we are here to help when you need help.

Schedule the crawlers to run hourly, daily, or weekly and get data delivered to your Dropbox.
We will take care of all website structure changes and blocking from websites.
Can’t find what you’re looking for? Check out Cloud Support for assistance!
All our plans require a subscription that renews monthly. If you only need to use our services for a month, you can subscribe to our service for one month and cancel your subscription in less than 30 days.
Yes. You can set up the crawler to run periodically by clicking and selecting your preferred schedule. You can schedule crawlers to run on a Monthly, Weekly, or Hourly interval.
No, We won’t use your IP address to scrape the website. We’ll use our proxies and get data for you. All you have to do is, provide the input and run the scraper.
Unfortunately, we will not be able to provide you a refund/data credits if you made a mistake.
Here are some common scenarios we have seen for quota refund requests
If you cancel, you’ll be billed for the current month, but you won’t be charged again. If you have any page credits, you can still use our service until it reaches its limit.
Some crawlers can collect multiple records from a single page, while others might need to go to 3 pages to get a single record. For example, our Amazon Bestsellers crawler collects 50 records from one page, while our Indeed crawler needs to go through a list of all jobs and then move into each job details page to get more data.
All our data credit reset at the end of the billing period. Any unused credits do not carry over to the next billing period and also are nonrefundable. This is consistent with most software subscription services.
Sure, we can build custom solutions for you. Please contact our Sales team using this link, and that will get us started. In your message, please describe in detail what you require.
Most sites will display product pricing, availability and delivery charges based on the user location. Our crawler uses locations from US states so that the pricing may vary. To get accurate results based on a location, please contact us.
We scrape what is returned by Google for a particular search term. If the search term you provide to Google while searching manually shows the data you need, the scraper will be able to scrape it. If Google does not return the results that you need, we will not be able to help you. We only scrape what Google returns.
Contact us to schedule a brief, introductory call with our experts and learn how we can assist your needs.

Legal Disclaimer: ScrapeHero is an equal opportunity data service provider, a conduit, just like an ISP. We just gather data for our customers responsibly and sensibly. We do not store or resell data. We only provide the technologies and data pipes to scrape publicly available data. The mention of any company names, trademarks or data sets on our site does not imply we can or will scrape them. They are listed only as an illustration of the types of requests we get. Any code provided in our tutorials is for learning only, we are not responsible for how it is used.


