
Extract product data from Amazon. Gather product details such as pricing, availability, rating, best seller rank, and 25+ data points from the Amazon product page.
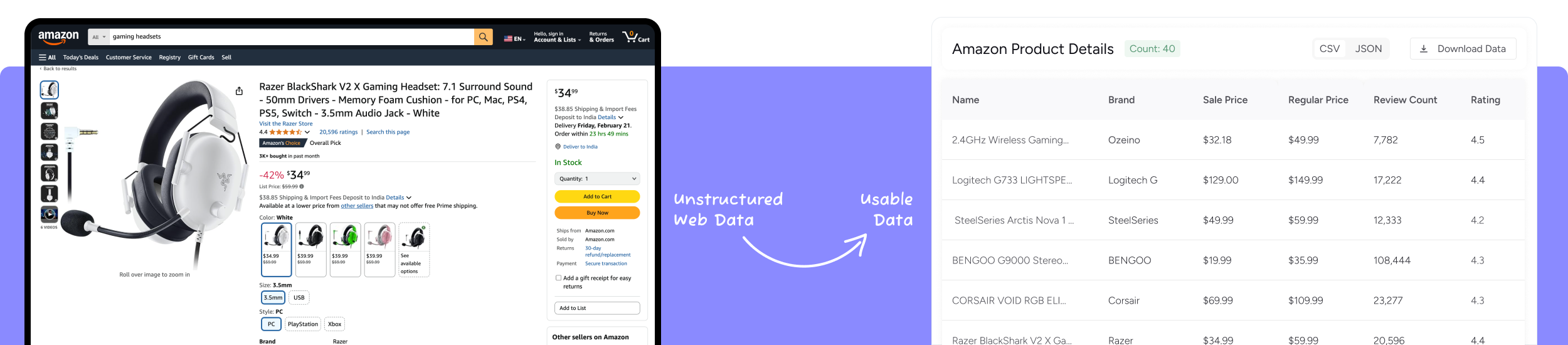
It’s as easy as Copy and Paste
Download the data in Excel, CSV, or JSON formats. Link a cloud storage platform like Dropbox to store your data.
Schedule automated crawls to deliver fresh data to Dropbox, AWS S3, Google Drive, or to your app via API. Choose hourly, daily, or weekly updates to stay current.
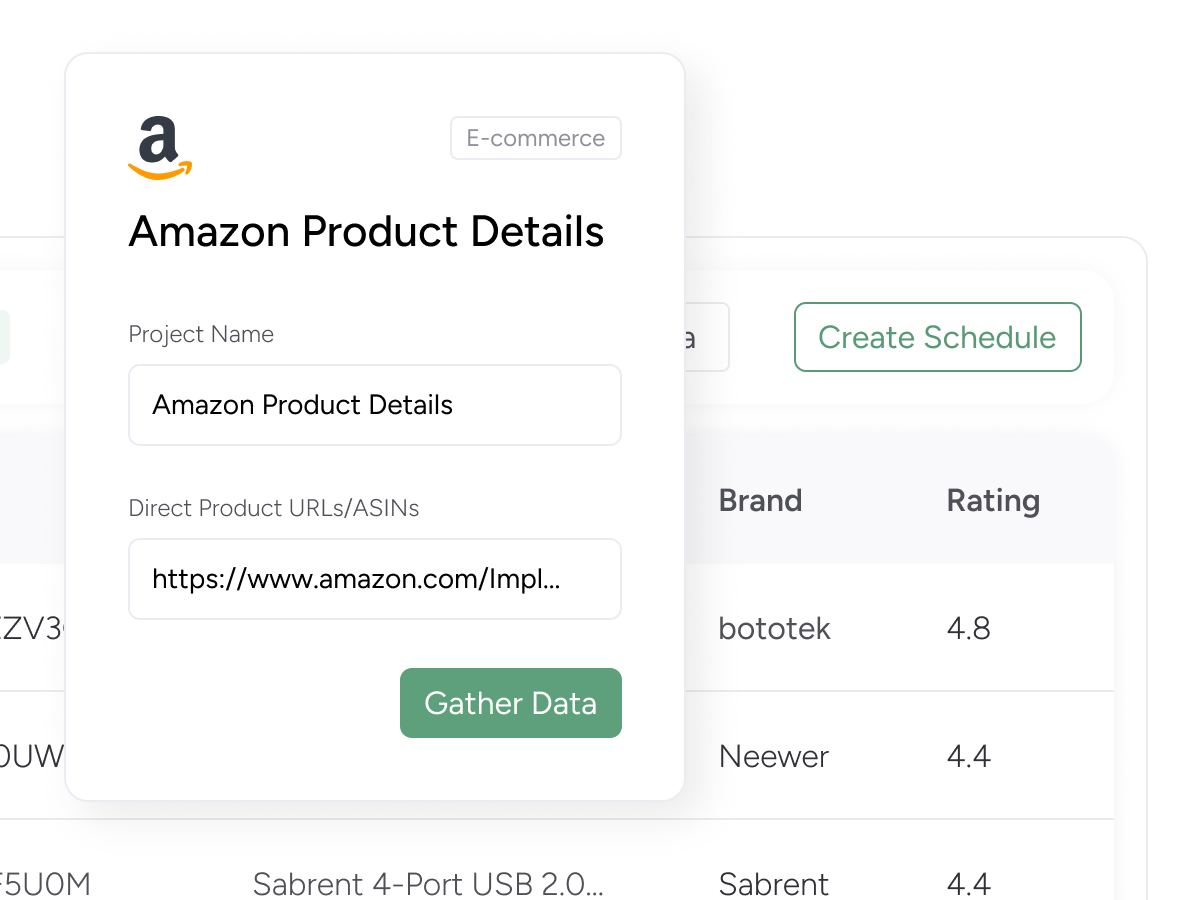
| URL | ASIN | Name | Brand | Seller | Seller URL | Review Count | Category | Rating | Currency | Sale Price | Regular Price | Shipping Charge | Small Description | Full Description | Availability Status | Available Quantity | Model | Attributes | Product Category | Product Information | Highlighted Specifications | Image URLs | Variation Asin | Product Variations | Frequently Bought Together | Product Reviews | Sponsored Products | Rating Histogram |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| https://www.amazon.com/Ozeino-2-4GHz-Wireless-Gaming-Headset/dp/B0C4F9JGTJ/ref=sr_1_3?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-3&th=1 | B0C4F9JGTJ | 2.4GHz Wireless Gaming Headset for PC, Ps5, Ps4 - Lossless Audio USB & Type-C Ultra Stable Gaming Headphones with Flip Microphone, 40-Hr Battery Gamer Headset for Switch, Laptop, Mobile, Mac | Ozeino | WU MEIJIAO storeWU MEIJIAO store | https://www.amazon.com/gp/help/seller/at-a-glance.html/ref=dp_merchant_link?ie=UTF8&seller=A3AUHWT8COGTZ8&asin=B0C4F9JGTJ&ref_=dp_merchant_link&isAmazonFulfilled=1 | 7,920 | [{"level": 1, "name": "Video Games", "url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"}, {"level": 2, "name": "Legacy Systems", "url": "/Systems-Games/b/ref=dp_bc_aui_C_2?ie=UTF8&node=294940"}, {"level": 3, "name": "PlayStation Systems", "url": "/b/ref=dp_bc_aui_C_3?ie=UTF8&node=23563592011"}, {"level": 4, "name": "PlayStation", "url": "/PlayStation-Games/b/ref=dp_bc_aui_C_4?ie=UTF8&node=229773"}, {"level": 5, "name": "Accessories", "url": "/Accessories-PlayStation-Hardware/b/ref=dp_bc_aui_C_5?ie=UTF8&node=15891181"}] | 4.4 | USD | 32.08 | 49.99 | - | 【Amazing Stable Connection-Quick Access to Games】Real-time gaming audio with our 2.4GHz USB & Type-C ultra-low latency wireless connection. With less than 30ms delay, you can enjoy smoother operation and stay ahead of the competition, so you can enjoy an immersive lag-free wireless gaming experience. - 【Game Communication-Better Bass and Accuracy】The 50mm driver plus 2.4G lossless wireless transports you to the gaming world, letting you hear every critical step, reload, or vocal in Fortnite, Call of Duty, The Legend of Zelda and RPG, so you will never miss a step or shot during game playing. You will completely in awe with the range, precision, and audio quality your ears were experiencing. - 【Flexible and Convenient Design-Effortless in Game】Ideal intuitive button layout on the headphones for user. Multi-functional button controls let you instantly crank or lower volume and mute, quickly answer phone calls, cut songs, turn on lights, etc. Ease of use and customization, are all done with passion and priority for the user. - 【Less plug, More Play-Dual Input From 2.4GHz & Bluetooth】 Wireless gaming headset adopts high performance dual mode design. With a 2.4GHz USB dongle, which is super sturdy, lag<30ms, perfectly made for gamers. Bluetooth mode only work for phone, laptop and switch. And 3.5mm wired mode (Only support music and call). - 【Wide Compatibility with Gaming Devices】Setup the perfect entertainment system by plugging in 2.4G USB. The convenience of dual USB work seamlessly with your PS5,PS4, PC, Mac, Laptop, Switch and saves you from swapping cables. - Bluetooth function CANT'T directly SUPPORT with Mac, Ps5, Ps4,Pc, additional USB Bluetooth Adapter is required (not included). Recommend to use the 2.4G mode, it easy and amazing connect. - The 2 in 1 USB transmitter needs to be combined to connect for Ps/Ps2/Ps5/Ps4/PC/Laptop/Mac, can't be used separately. NOT:OW810 wireless gaming headset NOT Compatible with Xbox. | Previous page Next page 1 Quick Flexible Control 2 Noise Cancelling Mic 3 Amazing Battery Life 4 Soft Memory Foam If low power remind, How long can it use? . If remind low power, at least 10-20 mins left . And we suggest you can charge for 10 mins, then you can play at least for 100 mins . 10 mins charged, 100 mins used Can I use Bluetooth mode with PC and PS5/4? Bluetooth function doesn't directly support PS5, PS4,PC, additional 「USB Bluetooth Adapter」 is required (not included), recommend to use the 2.4G USB mode in PS5, PS4, PC devices. How do I mute the microphone? 1. Turn on/off the mic : Double-click the button "+" . 2. Check the mute setting of your device. 3. Directly to ask seller. (We always here) How to connect the PS5/PS4? 1.Connect the USB into USB port on PS4/5 main box 2.Setting headset to 2.4GHz mode 2.Console settings: Main menu-Settings-Devices-Audio-Audio devices-Set input & output device to OW810-Set output to headphones to all audion-Set volume control to 100% Is this headset with wired mode? · We attached a 3.5mm cable, when headset is low power, wired mode could be used for urgent · Note: Our 3.5mm cable & USB transmiter not compatible with xbox series s. | In Stock | - | OW810 | color: White | Video Games > Legacy Systems > PlayStation Systems > PlayStation > Accessories | [{"ASIN": "B0C4F9JGTJ", "Age Range (Description)": "Adult", "Amazon Best Sellers Rank": "#23 in Video Games , #1 in PlayStation 2 Accessories , #1 in PlayStation Accessories , #3 in PlayStation 5 Headsets", "Audio Driver Size": "50 Millimeters", "Audio Driver Type": "Dynamic Driver", "Audio Latency": "20 Milliseconds", "Batteries": "1 Lithium Metal batteries required. (included)", "Battery Life": "40 Hours", "Bluetooth Range": "15 Feet", "Bluetooth Version": "5.3", "Cable Feature": "Detachable", "Charging Time": "2.98 Hours", "Compatible Devices": "playstation_2, PlayStation_5, playstation, nintendo_switch, playstation_4", "Connectivity Technology": "Wireless", "Control Method": "Touch", "Control Type": "Volume Control", "Controller Type": "Touch", "Country of Origin": "China", "Date First Available": "May 8, 2023", "Earpiece Shape": "Circle", "Headphones Jack": "3.5 mm Jack", "Included Components": "1* Wireless Gaming Headset Black, 1* USB & Type -C Transmitter, 1* User Manual, 1* 3.5 mm Aux Cable & Charging Cable", "Is Autographed": "No", "Item Weight": "1.08 pounds", "Item model number": "OW810", "Manufacturer": "Ozeino", "Material": "Plastic", "Model Name": "OW810", "Noise Control": "Sound Isolation", "Number of Items": "1", "Package Type": "Standard Packaging", "Product Dimensions": "5.91 x 3.94 x 7.87 inches", "Recommended Uses For Product": "Gaming", "Specific Uses For Product": "Enjoy the game, music", "Style": "Modern", "Theme": "Video Game", "Unit Count": "1.0 Count", "Wireless Communication Technology": "USB-C&A,Bluetooth"}] | [{"Brand": "Ozeino", "Color": "White", "Ear Placement": "Over Ear", "Form Factor": "Over Ear", "Impedance": "32 Ohm"}] | https://m.media-amazon.com/images/I/71nUYWaf0RL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/816uvsDE8rL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/81RD5G0eFfL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71Lw8KkOo2L._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/7121w4lIQvL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/81FiSCzfkZL._AC_SL1500_.jpg | [{"asin": "B0DR8YG8D5", "color_name": "Red"}, {"asin": "B0DR8WLWDF", "color_name": "Blue"}, {"asin": "B0C4F9JGTJ", "color_name": "White"}, {"asin": "B0C49F6NG6", "color_name": "Black"}, {"asin": "B0DF7D1WLM", "color_name": "Pink"}, {"asin": "B0DJR519T2", "color_name": "Camouflage"}, {"asin": "B0D95Y2Z1K", "color_name": "Yellow"}] | [{"color_name": ["Black", "Blue", "Camouflage", "Pink", "Red", "White", "Yellow"]}] | [{"link": "https://www.amazon.com/Gtheos-Bluetooth-Headphones-Detachable-Microphone/dp/B0B4B2HW2N/ref=pd_bxgy_d_sccl_1/138-1533047-4336725?pd_rd_w=0e6MV&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=3HYQN9N1DWJ06DEX71N8&pd_rd_wg=oBtem&pd_rd_r=6a03dfba-02b7-4e7d-b756-9adaa7f5ce50&pd_rd_i=B0B4B2HW2N&psc=1", "price": "$33.99", "title": "Gtheos 2.4GHz Wireless Gaming Headset for PS5, PS4 Fortnite & Call of Duty/FPS Gamers, PC, Nintendo Switch, Bluetooth 5.3 Gaming Headphones with Noise Canceling Mic, Stereo Sound, 40+Hr Battery -White"}, {"link": "https://www.amazon.com/OIVO-Controller-Compatible-Playstation-Indicators/dp/B08LZGPPBH/ref=pd_bxgy_d_sccl_2/138-1533047-4336725?pd_rd_w=0e6MV&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=3HYQN9N1DWJ06DEX71N8&pd_rd_wg=oBtem&pd_rd_r=6a03dfba-02b7-4e7d-b756-9adaa7f5ce50&pd_rd_i=B08LZGPPBH&psc=1", "price": "$19.99", "title": "OIVO PS5 Controller Charger PS5 Accessories Kits with Fast Charging AC Adapter, Controller Charging Stand for PlayStation 5, Docking Station Replacement for DualSense Charging Station"}] | [{"author_name": "Charity Wiberg", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEJZQCDLKS2BWTY4V4LETRFFF6YQ/ref=cm_cr_dp_d_gw_pop?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I have been using this headset for a couple months now and can say I am VERY satisfied. At a budget-friendly price, they deliver impressive sound performance. The build quality feels sturdy, yet lightweight, making them durable without being heavy on the head. They are also extremely comfortable will nice ear muffs. While also having a nice clean color for both the base and LED\u2019s. Its Bluetooth is amazing. I was able to connect it to a Roku TV, laptop, iPhone, and iPad. It remains well connected even after traveling a far distance away from a device. Allowing for music sessions while cleaning. Buttons were easy to use a simple power on and volume adjustment system that was straightforward to use. I overall I recommend these headphones. They have good sound quality for games and it\u2019s good quality for the price.", "review_title": "Affordable, Quality, And Comfort", "review_url": "https://www.amazon.com/gp/customer-reviews/R2MN7XJDFQDWED/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ", "reviewed_date": "January 09, 2025", "reviewed_product_variant": "Color: White"}, {"author_name": "Marjorie", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFPQY5LOYGKB6FYKTSFJPQIXHI5Q/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I bought this Bluetooth headset for my son as a Christmas gift to use with his PS4, and it has exceeded all expectations! He absolutely loves it and says it\u2019s the best headset in the world. The sound quality is incredible, with crystal-clear audio and great bass, making his gaming experience immersive and enjoyable. The mic picks up his voice perfectly, so he has no trouble communicating with his friends during multiplayer games. The headset is also super comfortable, even during long gaming sessions, and the battery life is outstanding\u2014it lasts all day without needing a recharge. Setup was quick and easy, and it connected to his PS4 seamlessly. He hasn\u2019t stopped raving about it, and I\u2019m thrilled I found something he enjoys so much. Highly recommend this headset to any gamer out there\u2014it\u2019s worth every penny!", "review_title": "Best headset ever", "review_url": "https://www.amazon.com/gp/customer-reviews/R10ONB3FT7J2MM/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ", "reviewed_date": "December 29, 2024", "reviewed_product_variant": "Color: White"}, {"author_name": "Professor Anthrax & The Witch", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEXAODXMPHBNDELU76IBTQB2RD2A/ref=cm_cr_dp_d_gw_pop?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "These belong to my wife. She has had these headphones for over six months of constant use. She works a job that requires 8-11 hours per day of use or standby (powered on). She averages 2-4 hours per day of talk time. She tells me these headphones are, and continue to be, very comfortable to use; and the sound quality through the headphones is excellent, with no distortion. She says the microphone gain is also good; she has never had anyone complain they couldn't hear her, like her original headset. Even after over six months of use they are in excellent condition, showing no signs of wear. She uses them primarily with the 2.5 GHz connection, although the few times she used the Bluetooth connection they have also connected quickly and flawlessly. She never had an issue with them running out of charge while working; although she does plug them in each day after work. Overall a decent quality product for the price.", "review_title": "Comfortable, Good sound quality, Good Microphone quality, Good battery life.", "review_url": "https://www.amazon.com/gp/customer-reviews/R3L9XNTV2NJH2P/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ", "reviewed_date": "February 04, 2025", "reviewed_product_variant": "Color: Black"}, {"author_name": "Cass", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AG6IGXL5SWAOVBOLZ3X7LQOPMDDQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "Bought these for my husband so he can ignore his wife and kids with ease (lol) while playing his games. They have great noise cancellation, and he says the mute feature button for the mic is \u201cexclusive\u201d and easy to use quickly while dunking on his opponents or trying to cut off the sound of children screaming in the background. The led lights are sick. Bluetooth is easy to set up and pairs effortlessly. Battery life is incredible. All around good buy. They\u2019ve outlasted several other inferior products by a mile and is quite durable.", "review_title": "Extraordinary Headphones, with great quality at a great price!", "review_url": "https://www.amazon.com/gp/customer-reviews/R1F19H0FUUPW1A/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ", "reviewed_date": "January 08, 2025", "reviewed_product_variant": "Color: White"}, {"author_name": "Jennifer", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHGNQVNCPGABQ3XZHGKZTDILTCHA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I recently purchased this headset for my son, and it\u2019s been an absolute game-changer! It works flawlessly with the PS5, delivering great sound quality and crystal-clear communication. The noise-cancellation feature really helps him immerse in the game without distractions, and the comfort level is top-notch\u2014perfect for those long gaming sessions. The durability is impressive as well. After a few weeks of heavy use, it\u2019s holding up great, which is a relief for me as a parent. The built-in mic works perfectly for in-game chats, making it easy to communicate with friends or teammates. Overall, this headset has exceeded expectations. Highly recommend it for anyone looking for a reliable, high-quality option for PS5 gaming!", "review_title": "Perfect headset", "review_url": "https://www.amazon.com/gp/customer-reviews/RKJ2UD7FJ7BF3/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ", "reviewed_date": "December 30, 2024", "reviewed_product_variant": "Color: White"}, {"author_name": "Miranda Ryan", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEMVKC2MVQGYU5SULN3VESBGEFSQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "4.0", "review_text": "Like all the other reviews posted for this product, I've been impressed with the sound, functionality, and comfort the headset provides. Soft padding for the ears and the top of the head makes you forget you're wearing a headset, and the button commands for a quick mute, or to change songs, play songs, etc, are easy to map out and memorize once they're on your head. Unfortunately, after only 3-4 months of owning the product, the mic has come loose, and my party/call members are complaining of static through the mic. The mic is busted now, but the sound quality still lives; so no more calls for these headphones. 🙁 If you decide to get these, note that the reviews are accurate; I've been incredibly happy with the performance and comfort -- just, treat the mic real gently, or you might put it in an early grave.", "review_title": "Fragile Mic", "review_url": "https://www.amazon.com/gp/customer-reviews/R2KHAKAG2CRBU0/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ", "reviewed_date": "January 15, 2025", "reviewed_product_variant": "Color: White"}, {"author_name": "Jordan Baker", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AGM47O2TFY7TOLBNPQDWLI7HYBWQ/ref=cm_cr_dp_d_gw_pop?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I like the say on the low end of headsets because I do not want to spend $100-$200 in my opinion. These good great for gaming and they are builds with arguably good quality. For the price these are pretty good and I believe they have a multi switch so you can plug the usb like I did into your control and the smaller into your computer Vic Versa. Lastly just love the way they feel on my head and really comfortable at that as well. Sound quality is great and I can shake my head around and they won\u2019t come off. Has a wireless or wire mode is is a plus and also again everthing your getting at this price is probably one of the better headphones on Amazon you can buy at a reasonable good price .", "review_title": "Good Gaming Headset for the price", "review_url": "https://www.amazon.com/gp/customer-reviews/R35217UUCTC5SE/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ", "reviewed_date": "January 17, 2025", "reviewed_product_variant": "Color: White"}, {"author_name": "Roger Handt", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Das Headset ist stabil verarbeitet und es ist aufgrund des relativ geringen Gewichts sehr angenehm zu tragen. Ich habe relativ gro\u00dfe Ohren und deshalb Probleme, ein passendes Headset zu finden. Mit diesem habe ich keine Probleme. Zur technischen Seite: Die WiFi-Konnektivit\u00e4t funktioniert hervorragend, sowohl mit dem beiliegenden Adapter als auch per Bluetooth mit dem Smartphone gekoppelt. Das Noise-Canceling ist solide, der Kopfh\u00f6rer umschlie\u00dft die Ohren vollst\u00e4ndig und einigerma\u00dfen stramm, so werden Umgebungsger\u00e4usche eh schon gut ged\u00e4mpft. Die Akkulaufzeit hab ich noch nicht vollst\u00e4ndig ausgereizt, aber auch eine lange Gaming-Session \u00fcber hat der Akku bisher gut gehalten. Die Mikrofon-Qualit\u00e4t ist gem\u00e4\u00df meiner Mitspieler auch sehr solide. Wer ein g\u00fcnstiges Headset sucht, ist mit diesem Modell in jedem Fall gut beraten.", "review_title": "Sehr gute Preis/Leistung!", "review_url": null, "reviewed_date": "January 25, 2025", "reviewed_product_variant": "Color: White"}, {"author_name": "Mickael", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Ce casque OZeing est une vraie surprise ! La connexion 2.4 GHz en Wi-Fi est ultra stable, sans latence, ce qui est parfait pour le gaming. Le son est clair, bien \u00e9quilibr\u00e9, avec des basses immersives qui donnent une vraie profondeur aux jeux. Le micro est \u00e9galement de bonne qualit\u00e9, avec une voix nette et sans bruit parasite. C\u00f4t\u00e9 confort, rien \u00e0 redire : les coussinets sont doux et agr\u00e9ables m\u00eame apr\u00e8s plusieurs heures de jeu. Et l\u2019autonomie est excellente, ce qui \u00e9vite d\u2019avoir \u00e0 le recharger trop souvent. Bref, un excellent rapport qualit\u00e9-prix pour ceux qui cherchent un casque sans fil performant et abordable. Je recommande sans h\u00e9siter.", "review_title": "Excellent casque gaming sans fil !", "review_url": null, "reviewed_date": "January 15, 2025", "reviewed_product_variant": "Color: White"}, {"author_name": "Tina", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Dieses Headset hat mich wirklich \u00fcberzeugt und geh\u00f6rt definitiv zu den besten, die ich bisher genutzt habe. *Schnelle Lieferung*: Die Lieferung war unglaublich flott! Innerhalb k\u00fcrzester Zeit war das Headset bei mir, sicher verpackt und in einwandfreiem Zustand. So muss es sein! *Stabil und hochwertig*: Die Verarbeitung ist top. Das Headset f\u00fchlt sich sehr robust an und macht den Eindruck, dass es auch bei h\u00e4ufiger Nutzung lange h\u00e4lt. *Exzellente Klang- und Sprachqualit\u00e4t*: Der Sound ist ein echtes Highlight \u2013 detailliert, kraftvoll und perfekt abgestimmt. Egal ob f\u00fcr Gaming, Musik oder Filme, der Klang ist einfach fantastisch. Das Mikrofon liefert zudem eine klare \u00dcbertragung ohne St\u00f6rger\u00e4usche, was gerade beim Spielen mit Freunden super wichtig ist. *Modernes Design*: Das Headset sieht richtig gut aus! Es kombiniert ein modernes, ansprechendes Design mit hohem Tragekomfort. Selbst nach Stunden bleibt es bequem und angenehm zu tragen. Alles in allem bin ich mehr als zufrieden. Dieses Headset ist f\u00fcr jeden Gamer, der Wert auf Qualit\u00e4t und Design legt, eine ausgezeichnete Wahl. Von mir gibt es volle 5 Sterne!", "review_title": "Perfektes Gaming-Headset \u2013 klare Empfehlung!", "review_url": null, "reviewed_date": "December 11, 2024", "reviewed_product_variant": "Color: Black"}, {"author_name": "Nikkolos", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Au premier abord,j'ai voulu le renvoyer ,mais apr\u00e8s comparaison avec un jbl d' un prix plus \u00e9lev\u00e9e : r\u00e9sultat = y a pas photo ! c'est un super casque ! Compatible avec tout ( ma tv , console ps5/ps4, mon t\u00e9l\u00e9phone, d'une simplicit\u00e9 enfantine pour se connecter \u00e0 tout ses appareils. Le son est excellent, immersif et les basses profondes sans Pass\u00e9s au dessus des aigu\u00ebs et m\u00e9dium. Plage de fr\u00e9quences excellente je suis bluff\u00e9 ! Pour une utilisation domestique sur console, regarder un film sur tv et \u00e9couter la musique sur you tube par ex. C'est le Top ! J'ai des casques haut de gammes, Marshall, jbl , Bose ect....il a rien \u00e0 leurs envier ,ce casque est vraiment tr\u00e8s bon ! Ne sature pas lvl \u00e0 fond. N'h\u00e9sitez pas et l' \u00e9coutez !!! Vous serez pas d\u00e9\u00e7u et apr\u00e8s 10h00 d'\u00e9coute il fonctionne encore ! Qe recharge super vite(2 h00) mais en 10 min de charges vous avez d\u00e9j\u00e0 minimum 2 h00 d'\u00e9coute. J'ai v\u00e9rifi\u00e9 ! J'ai rajouter une mousse sur l'arceau de t\u00eate pour am\u00e9liorer son confort et il me fait pas mal aux oreilles ni \u00e0 la t\u00eate ! Le micro r\u00e9tractable est super bien bien pens\u00e9 et les boutons sont simples et intuitifs ( pas besoins d'un bac + 5 ) . On vois que c'est un casque consu par un des gamers, qui aime la qualit\u00e9 du son . Avec ps5 j'ai le son 3D Sony qui est excellent. ( sur ps5 tout les casques milieu de game sont compatible 3D) pas besoin du casque officiel c tjrs bon \u00e0 savoir. Bon jeu et bonne \u00e9coute surtout !", "review_title": "Rapport qualit\u00e9 prix g\u00e9niale", "review_url": null, "reviewed_date": "September 21, 2024", "reviewed_product_variant": "Color: Black"}, {"author_name": "Sandrine S", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Bon son, confortable, beau design, fonctionne en Bluetooth ou 2.4G avec cl\u00e9 USB. Tr\u00e8s bon rapport qualit\u00e9/ prix.", "review_title": "Tr\u00e8s bon casque gaming.", "review_url": null, "reviewed_date": "January 14, 2025", "reviewed_product_variant": "Color: Black"}] | [{"asin": "B0DJW2X8BX", "image_url": "https://m.media-amazon.com/images/I/41ofZctOgqL._AC_UF480,480_SR480,480_.jpg", "price": "$39.99", "product_name": "Wireless Gaming Headset for PS5, PS4, Elden Ring, PC, Mac, Switch, Bluetooth 5.3 Ga...", "rating": "5", "reviews": "534", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2MTMzMTYwNTIwMjo6Ojo&url=%2Fdp%2FB0DJW2X8BX%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0DJW2X8BX%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0D69Z3QR4", "image_url": "https://m.media-amazon.com/images/I/41Rjxnr8aUL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$32.99", "product_name": "3D Stereo Wireless Gaming Headset for PC, PS4, PS5, Mac, Switch, Mobile | Bluetooth...", "rating": "4", "reviews": "400", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY0Nzk1NzI0NjUwMjo6Ojo&url=%2Fdp%2FB0D69Z3QR4%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0D69Z3QR4%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B09TB15CTL", "image_url": "https://m.media-amazon.com/images/I/41o-o1sxliL._AC_UF480,480_SR480,480_.jpg", "price": "$16.99", "product_name": "Gaming Headset for PC, Ps4, Ps5, Xbox Headset with 7.1 Surround Sound, Gaming Headp...", "rating": "4", "reviews": "5,095", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ4NDU3MTU0NzcwMjo6Ojo&url=%2Fdp%2FB09TB15CTL%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB09TB15CTL%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ4NDU3MTU0NzcwMjo6Ojo&url=%2Fdp%2FB09TB15CTL%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB09TB15CTL%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0BFR75H2G", "image_url": "https://m.media-amazon.com/images/I/41LAVzxA7pL._AC_UF480,480_SR480,480_.jpg", "price": "$59.99", "product_name": "SOMIC G810 Wireless Headset 2.4G Low Latency Headset for PC PS4 PS5 Laptop, Bluetooth 5.2 Wireless Headphone with Built-in Mic, 50H Playtime, RGB Light Foldable for Gamer (Xbox Only Work in Wired)", "rating": "4", "reviews": "278", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE2MDI4MTQ2NjM5ODo6Ojo&url=%2Fdp%2FB0BFR75H2G%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0BFR75H2G%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0D3HV5M3Y", "image_url": "https://m.media-amazon.com/images/I/41MUVUXwcyL._AC_UF480,480_SR480,480_.jpg", "price": "$29.99", "product_name": "Wireless Gaming Headset for PC, PS4, PS5, Mac,Switch,2.4GHz USB Gaming Headset with...", "rating": "4", "reviews": "359", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2ODU1OTI5NDcwMjo6Ojo&url=%2Fdp%2FB0D3HV5M3Y%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0D3HV5M3Y%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0878W5F4X", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$21.99", "product_name": "Gaming Headset with Microphone for PC PS4 PS5 Headset Noise Cancelling Gaming Headphones for Laptop Mac Switch Xbox One Headset with LED Lights Deep Bass for Kids Adults Black Blue", "rating": "4", "reviews": "19,883", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU3NDUwNDg5ODYwMjo6Ojo&url=%2Fdp%2FB0878W5F4X%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0878W5F4X%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU3NDUwNDg5ODYwMjo6Ojo&url=%2Fdp%2FB0878W5F4X%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0878W5F4X%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0B4B2HW2N", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$33.99", "product_name": "2.4GHz Wireless Gaming Headset for PS5, PS4 Fortnite & Call of Duty/FPS Gamers, PC,...", "rating": "4", "reviews": "9,011", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDE0NjQ2NjYwMzcwMjo6Ojo&url=%2Fdp%2FB0B4B2HW2N%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0B4B2HW2N%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDE0NjQ2NjYwMzcwMjo6Ojo&url=%2Fdp%2FB0B4B2HW2N%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0B4B2HW2N%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0B4B2HW2N", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$33.99", "product_name": "2.4GHz Wireless Gaming Headset for PS5, PS4 Fortnite & Call of Duty/FPS Gamers, PC,...", "rating": "4", "reviews": "9,011", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDAxNDY0NjY2MDM3MDI6Ojo6&url=%2Fdp%2FB0B4B2HW2N%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0B4B2HW2N%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDAxNDY0NjY2MDM3MDI6Ojo6&url=%2Fdp%2FB0B4B2HW2N%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0B4B2HW2N%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0CLLJC6QC", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$39.99", "product_name": "Wireless Gaming Headset, 7.1 Surround Sound, 2.4Ghz USB Gaming Headphones with Blue...", "rating": "4", "reviews": "895", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDAyMDI2MDcxNTU0MDI6Ojo6&url=%2Fdp%2FB0CLLJC6QC%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0CLLJC6QC%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDAyMDI2MDcxNTU0MDI6Ojo6&url=%2Fdp%2FB0CLLJC6QC%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0CLLJC6QC%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B09JFZC7D6", "image_url": "https://m.media-amazon.com/images/I/41kn-1bwKKL._AC_UF480,480_SR480,480_.jpg", "price": "$29.99", "product_name": "Bluetooth Cat Ear Headphones for Kids, Wireless & Wired Mode Foldable Headset with ...", "rating": "4", "reviews": "604", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2NjYxMDQ4MTk3MDI6Ojo6&url=%2Fdp%2FB09JFZC7D6%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB09JFZC7D6%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0D3HV5M3Y", "image_url": "https://m.media-amazon.com/images/I/41MUVUXwcyL._AC_UF480,480_SR480,480_.jpg", "price": "$29.99", "product_name": "Wireless Gaming Headset for PC, PS4, PS5, Mac,Switch,2.4GHz USB Gaming Headset with...", "rating": "4", "reviews": "359", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2Njg1NTkyOTQ3MDI6Ojo6&url=%2Fdp%2FB0D3HV5M3Y%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0D3HV5M3Y%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0DJW2X8BX", "image_url": "https://m.media-amazon.com/images/I/41ofZctOgqL._AC_UF480,480_SR480,480_.jpg", "price": "$39.99", "product_name": "Wireless Gaming Headset for PS5, PS4, Elden Ring, PC, Mac, Switch, Bluetooth 5.3 Ga...", "rating": "5", "reviews": "534", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2NjEzMzE2MDUyMDI6Ojo6&url=%2Fdp%2FB0DJW2X8BX%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0DJW2X8BX%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0D69Z3QR4", "image_url": "https://m.media-amazon.com/images/I/41Rjxnr8aUL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$32.99", "product_name": "3D Stereo Wireless Gaming Headset for PC, PS4, PS5, Mac, Switch, Mobile | Bluetooth...", "rating": "4", "reviews": "400", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2NDc5NTcyNDY1MDI6Ojo6&url=%2Fdp%2FB0D69Z3QR4%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0D69Z3QR4%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0CNVHKVVL", "image_url": "https://m.media-amazon.com/images/I/41+mB9ThR+L._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$35.99", "product_name": "2.4GHz Wireless Gaming Headset with Wired Mode, 5.4 Bluetooth Gaming Headphones for...", "rating": "4", "reviews": "494", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2NjQ2NDQxODA0MDI6Ojo6&url=%2Fdp%2FB0CNVHKVVL%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0CNVHKVVL%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}] | [{"five_star": "77%", "four_star": "8%", "one_star": "7%", "three_star": "5%", "two_star": "3%"}] |
| https://www.amazon.com/SteelSeries-Arctis-Nova-1P-White/dp/B0B7X6PWMR/ref=sr_1_5?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-5&th=1 | B0B7X6PWMR | SteelSeries Arctis Nova 1P PS5 Headphones - Gaming Headset - 360° Space Sound - Memory Foam Ear Pads - Noise Cancelling Microphone - Also for PC, PS4, Switch, Xbox - White | SteelSeries | Amazon.com | - | 352 | [{"level": 1, "name": "Video Games", "url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"}, {"level": 2, "name": "PlayStation 4", "url": "/PlayStation-4-Games-Consoles-Accessories-Hardware/b/ref=dp_bc_aui_C_2?ie=UTF8&node=6427814011"}, {"level": 3, "name": "Accessories", "url": "/PlayStation-4-Hardware-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=6427815011"}, {"level": 4, "name": "Headsets", "url": "/PlayStation-4-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=6427826011"}] | 4.0 | USD | 83.79 | 83.79 | - | Almighty Audio — The custom-designed Nova acoustic system delivers best-in-class sound for gaming with High Fidelity Drivers. Completely customize your ideal sound experience with a professional-grade built-in video game parametric equalizer. - 360° SPACE SOUND - Immersive surround sound transports you into the gaming world, allowing you to hear every step, charge or voice cue to give you the edge. *Compatible with Tempest 3D Audio for PS5 / Microsoft Spatial Sound - Adjustable for a Perfect Fit - The ComfortMAX System includes rotatable, height-adjustable ear cups with AirWeave memory pad and an expandable band. The lightweight headset keeps you comfortable no matter how long you play. - Noise-Cancelling Mic - ClearCast Gen 2 reduces background noise by up to 25dB on any platform to give you crystal clear communications. Completely hide the mic in the earpiece for a more elegant look. - Multi-Platform Support - Easily connect to any game console, PlayStation, PC, Xbox, or Switch, with a 3.5mm jack. Also works great with mobile devices. | Almighty Audio has never been more accessible, as the Arctis Nova 1P combines hardware and software to deliver superior sound quality with high-fidelity drivers, immersive 360° spatial sound, and a 10-band parametric EQ for countless customizations. The ComfortMax system allows 4 adjustment points, easily finding a perfect fit on the lightweight helmet with AirWeave Memory Foam Pads. The professional-grade noise-cancelling mic reduces background noise, which ensures clear communication while you play and comfortable even during long gaming sessions. The Arctis Nova 1P features a 3.5mm jack that works with virtually any platform, including PlayStation, PC, Xbox, Switch and your mobile device. Easily adjust the volume and mute your voice with the controls on the headset. | In Stock | - | Arctis Nova 1P White | access_method: Wired, edition: Arctis Nova 1P White, platform_for_display: PC, PlayStation | Video Games > PlayStation 4 > Accessories > Headsets | [{"ASIN": "B0B7X6PWMR", "Age Range (Description)": "Adult", "Amazon Best Sellers Rank": "#20,806 in Video Games , #238 in PlayStation 4 Headsets , #298 in PlayStation 5 Headsets", "Audio Driver Type": "Dynamic Driver", "Cable Feature": "Without Cable", "Compatible Devices": "Cellphones, Gaming Consoles, Laptops, Desktops", "Connectivity Technology": "Wired", "Control Method": "Remote", "Control Type": "noise cancelling", "Country of Origin": "China", "Date First Available": "March 12, 2023", "Earpiece Shape": "over-ear", "Frequency Range": "20Hz - 20,000Hz", "Headphones Jack": "3.5 mm Jack", "Included Components": "Cable, Ear Cushions, Headband", "Is Autographed": "No", "Item Weight": "9.5 ounces", "Item model number": "Arctis Nova 1P White", "Language": "English", "Manufacturer": "SteelSeries", "Material": "Leather", "Model Name": "SteelSeries Arctis Nova 1P White", "Number of Items": "1", "Package Type": "Rigid packaging", "Product Dimensions": "3.43 x 6.89 x 7.48 inches", "Recommended Uses For Product": "Hunting Instinct", "Series Number": "1", "Specific Uses For Product": "Gaming", "Style": "Nova White for PlayStation", "Theme": "Video Game", "UPC": "657768613418", "Water Resistance Level": "Not Water Resistant", "Wireless Communication Technology": "Telephone"}] | [{"Brand": "SteelSeries", "Color": "White", "Ear Placement": "Over Ear", "Form Factor": "Circumauricular", "Noise Control": "Active Noise Cancellation"}] | https://m.media-amazon.com/images/I/61czC2G0+NL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/616gH-ueIYL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61WpgrSOKgL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/614cUP5fg-L._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61tdfqUb1zL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61z46+emekL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/611X5YNe6NL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/713716y2IyL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71WHn7XTr5L._AC_SL1500_.jpg | [{"access_method": "Wired", "asin": "B0B7X6PWMR"}, {"asin": "B0B7X6PWMR", "edition": "Arctis Nova 1P White"}, {"asin": "B0B7X6PWMR", "platform_for_display": "PC, PlayStation"}] | [{"access_method": ["Wired"], "edition": ["Arctis Nova 1P White"], "platform_for_display": ["PC, PlayStation"]}] | [{"link": "https://www.amazon.com/SteelSeries-Apex-RGB-Gaming-Keyboard/dp/B07ZGDPT4M/ref=pd_day0fbt_hardlines_d_sccl_1/136-0100575-5165336?pd_rd_w=ydCPA&content-id=amzn1.sym.06aea998-aa9c-454e-b467-b476407c7977&pf_rd_p=06aea998-aa9c-454e-b467-b476407c7977&pf_rd_r=3KKGC4TCWSZ3S47PSWC3&pd_rd_wg=SEDPc&pd_rd_r=ac78a567-1eb0-40fa-b9df-35ce45746884&pd_rd_i=B07ZGDPT4M&psc=1", "price": "$39.99", "title": "SteelSeries Apex 3 RGB Gaming Keyboard \u2013 10-Zone RGB Illumination \u2013 IP32 Water Resistant \u2013 Premium Magnetic Wrist Rest (Whisper Quiet Gaming Switch)"}, {"link": "https://www.amazon.com/SteelSeries-Arctis-Multi-Platform-Gaming-Mobile-Headset/dp/B0B8QP5BGD/ref=pd_day0fbt_hardlines_d_sccl_2/136-0100575-5165336?pd_rd_w=ydCPA&content-id=amzn1.sym.06aea998-aa9c-454e-b467-b476407c7977&pf_rd_p=06aea998-aa9c-454e-b467-b476407c7977&pf_rd_r=3KKGC4TCWSZ3S47PSWC3&pd_rd_wg=SEDPc&pd_rd_r=ac78a567-1eb0-40fa-b9df-35ce45746884&pd_rd_i=B0B8QP5BGD&psc=1", "price": "$135.99", "title": "SteelSeries Arctis Nova 7X Wireless Multi-Platform Gaming Headset \u2014 Neodymium Magnetic Drivers \u2014 2.4GHz+Bluetooth \u2014 38Hr USB-C Battery \u2014 AI Mic \u2014 Xbox Series X|S, PC, PS5, Switch, VR, Mobile - Black"}] | [{"author_name": "Elizabeth R Webster", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AG46C2OEIF6OY7KIISCENS7S5QSA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "4.0", "review_text": "Had to buy a seperate cord splitter so the headphones could be used for my computer. Maybe this is something they could offer as an option in the packaging in the future. After buying the splitter, it works great now", "review_title": "nice! minimalist", "review_url": "https://www.amazon.com/gp/customer-reviews/R3KORH5B293ITL/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0B7X6PWMR", "reviewed_date": "January 31, 2025", "reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"}, {"author_name": "HOMMEL Fr\u00e9d\u00e9ric", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Le son est g\u00e9nial, le confort \u00e9galement, utilis\u00e9 sur PS5, j'ai juste acheter un adaptateur pour pouvoir l'utiliser aussi sur mon PC.", "review_title": "Le casque qu'il faut pour PS5", "review_url": null, "reviewed_date": "December 15, 2024", "reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"}, {"author_name": "steven", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Pure quality, comfort and sound . Highly recommend", "review_title": "Great headset for PS5", "review_url": null, "reviewed_date": "December 26, 2024", "reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"}, {"author_name": "Luca Massironi", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "le ha usate per tantissimo tempo soprattutto per giocare alla Play e mi sono sempre trovato benissimo, vendute solo per passaggio a modello ma dopo due anni erano ancora pulite e intatte", "review_title": "comode e leggere", "review_url": null, "reviewed_date": "December 06, 2024", "reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"}, {"author_name": "Kati", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Super sond ,ein klarer Klang ,einfach zu bedienen kurz gesagt es ist sein Geld werd", "review_title": "1+ mit sternchen", "review_url": null, "reviewed_date": "August 19, 2024", "reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"}, {"author_name": "Cliente Amazon", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Este tipo de auriculares me gustan mucho porque pesan poco y son muy c\u00f3modos con la esponjita esta que viene. Adem\u00e1s se escuchan muy bien, los volver\u00eda a comprar sin duda.", "review_title": "Muy buenos", "review_url": null, "reviewed_date": "June 02, 2024", "reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"}] | [{"asin": "B0B8Q9FGMD", "image_url": "https://m.media-amazon.com/images/I/41gPS37DbpL._AC_UF480,480_SR480,480_.jpg", "price": "$175.99", "product_name": "SteelSeries Arctis Nova 7P Wireless Multi-Platform Gaming Headset \u2014 Neodymium Magnetic Drivers \u2014 2.4GHz + Bluetooth \u2014 38Hr USB-C Battery \u2014 Gen2 AI Mic \u2014 PlayStation, PC, Switch, VR, Mobile - Black", "rating": "4", "reviews": "5,892", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDExNDg4MzcyODg5ODo6Ojo&url=%2Fdp%2FB0B8Q9FGMD%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0B8Q9FGMD%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B01H6GUCCQ", "image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$19.99", "product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo", "rating": "4", "reviews": "108,513", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UU"}, {"asin": "B0DJW2X8BX", "image_url": "https://m.media-amazon.com/images/I/41ofZctOgqL._AC_UF480,480_SR480,480_.jpg", "price": "$39.99", "product_name": "Wireless Gaming Headset for PS5, PS4, Elden Ring, PC, Mac, Switch, Bluetooth 5.3 Ga...", "rating": "5", "reviews": "534", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2MTM1NTkxMjkwMjo6Ojo&url=%2Fdp%2FB0DJW2X8BX%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0DJW2X8BX%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0D3V4HZJV", "image_url": "https://m.media-amazon.com/images/I/31upse7J5HL._AC_UF480,480_SR480,480_.jpg", "price": "$19.99", "product_name": "CM7002 Gaming Headset for PS5, PS4, PC, Mac, Switch, Xbox Series, Surround Sound RG...", "rating": "4", "reviews": "1,374", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ5NTY5MTQ1NDUwMjo6Ojo&url=%2Fdp%2FB0D3V4HZJV%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0D3V4HZJV%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B09ZW52XSQ", "image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$212.95", "product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360\u00b0 Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch", "rating": "4", "reviews": "1,280", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B09ZWKD9TF", "image_url": "https://m.media-amazon.com/images/I/312MvjLsRXL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$306.99", "product_name": "SteelSeries Arctis Nova Pro Wireless Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Active Noise Cancellation Infinity Power System - Stealth Mic - Xbox, PC, PS5, PS4, Switch, Mobile", "rating": "4", "reviews": "5,928", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA1OTIyNzIxMDE5ODo6Ojo&url=%2Fdp%2FB09ZWKD9TF%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB09ZWKD9TF%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B08BTHXJFN", "image_url": "https://m.media-amazon.com/images/I/2129YqrQiuL._AC_UF480,480_SR480,480_.jpg", "price": "$72.82", "product_name": "HyperX HHSS1C-KB-WT/G Cloud Stinger Core \u2013 Wireless Gaming Headset, for PS4, PS5, PC, Lightweight, Durable Steel Sliders, Noise-Cancelling Microphone - White", "rating": "4", "reviews": "8,533", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDI5MTIzNDkyMjQwMjo6Ojo&url=%2Fdp%2FB08BTHXJFN%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB08BTHXJFN%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0DB7ZW7J4", "image_url": "https://m.media-amazon.com/images/I/41CcIOb-fOL._AC_UF480,480_SR480,480_.jpg", "price": "$279.99", "product_name": "Logitech G Astro A50 Omni-Platform Wireless Gaming Headset + Base Station for PS5, Xbox, PC: PLAYSYNC Audio Switcher, <16 bit/48kHz (Console), <24 bit/48 kHz (PC), 24hr Battery, 2.4GHz & BT - Black", "rating": "4", "reviews": "633", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1MDY5ODk2MDAxMDI6Ojo6&url=%2Fdp%2FB0DB7ZW7J4%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0DB7ZW7J4%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0D3XMVS73", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$26.99", "product_name": "Wireless Gaming Headset for PC, PS5, PS4, Mac, Nintendo Switch, Gaming Headphones w...", "rating": "4", "reviews": "1,182", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1OTIwOTEwMTc0MDI6Ojo6&url=%2Fdp%2FB0D3XMVS73%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0D3XMVS73%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1OTIwOTEwMTc0MDI6Ojo6&url=%2Fdp%2FB0D3XMVS73%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0D3XMVS73%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0B7V128P9", "image_url": "https://m.media-amazon.com/images/I/31QbTaOMqiL._AC_UF480,480_SR480,480_.jpg", "price": "$119.99", "product_name": "Turtle Beach Stealth 600 Gen 2 MAX Wireless Amplified Multiplatform Gaming Headset for PS5, PS4, Nintendo Switch, PC & Mac with 48+ Hour Battery, Lag-free Wireless, & 50mm Speakers \u2013 Black", "rating": "4", "reviews": "2,425", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAyOTc0MDkzMzYxMDI6Ojo6&url=%2Fdp%2FB0B7V128P9%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0B7V128P9%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B07JYRWJ4G", "image_url": "https://m.media-amazon.com/images/I/41M5uTQidfL._AC_UF480,480_SR480,480_.jpg", "price": "$9.80", "product_name": "NewFantasia Replacement Audio Cable Compatible with SteelSeries Arctis 3, Arctis Prime, Arctis 5, Arctis 7, Arctis Pro Gaming Headset 1.3meters/4.3feet", "rating": "4", "reviews": "2,348", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwMDk1MzQ3Nzk3NTE6Ojo6&url=%2Fdp%2FB07JYRWJ4G%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB07JYRWJ4G%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B09ZW52XSQ", "image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$212.95", "product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360\u00b0 Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch", "rating": "4", "reviews": "1,280", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwNTk1NTU5MTM4OTg6Ojo6&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0B15QM5LL", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$153.99", "product_name": "SteelSeries Arctis Nova 7 Wireless Multi-Platform Gaming Headset \u2014 Neodymium Magnetic Drivers \u2014 2.4GHz + Mixable Bluetooth \u2014 38Hr USB-C Battery \u2014 ClearCast Gen2 AI Mic \u2014 PC, PS5, Switch, VR, Mobile", "rating": "4", "reviews": "5,892", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAxMTMzMjYzMjc0OTg6Ojo6&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAxMTMzMjYzMjc0OTg6Ojo6&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B09ZWKD9TF", "image_url": "https://m.media-amazon.com/images/I/312MvjLsRXL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$306.99", "product_name": "SteelSeries Arctis Nova Pro Wireless Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Active Noise Cancellation Infinity Power System - Stealth Mic - Xbox, PC, PS5, PS4, Switch, Mobile", "rating": "4", "reviews": "5,928", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwNTkyMjcyMTAxOTg6Ojo6&url=%2Fdp%2FB09ZWKD9TF%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB09ZWKD9TF%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}] | [{"five_star": "57%", "four_star": "17%", "one_star": "13%", "three_star": "7%", "two_star": "5%"}] |
| https://www.amazon.com/Razer-BlackShark-V2-Gaming-Headset/dp/B086PKMZ21/ref=sr_1_4?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-4&th=1 | B086PKMZ21 | Razer BlackShark V2 X Gaming Headset: 7.1 Surround Sound - 50mm Drivers - Memory Foam Cushion - For PC, PS4, PS5, Switch - 3.5mm Audio Jack - Black | Razer | Amazon.com | - | 20,701 | [{"level": 1, "name": "Video Games", "url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"}, {"level": 2, "name": "PC", "url": "/PC-Games/b/ref=dp_bc_aui_C_2?ie=UTF8&node=229575"}, {"level": 3, "name": "Accessories", "url": "/PC-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=318813011"}, {"level": 4, "name": "Headsets", "url": "/PC-Game-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=402053011"}] | 4.4 | USD | 39.99 | 59.99 | - | ADVANCED PASSIVE NOISE CANCELLATION — sturdy closed earcups fully cover ears to prevent noise from leaking into the headset, with its cushions providing a closer seal for more sound isolation. - 7.1 SURROUND SOUND FOR POSITIONAL AUDIO — Outfitted with custom-tuned 50 mm drivers, capable of software-enabled surround sound. *Only available on Windows 10 64-bit - TRIFORCE TITANIUM 50MM HIGH-END SOUND DRIVERS — With titanium-coated diaphragms for added clarity, our new, cutting-edge proprietary design divides the driver into 3 parts for the individual tuning of highs, mids, and lowsproducing brighter, clearer audio with richer highs and more powerful lows - LIGHTWEIGHT DESIGN WITH BREATHABLE FOAM EAR CUSHIONS — At just 240g, the BlackShark V2X is engineered from the ground up for maximum comfort - RAZER HYPERCLEAR CARDIOID MIC — Improved pickup pattern ensures more voice and less noise as it tapers off towards the mic’s back and sides - CROSS-PLATFORM COMPATIBILITY — Works with PC, Mac, PS4, Xbox One, Nintendo Switch via 3.5mm jack, enjoy unfair audio advantage across almost every platform. *Xbox One stereo adapter may be required, purchase separately - #1 SELLING PC GAMING PERIPHERALS BRAND IN THE U.S. — Source — Circana, Retail Tracking Service, U.S., Dollar Sales, Gaming Designed Mice, Keyboards, and PC Headsets, Jan. 2019- Dec. 2023 combined | Embrace the sound of esports with the Razer BlackShark V2 X-a triple threat of amazing audio, superior mic clarity and supreme sound isolation. With our best headset mic and audio drivers packed into a unique aviation-style headset, your competitive play is destined to turn pro. | In Stock | - | RZ04-03240100-R3U1 | size: 3.5mm, color: Black, style: PC | Video Games > PC > Accessories > Headsets | [{"ASIN": "B086PKMZ21", "Age Range (Description)": "Adult", "Amazon Best Sellers Rank": "#78 in Video Games , #6 in PC Game Headsets", "Audio Driver Size": "50 Millimeters", "Audio Driver Type": "Dynamic Driver", "Cable Feature": "Retractable", "Carrying Case Color": "Black or gray", "Compatible Devices": "PlayStation 4, Switch, Laptops, Desktops, Mac", "Connectivity Technology": "Wired", "Control Method": "Remote", "Control Type": "Noise Control", "Country of Origin": "China", "Date First Available": "July 30, 2020", "Earpiece Shape": "Over-ear with oval cushions", "Frequency Range": "100 Hz - 10 kHz", "Frequency Response": "28 KHz", "Headphones Jack": "3.5 mm Jack", "Included Components": "Important Product Information Guide, Audio/mic splitter extension cable, Razer BlackShark V2 X", "Is Autographed": "No", "Item Weight": "1.2 pounds", "Item model number": "RZ04-03240100-R3U1", "Manufacturer": "Razer", "Material": "Titanium, Memory Foam", "Model Name": "BlackShark V2 X", "Noise Control": "Sound Isolation", "Number of Items": "1", "Package Type": "Standard Packaging", "Product Dimensions": "7.6 x 6.76 x 3.86 inches", "Recommended Uses For Product": "Gaming", "Sensitivity": "100 dB", "Specific Uses For Product": "Personal, Gaming", "Style": "PC", "Theme": "Video Game", "UPC": "811659037572", "Unit Count": "1.0 Count", "Water Resistance Level": "Not Water Resistant", "Wireless Communication Technology": "Bluetooth"}] | [{"Brand": "Razer", "Color": "Black", "Ear Placement": "Over Ear", "Form Factor": "Over Ear", "Impedance": "32 Ohm"}] | https://m.media-amazon.com/images/I/51FRJHB7XOL._AC_SL1001_.jpg, https://m.media-amazon.com/images/I/61YIiVcTxzL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61b4IyVq4GL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61tpG4baChL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71DONh6d2aL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71kyUi6dtfL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71DgjgWcCTL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71++Y1XWs2L._AC_SL1500_.jpg | [{"asin": "B0CXGTGPZQ", "size_name": "3.5mm"}, {"asin": "B0CXH14PPD", "size_name": "3.5mm"}, {"asin": "B0B7KKD78B", "size_name": "USB"}, {"asin": "B09PZG4R17", "size_name": "3.5mm"}, {"asin": "B086PKMZ21", "size_name": "3.5mm"}, {"asin": "B09CLWQ45V", "size_name": "3.5mm"}, {"asin": "B0BFJS31G8", "size_name": "3.5mm"}, {"asin": "B0CXGTGPZQ", "color_name": "Classic Black"}, {"asin": "B0CXH14PPD", "color_name": "Classic Black"}, {"asin": "B0B7KKD78B", "color_name": "Black"}, {"asin": "B09PZG4R17", "color_name": "White"}, {"asin": "B086PKMZ21", "color_name": "Black"}, {"asin": "B09CLWQ45V", "color_name": "Green"}, {"asin": "B0BFJS31G8", "color_name": "Quartz Pink"}, {"asin": "B0CXGTGPZQ", "style_name": "Xbox"}, {"asin": "B0CXH14PPD", "style_name": "PlayStation"}, {"asin": "B0B7KKD78B", "style_name": "PC"}, {"asin": "B09PZG4R17", "style_name": "PC"}, {"asin": "B086PKMZ21", "style_name": "PC"}, {"asin": "B09CLWQ45V", "style_name": "PC"}, {"asin": "B0BFJS31G8", "style_name": "PC"}] | [{"color_name": ["Black", "Classic Black", "Green", "Quartz Pink", "White"], "size_name": ["3.5mm", "USB"], "style_name": ["PlayStation", "Xbox", "PC"]}] | [{"link": "https://www.amazon.com/Razer-DeathAdder-Essential-Gaming-Mouse/dp/B094PS5RZQ/ref=pd_bxgy_d_sccl_1/145-8288250-4808110?pd_rd_w=zICGu&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=G7TM5EQGRGESEZ1GWYQY&pd_rd_wg=5UENK&pd_rd_r=4f8fd24c-0296-4b05-b4a7-dea7015779fe&pd_rd_i=B094PS5RZQ&psc=1", "price": "$24.82", "title": "Razer DeathAdder Essential Gaming Mouse: 6400 DPI Optical Sensor - 5 Programmable Buttons - Mechanical Switches - Rubber Side Grips - Classic Black"}, {"link": "https://www.amazon.com/Razer-Ornata-Gaming-Keyboard-Low-Profile/dp/B09X6GJ691/ref=pd_bxgy_d_sccl_2/145-8288250-4808110?pd_rd_w=zICGu&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=G7TM5EQGRGESEZ1GWYQY&pd_rd_wg=5UENK&pd_rd_r=4f8fd24c-0296-4b05-b4a7-dea7015779fe&pd_rd_i=B09X6GJ691&psc=1", "price": "$34.98", "title": "Razer Ornata V3 X Gaming Keyboard: Low Profile Keys - Silent Membrane Switches - Spill Resistant - Chroma RGB Lighting - Ergonomic Wrist Rest - Snap Tap"}] | [{"author_name": "Justin O", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFHWT2JADKRVSGR2KBL7JGJIVQ6A/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "For what it costs, I had relatively low expectations of this headset. I came from a Corsair Virtuoso SE wireless headset that had a great mic and very good sound, but the connection with my PS4 was never very solid and I would notice relatively frequent dropouts in audio. Friends with PS4s swore by using the 3.5mm jack on the controller and I decided to use this to test. Build Quality When you pick up the headset the first thing you notice is just how light it is. It feels somewhat solid, but also it's clear that this is not a headset that prioritized premium materials. It's also extremely comfortable because of how light it is. Although I've never had issues with heavier headsets and neck pain, if that is a consideration the light materials should be great for long term sessions. The pads are faux leather on the interior ring and exterior ring. The part that rests against your head feels like something a little more breathable. I don't think I will have any issues wearing these for long sessions. The clamping force is a good moderate level where they won't fall off accidentally, but I don't feel like I am in a death grip. Mic Quality I made some calls using the mic and, I believe this to be a great compliment to the quality of the mic, no one thought I was on a headset. \"It's like you were actually talking through your phone.\" Although they have a gamer vibe, I could definitely see using these on conference calls (as long as the video was off.) Basically, the mic is great. Audio Quality Here's where I was expecting things to fall apart, but they really didn't. I decided to make a completely unfair comparison between these and my pair of Sennheiser HD600s run off of an AudioQuest DragonFly Black DAC/AMP. There was clearly no contest between the two headphones in terms of vocals or detail retrieval, but the Razer wasn't a bad headphone by any means. It had a clear and present bass, without being muddy. I do feel like the Corsair Virtuoso had a more full sound, but the spotty connection ruined it. Gaming tends to be, I think, more forgiving than listening to music ... so I ran through a couple of games as a test. I tried a game that I feel focuses on background music (Unravel), which sounded great. I also tried something with more exploding (Borderlands 3) and the headset felt equally competent. Flaws (But Not Deal Breakers) The volume knob goes the opposite of the way my mind treats every other volume knob in my life. Clockwise turns the sound down?! WHY?! I would have loved an LED to remind me that I'm muted. My first attempted call failed because the mute was engaged. Conclusion The Razer Blackshark V2 X might have a terrible name, but it's an amazing product at the price point. I don't play as many games online as I used to and I listen to a lot more music. For me, it makes sense to have a great pair of headphones for music and solo play as well as a cheap headset for online play with friends and conference calls. This works for me.", "review_title": "A (Really) Great Entry Level Wired Headset", "review_url": "https://www.amazon.com/gp/customer-reviews/R2NOY9XYZJ5N5D/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21", "reviewed_date": "August 04, 2020", "reviewed_product_variant": "Color: Black | Size: 3.5mm | Style: PC"}, {"author_name": "Kill.dmg", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AG3HBBVG5XL4CTGZZOQR4FEUVVCA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "The best cheap headphone you can get. The 7.1 is perfect for gaming. Turned up high I can hear close footsteps exactly where they are on the map when players use ninja on bo6. They are extremely comfortable, the memory foam is great. They are very light perfect for long gaming. The noise cancellation is very good. mic could be better. The bass isn't the best. But overall the quality of sound is very good.", "review_title": "best cheap headphones on earth.", "review_url": "https://www.amazon.com/gp/customer-reviews/R18AU6RQTVH2D1/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21", "reviewed_date": "February 06, 2025", "reviewed_product_variant": "Color: Black | Size: 3.5mm | Style: PC"}, {"author_name": "ObtuseAglet", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AGPWYAA3XMVVCZIBF3PH7P5EPJIQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "As a person who plays video games and has pets and a small child I eat through my fair share of headsets. This headset not only gives me hope that it might outlast the others in its price category (sub-$100) but that it might be one of the best quality ones in the category too. Two things stand out about the headset: 1. Build quality is above average for this price. I am unsure of if this is because this is a cheaper version of a more expensive headset from Razer, or if they are just good at building them, but these don't feel flimsy, and they don't sound flimsy either. This leads to point 2. Sound Quality is comparable to most $100-120 headsets I've used. Digital surround has come a long way since it's debut, and it's easy to forget that these headphones don't feature multiple speakers on each side. Beyond that the microphone provides crisp, quiet audio comparable to that of a Shure SM58. When run through even a middling on board audio card on a desktop, there shouldn't be much of an audible difference between your microphone and those that others spent 4-5x the amount that you did. The physical knob for volume is an exceptional touch at this price, and honestly makes the headset so much more usable than on that requires pressing small buttons to change volume on. As the headset is wired you can use the volume knob on the headset to find tune the volume from your computer (which ideally you set at ~70% and then use the headset to set to the volume you truly want, this gives the best experience). I love these and I would love to get my hands on a pair of the Pro version to see just how much more incredible goodness Razer has crammed into them.", "review_title": "Probably The Best Sub $100 Headset", "review_url": "https://www.amazon.com/gp/customer-reviews/RZ36G7R5TENOL/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21", "reviewed_date": "January 29, 2025", "reviewed_product_variant": "Color: Green | Size: 3.5mm | Style: PC"}, {"author_name": "alex", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFRJKMYCFL5RIEDCX2J3LQH5XO2Q/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "4.0", "review_text": "the headset is good and all the cushion part is nice and soft but it\u2019s a little small on me as well as you others u are playing with can hear a little noise in the background but everything else is good headset is really loud when all the way up", "review_title": "good except one thing", "review_url": "https://www.amazon.com/gp/customer-reviews/RHQAF9KQSVV7Z/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21", "reviewed_date": "January 20, 2025", "reviewed_product_variant": "Color: White | Size: 3.5mm | Style: PC"}, {"author_name": "Amazon Customer", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEXGGJIPPH7VDBPXNOWO4ORMSYFQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I recently picked up a set of headphones for my Xbox, and I couldn\u2019t be happier with the purchase. From the second I put them on, I could tell they were built to last. The construction is top-notch, with a solid yet comfortable design that feels durable without being too heavy. The ear cushions are super soft, making long gaming sessions feel effortless. When it comes to sound quality, these headphones truly shine. The audio is crystal clear, with deep, immersive bass and crisp highs that make every game feel more lifelike. It could be the subtle footsteps of an enemy in a shooter or the booming soundtrack of an open-world adventure, the sound is perfectly balanced and incredibly detailed. The surround sound effect is spot on, giving me a competitive edge in multiplayer games by making it easy to pinpoint enemy locations. The microphone is another highlight\u2014my teammates hear me loud and clear without any distortion or background noise interference, with zero lag or dropouts, making the experience completely seamless. Overall, these headphones are a solid set for gaming. With their high-quality build, excellent comfort, and outstanding sound performance, they are easily one of the best gaming accessories I\u2019ve ever owned. Highly recommended!", "review_title": "Outstanding Headphones", "review_url": "https://www.amazon.com/gp/customer-reviews/R2EYMTGMPDDA2W/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21", "reviewed_date": "February 03, 2025", "reviewed_product_variant": "Color: Classic Black | Size: 3.5mm | Style: Xbox"}, {"author_name": "Emiliano Arce", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Me gust\u00f3 mucho que su audio tiene buenos bajos y tonos fuertes para los que nos gusta escuchar m\u00fasica a alto volumen y tambi\u00e9n para juegos obviamente, Respecto al dise\u00f1o son muy c\u00f3modos y ligeros que al paso del tiempo olvidas que est\u00e1n ah\u00ed adem\u00e1s que en la caja de incluye pegatinas y una bolsa para transportarlos, Recomendados\ud83d\udc4d", "review_title": "C\u00f3modos y ligeros, excelente audio", "review_url": null, "reviewed_date": "January 22, 2025", "reviewed_product_variant": "Color: White | Size: 3.5mm | Style: PC"}, {"author_name": "David leal", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Baratos, lleg\u00f3 a tiempo y sonido incre\u00edble, se siente de un material muy resistente, buenas alfombras y buen colch\u00f3n de la diadema Hab\u00eda escuchado rese\u00f1as de que no se escuchaba cuando se hac\u00edan llamadas por Xbox, pero a mi s\u00ed me sirvi\u00f3, ahora me escucho mejor con ese micr\u00f3fono de los aud\u00edfonos", "review_title": "Incre\u00edble y s\u00ed se escucha el micro en Xbox", "review_url": null, "reviewed_date": "December 30, 2024", "reviewed_product_variant": "Color: Green | Size: 3.5mm | Style: PC"}, {"author_name": "Max", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Excelente bien empaquetado y la entrega fue r\u00e1pida", "review_title": "Black Shark Xbox", "review_url": null, "reviewed_date": "December 29, 2024", "reviewed_product_variant": "Color: Classic Black | Size: 3.5mm | Style: Xbox"}, {"author_name": "Mikel", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "El producto es c\u00f3modo, no esa y se siente resistente, de muy buena calidad! Es hermoso. Se escucha bien y el micr\u00f3fono es bueno. Lo uso para mi Xbox", "review_title": "10 de 10", "review_url": null, "reviewed_date": "December 15, 2024", "reviewed_product_variant": "Color: Quartz Pink | Size: 3.5mm | Style: PC"}, {"author_name": "cristina", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "El producto lleg\u00f3 en excelente condiciones y funciona muy bien", "review_title": "Lo recomiendo", "review_url": null, "reviewed_date": "December 12, 2024", "reviewed_product_variant": "Color: Black | Size: USB | Style: PC"}] | [{"asin": "B09ZW52XSQ", "image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$212.95", "product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360\u00b0 Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch", "rating": "4", "reviews": "1,280", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0BY1HQBSX", "image_url": "https://m.media-amazon.com/images/I/41rBaCbsqtL._AC_UF480,480_SR480,480_.jpg", "price": "$179.99", "product_name": "Razer BlackShark V2 Pro Wireless Gaming Headset 2023 Edition: Detachable Mic - Pro-Tuned FPS Profiles - 50mm Drivers - Noise-Isolating Earcups w/Ultra-Soft Memory Foam - 70 Hr Battery Life - White", "rating": "4", "reviews": "11,324", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2MzUxNTQyOTkwMjo6Ojo&url=%2Fdp%2FB0BY1HQBSX%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0BY1HQBSX%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B07QNZC9V5", "image_url": "https://m.media-amazon.com/images/I/419PSmh-1yL._AC_UF480,480_SR480,480_.jpg", "price": "$89.95", "product_name": "Razer Kraken Gaming Headset: Lightweight Aluminum Frame - Retractable Noise Isolating Microphone - for PC, PS4, PS5, Switch, Xbox One, Xbox Series X & S, Mobile - 3.5 mm Headphone Jack - Black/Blue", "rating": "4", "reviews": "48,125", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU2NjQ2MzEzOTUwMjo6Ojo&url=%2Fdp%2FB07QNZC9V5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB07QNZC9V5%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0CW34HBKZ", "image_url": "https://m.media-amazon.com/images/I/41tkhLYy1mL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$69.99", "product_name": "Logitech G Pro X SE Wired Gaming Headset: Blue VO!CE Detachable Boom Mic, DTS 7.1, 50 mm Drivers, USB/3.5mm Aux, USB DAC Included, for PC, Xbox, PS5, PS4 - Black - G Pro X SE Wired Gaming Headset", "rating": "4", "reviews": "6,729", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDM1Mjk5NjU0NTgwMjo6Ojo&url=%2Fdp%2FB0CW34HBKZ%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0CW34HBKZ%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0B15QM5LL", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$153.99", "product_name": "SteelSeries Arctis Nova 7 Wireless Multi-Platform Gaming Headset \u2014 Neodymium Magnetic Drivers \u2014 2.4GHz + Mixable Bluetooth \u2014 38Hr USB-C Battery \u2014 ClearCast Gen2 AI Mic \u2014 PC, PS5, Switch, VR, Mobile", "rating": "4", "reviews": "5,892", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDExMzMyNjMyNzQ5ODo6Ojo&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDExMzMyNjMyNzQ5ODo6Ojo&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0DDKK2R3C", "image_url": "https://m.media-amazon.com/images/I/41xz798fVLL._AC_UF480,480_SR480,480_.jpg", "price": "$33.99", "product_name": "SENZER SG600 Pro Wireless Gaming Headset with Microphone - 7.1 Surround Sound, Noise Canceling Mic, 2.4GHz Wireless & Bluetooth 5.3 - Foldable Gaming Headphones for PC PS5 PS4 (Not Xbox Compatible)", "rating": "4", "reviews": "481", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU4NzQ3NDMwMTEwMjo6Ojo&url=%2Fdp%2FB0DDKK2R3C%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0DDKK2R3C%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B01H6GUCCQ", "image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$19.99", "product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo", "rating": "4", "reviews": "108,513", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UU"}, {"asin": "B0C1NT9W9K", "image_url": "https://m.media-amazon.com/images/I/412vPN0VcdL._AC_UF480,480_SR480,480_.jpg", "price": "$17.99", "product_name": "USB Headset with Microphone for PC Laptop - Wired Computer Headphones with Noise Ca...", "rating": "4", "reviews": "655", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDA0MjM0ODgwNzkwMDI6Ojo6&url=%2Fdp%2FB0C1NT9W9K%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0C1NT9W9K%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B09ZWKD9TF", "image_url": "https://m.media-amazon.com/images/I/312MvjLsRXL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$306.99", "product_name": "SteelSeries Arctis Nova Pro Wireless Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Active Noise Cancellation Infinity Power System - Stealth Mic - Xbox, PC, PS5, PS4, Switch, Mobile", "rating": "4", "reviews": "5,928", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjoyMDAwNTkyMjcyMTAxOTg6Ojo6&url=%2Fdp%2FB09ZWKD9TF%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB09ZWKD9TF%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0D3XMVS73", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$26.99", "product_name": "Wireless Gaming Headset for PC, PS5, PS4, Mac, Nintendo Switch, Gaming Headphones w...", "rating": "4", "reviews": "1,182", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDA1ODc3NTIwMDY0MDI6Ojo6&url=%2Fdp%2FB0D3XMVS73%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0D3XMVS73%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDA1ODc3NTIwMDY0MDI6Ojo6&url=%2Fdp%2FB0D3XMVS73%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0D3XMVS73%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0D4QVXY78", "image_url": "https://m.media-amazon.com/images/I/31IcWSpdOAL._AC_UF480,480_SR480,480_.jpg", "price": "$79.99", "product_name": "OXS Storm G2 Wireless Gaming Headsets, 7.1 Virtual Surround Sound, 3 EQ Modes, 2.4G Low Latency, 50mm Driver, 40H Playtime, RGB Light, Bluetooth 5.3, Compatible with PC, Console, Mobile, Black", "rating": "4", "reviews": "74", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDAyODk4MjgxNzcyMDI6Ojo6&url=%2Fdp%2FB0D4QVXY78%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0D4QVXY78%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B09ZW52XSQ", "image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$212.95", "product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360\u00b0 Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch", "rating": "4", "reviews": "1,280", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjoyMDAwNTk1NTU5MTM4OTg6Ojo6&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0BY1HQBSX", "image_url": "https://m.media-amazon.com/images/I/41rBaCbsqtL._AC_UF480,480_SR480,480_.jpg", "price": "$179.99", "product_name": "Razer BlackShark V2 Pro Wireless Gaming Headset 2023 Edition: Detachable Mic - Pro-Tuned FPS Profiles - 50mm Drivers - Noise-Isolating Earcups w/Ultra-Soft Memory Foam - 70 Hr Battery Life - White", "rating": "4", "reviews": "11,324", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDA2NjM1MTU0Mjk5MDI6Ojo6&url=%2Fdp%2FB0BY1HQBSX%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0BY1HQBSX%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0B15QM5LL", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$153.99", "product_name": "SteelSeries Arctis Nova 7 Wireless Multi-Platform Gaming Headset \u2014 Neodymium Magnetic Drivers \u2014 2.4GHz + Mixable Bluetooth \u2014 38Hr USB-C Battery \u2014 ClearCast Gen2 AI Mic \u2014 PC, PS5, Switch, VR, Mobile", "rating": "4", "reviews": "5,892", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjoyMDAxMTMzMjYzMjc0OTg6Ojo6&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjoyMDAxMTMzMjYzMjc0OTg6Ojo6&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}] | [{"five_star": "72%", "four_star": "14%", "one_star": "6%", "three_star": "5%", "two_star": "3%"}] |
| https://www.amazon.com/BENGOO-G9000-Controller-Cancelling-Headphones/dp/B01H6GUCCQ/ref=sr_1_8?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-8&th=1 | B01H6GUCCQ | BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo | BENGOO | Bengoo Inc.Bengoo Inc. | https://www.amazon.com/gp/help/seller/at-a-glance.html/ref=dp_merchant_link?ie=UTF8&seller=A1BCXRJQ9212UU&asin=B01H6GUCCQ&ref_=dp_merchant_link&isAmazonFulfilled=1 | 108,513 | [{"level": 1, "name": "Video Games", "url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"}, {"level": 2, "name": "Legacy Systems", "url": "/Systems-Games/b/ref=dp_bc_aui_C_2?ie=UTF8&node=294940"}, {"level": 3, "name": "Nintendo Systems", "url": "/b/ref=dp_bc_aui_C_3?ie=UTF8&node=23563593011"}, {"level": 4, "name": "Nintendo 3DS & 2DS", "url": "/Nintendo-3DS-Games-Hardware-Consoles/b/ref=dp_bc_aui_C_4?ie=UTF8&node=2622269011"}, {"level": 5, "name": "Accessories", "url": "/Nintendo-3DS-Accessories/b/ref=dp_bc_aui_C_5?ie=UTF8&node=2622272011"}] | 4.3 | USD | 19.99 | 35.99 | - | 【Multi-Platform Compatible】Support PlayStation 4, New Xbox One, PC, Nintendo 3DS, Laptop, PSP, Tablet, iPad, Computer, Mobile Phone. Please note you need an extra Microsoft Adapter (Not Included) when connect with an old version Xbox One controller. - 【Surrounding Stereo Subwoofer】Clear sound operating strong brass, splendid ambient noise isolation and high precision 40mm magnetic neodymium driver, acoustic positioning precision enhance the sensitivity of the speaker unit, bringing you vivid sound field, sound clarity, shock feeling sound. Perfect for various games like Halo 5 Guardians, Metal Gear Solid, Call of Duty, Star Wars Battlefront, Overwatch, World of Warcraft Legion, etc. - 【Noise Isolating Microphone】Headset integrated onmi-directional microphone can transmits high quality communication with its premium noise-concellng feature, can pick up sounds with great sensitivity and remove the noise, which enables you clearly deliver or receive messages while you are in a game. Long flexible mic design very convenient to adjust angle of the microphone. - 【Great Humanized Design】Superior comfortable and good air permeability protein over-ear pads, muti-points headbeam, acord with human body engineering specification can reduce hearing impairment and heat sweat.Skin friendly leather material for a longer period of wearing. Glaring LED lights desigend on the earcups to highlight game atmosphere. - 【Effortlessly Volume Control】High tensile strength, anti-winding braided USB cable with rotary volume controller and key microphone mute effectively prevents the 49-inches long cable from twining and allows you to control the volume easily and mute the mic as effortless volume control one key mute. | Previous page Next page The video showcases the product in use. The video guides you through product setup. The video compares multiple products. The video shows the product being unpacked. | In Stock | - | G9000 | color: Blue | Video Games > Legacy Systems > Nintendo Systems > Nintendo 3DS & 2DS > Accessories | [{"ASIN": "B01H6GUCCQ", "Age Range (Description)": "Adult", "Amazon Best Sellers Rank": "#20 in Video Games , #1 in Nintendo 3DS & 2DS Accessories , #2 in PC Game Headsets , #2 in Mac Game Headsets", "Audio Driver Type": "Dynamic Driver", "Cable Feature": "Detachable", "Carrying Case Weight": "0.1 Pounds", "Compatible Devices": "PS4, Xbox One, PS5, PC, NES, Mac", "Connectivity Technology": "Wired", "Control Method": "Touch", "Control Type": "Volume Control", "Country of Origin": "China", "Date First Available": "June 22, 2016", "Global Trade Identification Number": "00613865268579", "Hardware Platform": "PCPS4MACXBOX ONEXBOX 360", "Headphones Jack": "3.5 mm Jack", "Included Components": "Headphone", "Is Autographed": "No", "Is Discontinued By Manufacturer": "No", "Item Dimensions LxWxH": "8.3 x 4.4 x 7.9 inches", "Item Weight": "9.6 ounces", "Item model number": "G9000", "Manufacturer": "BENGOO", "Material": "Faux Leather, Metal", "Model Name": "G9000", "Package Type": "FFP (Flat Free Package) or equivalent Amazon certified package", "Product Dimensions": "8.3 x 4.4 x 7.9 inches", "Recommended Uses For Product": "Calling, Gaming", "Specific Uses For Product": "Gaming", "Theme": "Video Game", "UPC": "716045368943 712073576640 613865268579 716045603754 715668392526 759321850411 608560160938 712073576169 791313786056 601490994185", "Unit Count": "1.0 Count"}] | [{"Brand": "BENGOO", "Color": "Blue", "Ear Placement": "Over Ear", "Form Factor": "Over Ear", "Noise Control": "Sound Isolation"}] | https://m.media-amazon.com/images/I/61CGHv6kmWL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/71z2WmHMtZL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/71UAwQgt-cL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/71Ie8vokMuL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/71rxKLsCxqL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/71dybzbdO9L._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/71732pdsbQL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/71sOPtDbN7L._AC_SL1000_.jpg | [{"asin": "B0982NYVQV", "color_name": "Black"}, {"asin": "B08ZCHLZX9", "color_name": "Green"}, {"asin": "B082VCPF1W", "color_name": "Orange"}, {"asin": "B081JP3MJK", "color_name": "Red"}, {"asin": "B01H6GUCCQ", "color_name": "Blue"}, {"asin": "B08FDPNVJC", "color_name": "Pink"}, {"asin": "B07VVHV6XV", "color_name": "Purple"}, {"asin": "B08ZCQWGTG", "color_name": "White"}] | [{"color_name": ["Black", "Blue", "Green", "Orange", "Pink", "Purple", "Red", "White"]}] | - | [{"author_name": "Robyn Simmons", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHFLGDCI5VVQARODNRGA56W2V7PA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I\u2019m so impressed with this gaming headset! It\u2019s truly plug and play\u2014no complicated setup, just plug it in and you\u2019re good to go. The sound quality is amazing, and the microphone picks up my voice clearly without any issues. It\u2019s also incredibly comfortable to wear for long gaming sessions. The ear cups are soft and fit well, so no discomfort even after hours of use. The headset feels sturdy and well-built, so I\u2019m confident it will last through lots of gaming sessions. Overall, this is a fantastic headset for the price. It\u2019s easy to use, comfortable, and durable\u2014exactly what I was looking for. Highly recommend it to any gamer!", "review_title": "Fantastic Gaming Headset \u2013 Easy, Comfortable, and Durable!", "review_url": "https://www.amazon.com/gp/customer-reviews/R2YIRGYRQJYKPW/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ", "reviewed_date": "February 09, 2025", "reviewed_product_variant": "Color: Blue"}, {"author_name": "Dee", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AGK6AUZYYRFNSSLOW4UEJ6F5HBXQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "\"I\u2019m really impressed with the BENGOO G9000 Stereo Gaming Headset. It\u2019s perfect for PS4, PC, Xbox One, PS5, and other platforms. The sound quality is fantastic, with bass surround that enhances the gaming experience. The noise-cancelling mic works great for clear communication during games, and the LED light adds a cool touch to the overall design. The over-ear headphones are very comfortable, and the soft memory earmuffs don\u2019t hurt my ears after long gaming sessions. It\u2019s well-built, with solid sound quality and clear mic performance for gaming or chatting. Plus, it\u2019s compatible with multiple devices like laptops, Macs, and even Nintendo NES Games, making it a versatile headset. Pros: Excellent sound quality and bass surround Noise-cancelling mic for clear communication LED lights for a cool look Soft memory earmuffs for comfort Compatible with multiple gaming platforms Cons: None! Very happy with the headset. Overall, I highly recommend this headset for anyone looking for a comfortable, high-quality gaming experience!\"", "review_title": "Excellent Gaming Headset \u2013 Comfortable and Great Sound Quality", "review_url": "https://www.amazon.com/gp/customer-reviews/RRZ06YZC2JJH1/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ", "reviewed_date": "January 25, 2025", "reviewed_product_variant": "Color: Blue"}, {"author_name": "JUAN", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHMO42DMDCWHPZIC7VBOG4ONNAWQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "4.0", "review_text": "I use these for call of duty and youtube some times my oculus 2. The rgb works with a smooth fade out loop although it's not addressable rgb it's pretty nice they even send adapters so it you want to power the rgb when your on xbox or ps5 it's independent from the controller power source (batteries) for pc you can just hook it up. Con the volume and mute switch on mine usually faces inward not a huge problem but sometimes moving around with raise or lower the volume a minor inconvenience if I would have designed it one would be on each side instead. Pros decent sound quality yesterday it saved me from being shot from behind in cod mw 2.0 the surround sound is decently crisp. The company is eager to please to to make sure you like it by the time I got it and started using it after a week they were checking up on how I liked it. After a couple messages back and forth he/she told me about the rgb being independent from the jack. Most of the rgb wired headphones I've seen aren't separated and only work on the pc. Now even watching TV (I have a projector) I can use the rgb. Microphone works as it should noise canceling I never hear complains from other players. The top fabric for comfort is comfortable I'm keeping the plastic they package it with to keep it clean. Each ear side get an addition inch approximately of length for people with bigger heads. The plastic ear cuffs are not going to flex unless to beat it with a heavy object the head band has just enough flex to it. And the microphone can be moved as it's flexible but also turned all the way pointing up . The head jack and usb splitter is pretty long about 6ft or so and it comes with a quality velcro cord piece to roll up for non use meaning if you wanted to you could put it on a headphone stand and hide the cords from you cat so it's not dangling. Suggestions to the company slightly thicker ear cups would be nice I got big ears so they kinda touch the inner fabric of the cuff and if I squeeze a little bit there's a little but of suction in my ears. Change the volume scrolling wheel to a sliding one and put it opposite of the microphone mute switch. Possible issues sometimes the microphone doesn't register on cod mw 2.0. However this is more likely to be call of duty chat program than the headphones because it happened multiple times with other headphones as well.", "review_title": "Good headphones", "review_url": "https://www.amazon.com/gp/customer-reviews/R25BORH9KHEJ5Y/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ", "reviewed_date": "October 05, 2024", "reviewed_product_variant": "Color: Blue"}, {"author_name": "RealDeal", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHZNOQG6ZOUC6U4YN2R6FXBI7CMA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "These Bengoo G9000 wired heaphones are my go to headphones when playing Xbox One! I just plug it into my controller and I'm all set for gaming and chat. They are comfortable after hours of play, don't hurt my ears, have great sound quality, and the mic still works great! In the past, I've had Turtle Beach headphones ($200+), some other no-name brand headphones (also for about $20 on Amazon), and even Amazon Basic blue tooth headphones. All of these have broken or had its problems with connection or wiring, hurting my head and ears, or just stopped working; which is why I'm writing this review. Just letting others know if they are on the fence about this headset, they are pretty solid. The cons that I have with these after 4 years of use are: 1) 3.5mm plug - would be better if it had the option to go either 3.5mm or USB for voice/sound but I only use these for Xbox gaming so the 3.5mm works great for me. 2) After 4 years, the ear pads are starting to flake off so finding replacement ear pads has been challenging. It's almost cheaper to just buy a new set of G9000 but that seems like a real waste. 3) in-cable mic volume and on/off switch seems to be a little fragile; I don't play around with it much so that's not an issue for me Pros: 1) work like they should, never had issues with sound, connection, microphone 2) comfortable - my head doesn't hurt after long hours of use, my ears aren't sore or burning hot from being sucked into a vacuum by the ear cups 3) the cord is extra long so I can move about when I need to", "review_title": "Bought these Bengoo G9000 Wired Headphones in 2021 and still going strong in 2025!", "review_url": "https://www.amazon.com/gp/customer-reviews/R398O2SPMRMQB4/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ", "reviewed_date": "February 14, 2025", "reviewed_product_variant": "Color: Blue"}, {"author_name": "B&K Garside", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHQUWFSXCI7HBEIYV2K6NAJ5FC2Q/ref=cm_cr_dp_d_gw_pop?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I was skeptical due to price but it's very comfortable to wear. I like the adjustable length around the head, especially the soft head rest underneath at the top and the soft over the ear muffs and decent speakers for good quality sound. I was pleasantly surprised. The mic works just fine. Took me a few secs to figure out the mic but it works great. I like the adjustable controls. All around a good product.", "review_title": "Functions great. Good quality for reasonable price.", "review_url": "https://www.amazon.com/gp/customer-reviews/RU7ETQJU72NA0/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ", "reviewed_date": "January 13, 2025", "reviewed_product_variant": "Color: Blue"}, {"author_name": "Michael", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "These headphones are amazing! they are pretty cool, I love it when I first saw it. It has two plugs for two different things. It's realy easy for me to change the volume, and you can mute/open the mic pretty easily. Everything I heard from it is really clear, you can hear everything that your friend says, even whispers. And these are not easy to break, it can really survive from some normal hits. These are one of the best headphones I've used!", "review_title": "Amazing headphones!", "review_url": null, "reviewed_date": "November 17, 2024", "reviewed_product_variant": "Color: Blue"}, {"author_name": "Carlos", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Son c\u00f3modos y tiene un buen sonido nada espectacular pero bueno para juegos", "review_title": "Buen sonido", "review_url": null, "reviewed_date": "August 11, 2023", "reviewed_product_variant": "Color: Blue"}, {"author_name": "SANTOS SOTA", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "MAGN\u00cdFICO SONIDO EST\u00c9REO. LO YA INDICADO RELACI\u00d3N CALIDAD/PRECIO, ENV\u00cdO MUY R\u00c1PIDO POR PARTE DEL VENDEDOR. TANTO POSITIVO QUE HE COMPRADO OTRO PARA TENERLO DE REPUESTO SIN BUSCAR NADA CUANDO CON EL TIEMPO DE USO SE ESTROPEE \u00c9STE", "review_title": "OPTIMA RELACI\u00d3N CALIDAD/PRECIO", "review_url": null, "reviewed_date": "December 21, 2024", "reviewed_product_variant": "Color: Blue"}, {"author_name": "Rony", "author_profile": null, "badge": "Verified Purchase", "rating": "3.0", "review_text": "\u0648\u0627\u062c\u0647\u062a\u0646\u0627 \u0645\u0634\u0643\u0644\u0647 \u0641\u064a \u0627\u0644\u0627\u0633\u0644\u0627\u0643 \u0648\u0644\u0643\u0646 \u0627\u0644\u0645\u0646\u062a\u062c \u0644\u0627\u0628\u0627\u0633 \u0628\u0647", "review_title": "\u062c\u064a\u062f", "review_url": null, "reviewed_date": "November 16, 2024", "reviewed_product_variant": "Color: Blue"}, {"author_name": "A.R.1969", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Die Kopfh\u00f6rer wurden jetzt schon mehrmals von uns bestellt. F\u00fcr den Preis bieten sie eine angemessene Qualit\u00e4t. Sie lassen sich gut tragen, die Klangqualit\u00e4t ist v\u00f6llig in Ordnung und ihre Lebensdauer ist bei normaler Nutzung absolut ok. Ich bin positiv \u00fcberrascht und empfehle denjenigen einen Kauf, die keine \u00fcberhohen Anspr\u00fcche an die Kopfh\u00f6rer haben, denn Profi-Ger\u00e4te gibt es zu diesem Preis ganz bestimmt nicht.", "review_title": "G\u00fcr den Preis ein richtiges Schn\u00e4ppchen!", "review_url": null, "reviewed_date": "March 26, 2024", "reviewed_product_variant": "Color: Blue"}] | [{"asin": "B07XHGLSGF", "image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg", "price": "$32.99", "product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center", "rating": "4", "reviews": "12,179", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU5NzUwMjE2MzkwMjo6Ojo&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B09FXFSY6R", "image_url": "https://m.media-amazon.com/images/I/51yg9upokuL._AC_UF480,480_SR480,480_.jpg", "price": "$17.99", "product_name": "Gaming Headset for PC, Ps5, Switch, Mobile, Gaming Headphones for Nintendo with Noi...", "rating": "4", "reviews": "6,743", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDE1OTk3NTA4MDcwMjo6Ojo&url=%2Fdp%2FB09FXFSY6R%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB09FXFSY6R%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B096VRK6J5", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$33.99", "product_name": "BINNUNE Wireless Gaming Headset with Microphone for PC PS4 PS5, 2.4G Wireless Bluetooth USB Gamer Headphones with Mic for Laptop Computer", "rating": "4", "reviews": "11,435", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDMxMDA0NTQ3MTUwMjo6Ojo&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDMxMDA0NTQ3MTUwMjo6Ojo&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B076DWKD5B", "image_url": "https://m.media-amazon.com/images/I/41GMkz1amLL._AC_UF480,480_SR480,480_.jpg", "price": "$23.98", "product_name": "BENGOO V-4 Gaming Headset for Xbox Series X|S, Xbox One, PS5, PC, Mac, Nintendo Switch, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs", "rating": "4", "reviews": "18,635", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA4ODYxMDQ2MTcxMTo6Ojo&url=%2Fdp%2FB076DWKD5B%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB076DWKD5B%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0DCZLZ43C", "image_url": "https://m.media-amazon.com/images/I/51aF0fiPIUL._AC_UF480,480_SR480,480_.jpg", "price": "$25.99", "product_name": "Wireless Gaming Headset for Ps5 Ps4 PC Switch Wireless Gaming Headphones 2.4GHz USB...", "rating": "4", "reviews": "86", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU3OTE4MjA5MTAwMjo6Ojo&url=%2Fdp%2FB0DCZLZ43C%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0DCZLZ43C%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1MCUL09GNRZKI"}, {"asin": "B0DBLHVGV7", "image_url": "https://m.media-amazon.com/images/I/41AsluAshiL._AC_UF480,480_SR480,480_.jpg", "price": "$15.99", "product_name": "S30 Gaming Headset with Microphone,198g Lightweight Design, Gaming Headphones for X...", "rating": "4", "reviews": "360", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ3MjI4OTE2OTMwMjo6Ojo&url=%2Fdp%2FB0DBLHVGV7%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0DBLHVGV7%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B07R4R75DP", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$21.99", "product_name": "Pacrate Gaming Headset for PS5/PS4/Xbox One/Nintendo Switch/PC/Mac, PS5 Headset with Microphone Xbox Headset with LED Lights, Noise Cancelling PS4 Headset for Kids Adults - Blue", "rating": "4", "reviews": "20,306", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDYwNzA3MTk2MDMwMjo6Ojo&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDYwNzA3MTk2MDMwMjo6Ojo&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B09ZW52XSQ", "image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$212.95", "product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360\u00b0 Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch", "rating": "4", "reviews": "1,280", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwNTk1NTU5MTM4OTg6Ojo6&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B081415GCS", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$119.99", "product_name": "Logitech G733 Lightspeed Wireless Gaming Headset with Suspension Headband, Lightsync RGB, Blue VO!CE mic technology and PRO-G audio drivers - Black", "rating": "4", "reviews": "17,266", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAyMTIwMTgxOTgzMDI6Ojo6&url=%2Fdp%2FB081415GCS%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB081415GCS%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAyMTIwMTgxOTgzMDI6Ojo6&url=%2Fdp%2FB081415GCS%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB081415GCS%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0C4ND25FT", "image_url": "https://m.media-amazon.com/images/I/41TSn76LbZL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$37.99", "product_name": "FIFINE PC Gaming Headset, USB Headset with 7.1 Surround Sound, Detachable Microphone, Control Box, 3.5mm Headphones Jack, Over-Ear Wired Headset for PS5/Xbox/Switch, Black-AmpliGame H9", "rating": "4", "reviews": "1,332", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAwNTU0OTQ2NTM1MDI6Ojo6&url=%2Fdp%2FB0C4ND25FT%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0C4ND25FT%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0CLLJC6QC", "image_url": "https://m.media-amazon.com/images/I/41PGf7xj-iL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$39.99", "product_name": "Wireless Gaming Headset, 7.1 Surround Sound, 2.4Ghz USB Gaming Headphones with Blue...", "rating": "4", "reviews": "895", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAyMDI2MDcxNTU0MDI6Ojo6&url=%2Fdp%2FB0CLLJC6QC%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0CLLJC6QC%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B07XHGLSGF", "image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg", "price": "$32.99", "product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center", "rating": "4", "reviews": "12,179", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1OTc1MDIxNjM5MDI6Ojo6&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B096VRK6J5", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$33.99", "product_name": "BINNUNE Wireless Gaming Headset with Microphone for PC PS4 PS5, 2.4G Wireless Bluetooth USB Gamer Headphones with Mic for Laptop Computer", "rating": "4", "reviews": "11,435", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAzMTAwNDU0NzE1MDI6Ojo6&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAzMTAwNDU0NzE1MDI6Ojo6&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B076DWKD5B", "image_url": "https://m.media-amazon.com/images/I/41GMkz1amLL._AC_UF480,480_SR480,480_.jpg", "price": "$23.98", "product_name": "BENGOO V-4 Gaming Headset for Xbox Series X|S, Xbox One, PS5, PC, Mac, Nintendo Switch, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs", "rating": "4", "reviews": "18,635", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwODg2MTA0NjE3MTE6Ojo6&url=%2Fdp%2FB076DWKD5B%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB076DWKD5B%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}] | [{"five_star": "66%", "four_star": "15%", "one_star": "7%", "three_star": "8%", "two_star": "4%"}] |
| https://www.amazon.com/Headphones-Detachable-Microphone-Backlight-Surround/dp/B0DM9HBJW7/ref=sr_1_10?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming+headphones&qid=1739906138&sprefix=gaming+headphones%2Caps%2C299&sr=8-10 | B0DM9HBJW7 | Gaming Headset for PS4, PS5, Xbox One X/S (No Adapter), 3.5mm Wired Headphones with Detachable Cat Ears, Microphone, RGB Backlight, Surround Sound, Purple | PHNIXGAM | PHNIXGAM USPHNIXGAM US | https://www.amazon.com/gp/help/seller/at-a-glance.html/ref=dp_merchant_link?ie=UTF8&seller=A29F6LGV4C2HK5&asin=B0DM9HBJW7&ref_=dp_merchant_link&isAmazonFulfilled=1 | 16 | - | 4.5 | USD | 32.99 | - | - | Lovely Design: With purple appearance, removable silicon cat ears and cool RGB lighting, the headset will make you girls women look much adorable. The RGB backlight can be turned off with the switch on its line control - Comfortable to Wear: The headband has 7 adjustable sizes to fit different head shapes. The ear cups are large enough to wrap eras, and the ear-pads are made of memory foam. Comfortable to wear for a long time - Retractable Microphone: The microphone is rotating and can reduce environment noises to the maximum. Also it is retractable and retracted into the mic hole, so you need to pull it out for use. The mic can be turned off with the mute button on the line control - Surround Sound: With 50mm audio driver, the headphones deliver stereo sound. With them on ears, you can enjoy high quality music time or hear clearly where your rivals are in video games - Compatibility: This headset is wired, so it can only work with 3.5mm supported mobile phones, tablets, computers and game consoles like P54, PS5 and Xbox One. It does not work with wireless supported devices like XBOX REMOTE. It needs an extra Microsoft adapter to connect with an older Xbox One model. The headset USB cable is only used for RGB backlight. Connect the USB cable, then turn on the RGB switch on wire control box, the RGB will light up | - | In Stock | - | K9 07 | - | - | [{"ASIN": "B0DM9HBJW7", "Age Range (Description)": "Adult", "Audio Driver Size": "5E+1 Millimeters", "Audio Driver Type": "Dynamic Driver", "Compatible Devices": "Mobile Phones, Tablets, Computers, PS4, PS5, Xbox One (with adapter for older models)", "Connectivity Technology": "Wired", "Control Type": "Media Control", "Controller Type": "Gamepad", "Country of Origin": "China", "Date First Available": "November 7, 2024", "Earpiece Shape": "over_ear", "Headphones Jack": "3.5 mm Jack", "Included Components": "1 * User Manual, 1 * Gaming Headset", "Is Autographed": "No", "Item Weight": "1.21 pounds", "Item model number": "K9 07", "Manufacturer": "PHNIXGAM", "Material": "Memory Foam", "Model Name": "K9 07", "Number of Items": "1", "Package Dimensions": "8.86 x 7.87 x 3.9 inches", "Package Type": "Box Packaging", "Recommended Uses For Product": "Gaming", "Specific Uses For Product": "Gaming", "Style": "Gaming", "Theme": "Anime", "Water Resistance Level": "Not Water Resistant"}] | [{"Brand": "PHNIXGAM", "Color": "Purple", "Ear Placement": "Over Ear", "Form Factor": "Over Ear", "Noise Control": "Active Noise Cancellation"}] | https://m.media-amazon.com/images/I/61Kj23p1XxL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/611FgU+A0OL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61opHx7lk3L._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71GSaj0R3YL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71oWtZP1fZL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61QfzbumooL._AC_SL1500_.jpg | - | [{}] | - | [{"author_name": "Draknus", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEAI6OSRCNT7WT4FQF6O6IZV2LUQ/ref=cm_cr_dp_d_gw_pop?ie=UTF8", "badge": null, "rating": "5.0", "review_text": "The cat ears are very easily removable and easy to put back on, which is great because I have weak hands. I love the volume wheel on the side of the little toggle box, and I love how easy it is to mute and unmute. The mic being able to be stowed out of the way is also great. It's a really comfortable headset to use, and the sound quality is above average in my opinion. No regrets here, it's cute and good quality and I love it.", "review_title": "Cute And Comfortable Headset!", "review_url": "https://www.amazon.com/gp/customer-reviews/RNMC4A8JVO31I/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7", "reviewed_date": "January 27, 2025", "reviewed_product_variant": null}, {"author_name": "John Baltisberger", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AGUEAG4BHFHYE5A37AOHD4HTFE4Q/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": null, "rating": "5.0", "review_text": "Got these for my daughter, she loves them, the ears are detachable so you can choose whether to wear them or not.", "review_title": "Daughter loves these", "review_url": "https://www.amazon.com/gp/customer-reviews/R2K561S25KN60K/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7", "reviewed_date": "February 05, 2025", "reviewed_product_variant": null}, {"author_name": "Hardman", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHPMUTP2LYCR3JITW34AAF2XL4FA/ref=cm_cr_dp_d_gw_pop?ie=UTF8", "badge": null, "rating": "4.0", "review_text": "These Headphones are a stylish and functional choice for gamers, offering a range of features to enhance the gaming experience. The 3.5mm wired connection is convenient for multiple platforms like PS4, PS5, and Xbox One X/S, requiring no additional adapter. The headset boasts a detachable cat ear design, which adds a fun, customizable touch, especially for those who love a bit of flair. These were happily recieved by my 7 year old daughter who really loves the kitty ears look. The \"noise-canceling\" microphone is supposed to ensure clear communication, while the RGB backlight adds a vibrant, immersive effect. The microphone performance is okay. Additionally, the surround sound feature provides an engaging audio experience. Overall, it\u2019s a good choice for gamers looking for both aesthetics and performance in a budget-friendly headset.", "review_title": "\u201cTime spent with cats is never wasted.\u201d", "review_url": "https://www.amazon.com/gp/customer-reviews/R2WL35IBXS2HGS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7", "reviewed_date": "December 31, 2024", "reviewed_product_variant": null}, {"author_name": "Smosh", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEUATSS6NCFIET36AYT6KYK4MERQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": null, "rating": "5.0", "review_text": "It is more comfortable that I expected. Good padding on the ears and headpiece. The cat ears are easily removable if you so choose, but why would you want to? Easy set up, just plugged them in and they worked. Easy controls on the cord. While I can't hear myself, other say they sound clear.", "review_title": "Nice gaming headset", "review_url": "https://www.amazon.com/gp/customer-reviews/RHDYRLVOMF4WX/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7", "reviewed_date": "January 12, 2025", "reviewed_product_variant": null}, {"author_name": "wl79", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHG27EAZPHL6T57WBZIIBJ5MJ7BA/ref=cm_cr_dp_d_gw_pop?ie=UTF8", "badge": null, "rating": "5.0", "review_text": "My rabbit chewed up the cord to my old gaming headset, which I needed for a remote job I am interviewing for! This headset is a godsend! I will be going through the interview on Monday, but I've been using it on my laptop and it's working wonderfully. It also matches my computer keyboard and mouse 🙂 The cat ears are detachable!! I really wanted the cute ears....but you have to be professional sometime; this offers the best of both worlds \ud83d\udc9c", "review_title": "Loving it!", "review_url": "https://www.amazon.com/gp/customer-reviews/R1331CZJF1V6KT/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7", "reviewed_date": "January 04, 2025", "reviewed_product_variant": null}, {"author_name": "Clemen Samuels", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEBKIUGDJBED4UH7PSPFARNFBQ6Q/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": null, "rating": "2.0", "review_text": "I went thru a period of time thinking my xbox wireless headset by xbox/microsoft were failing for no reason and there was no recovering them to their golden days... Turns out my series X was overheating and a result was constant signal drops, notifications constantly saying \"headset connected\", going silent, and such... I was deep in a pubg game with 8 or less sometime and my headphones would go silent. Since fixed the issue with a fan and my headset has no issues. Hopefully this review will help at least one person. So...I ordered every headset I saw for about 2 weeks. Controller dongle with earbuds attached via bluetooth..3 earbud sets, 2 wired sets and. Dongle had interference issues with the paired earbuds. Only one wired set was worth mentioning, so I will. NUBWO, made some acceptable headphones. Will definitely look through their products in the future", "review_title": "The sizing was not for me, they were just too big to be used", "review_url": "https://www.amazon.com/gp/customer-reviews/RAEI1N9R1SAGL/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7", "reviewed_date": "January 20, 2025", "reviewed_product_variant": null}, {"author_name": "StacyLynn", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AH5EHU7EJUXQ73YSLECFWSPTL43Q/ref=cm_cr_dp_d_gw_pop?ie=UTF8", "badge": null, "rating": "5.0", "review_text": "I LOVE them! I am rating 5 \u2b50\ufe0f's for... \u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f Comfortable ear muffs! \u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f Excellent sound quality! \u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f Awesome \"giftable\" packaging! \u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f Working great with my laptop and my Xbox! \u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f Removeable kitty ears! \u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f My favorite color purple! \u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f\u2b50\ufe0f THE FACT THAT THEY ARE TOTALLY ADORABLE! Who doesn't love kitty ears?! I just had to have these in my life, and I think you will love them too!", "review_title": "I didnt think I would like these.", "review_url": "https://www.amazon.com/gp/customer-reviews/R3B0CTR56BC72N/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7", "reviewed_date": "January 06, 2025", "reviewed_product_variant": null}, {"author_name": "Lara Cee", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AE4DTCVBS3GPDSCXHVE3ZRK24CWQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": null, "rating": "4.0", "review_text": "These headphones looked exactly like the photos and are super high quality. Love the lavender color and the cat ears. They work great too but the sound could be better.", "review_title": "Cute high quality headphones", "review_url": "https://www.amazon.com/gp/customer-reviews/R2A8FVIYGS1F9C/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7", "reviewed_date": "January 02, 2025", "reviewed_product_variant": null}] | - | [{"five_star": "71%", "four_star": "20%", "one_star": "0%", "three_star": "0%", "two_star": "9%"}] |
| https://www.amazon.com/ZIUMIER-Microphone-Surround-Over-Ear-Headphones/dp/B07ZF8T63K/ref=sr_1_11?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-11&th=1 | B07ZF8T63K | ZIUMIER Gaming Headset with Microphone, Compatible with PS4 PS5 Xbox One PC Laptop, Over-Ear Headphones with LED RGB Light, Noise Canceling Mic, 7.1 Stereo Surround Sound | ZIUMIER | ZIUMIERZIUMIER | https://www.amazon.com/gp/help/seller/at-a-glance.html/ref=dp_merchant_link?ie=UTF8&seller=A1JXNP286MCB23&asin=B07ZF8T63K&ref_=dp_merchant_link&isAmazonFulfilled=1 | 10,466 | [{"level": 1, "name": "Video Games", "url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"}, {"level": 2, "name": "PlayStation 4", "url": "/PlayStation-4-Games-Consoles-Accessories-Hardware/b/ref=dp_bc_aui_C_2?ie=UTF8&node=6427814011"}, {"level": 3, "name": "Accessories", "url": "/PlayStation-4-Hardware-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=6427815011"}, {"level": 4, "name": "Headsets", "url": "/PlayStation-4-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=6427826011"}] | 4.3 | USD | 19.99 | 29.99 | - | PROFESSIONAL GAMING HEADPHONE. with 50mm drivers that deliver superior audio performance, ZIUMIER PS4 headset can generate a virtual surround sound experience to create distance and depth that enhances any gaming, movie or music experience. perfect for most FPS games like God of war, Fortnite, PUBG or CS: GO. - BUILT FOR COMFORT. ZIUMIER Z20 lightweight design Xbox one headset comes with breathable protein memory foam ear pads, retractable headbeam, and flexible headband to make sure every gamer can enjoy optimal wearing comfort in a long-time fierce game. - NOISE CANCELING MICROPHONE. An omnidirectional sensitive microphone with noise-cancelling tech can transmit high-quality communication. Get clearer voice quality and reduced background noise for an improved voice experience. - MULTI-PLATFORMS HEADSET. This gaming headset with a 3.5mm audio jack is compatible with PC, PlayStation 4, PlayStation 5, Xbox One, Xbox Series S, Xbox Series X (For Xbox One controller 1537, an adapter will be required to use this headset), Nintendo Switch, Laptop, Mac, Tablet, Phone - EFFORTLESSLY IN-LINE CONTROL. Our pc headset comes with 5ft high tensile strength, anti-winding braided cable with rotary volume controller & mute button for the microphone. Easy to reach, convenient to use. (The USB connection is ONLY used for lighting glaring moving LED lights) | The video showcases the product in use. The video guides you through product setup. The video compares multiple products. The video shows the product being unpacked. Surround Sound Gaming Headset Hear Enemies From All Sides Z20 Series is the wired headset for competitive gamers, with 50mm drivers to deliver premium audio tuned for gaming and create an immersive audio experience. Noise-Cancelling Microphone The Omnidirectional microphone focuses on your voice for crystal-clear voice comms that are heard loudly and clearly. Long-Lasting Comfort It's fitted with large-diameter breathable protein ear cushions which fit completely around the ears and provide passive noise isolation so you can enjoy gaming for hours One Headset for All Game Platfroms For gaming and Streaming Plug the 3.5mm jack into your gaming device, it supports PlayStation 4, Playstation 5, Xbox One, Xbox Series S, Xbox Series X, PC, Mac Compare gaming headsets Z20 Add to Cart Z66 Z30 M09 Buying Options Customer Reviews 4.3 out of 5 stars 10,466 10,971 4.2 out of 5 stars 3,729 3.9 out of 5 stars 107 Price $19.99 $ 19 . 99 $15.99 15 $28.99 28 — Connection Wired Wireless+Bluetooth Driver Size 50mm Inputs 3.5mm USB Controls In-Line Remote On-Ear Controls MIC undetachable,omnidirectional Detachable,omnidirectional Compatibility PS5,PS4,XBOX,Switch,PC,MAC PS5,PS4,Switch,PC,MAC | In Stock | - | Z20 Black | color: Black | Video Games > PlayStation 4 > Accessories > Headsets | [{"ASIN": "B07ZF8T63K", "Age Range (Description)": "Adults,Teens", "Amazon Best Sellers Rank": "#229 in Video Games , #11 in PlayStation 4 Headsets", "Audio Driver Size": "50 Millimeters", "Audio Driver Type": "Dynamic Driver", "Cable Feature": "Fixed", "Carrying Case Color": "Black", "Compatible Devices": "PC, PS4,PS5 controller, Xbox One,Xbox One S/X controller, Mac, laptop, Phone,Mac", "Connectivity Technology": "Wired", "Control Method": "Remote", "Control Type": "Volume Control", "Controller Type": "Button", "Country of Origin": "China", "Date First Available": "November 26, 2019", "Earpiece Shape": "Over-Ear", "Frequency Range": "20 Hz - 20,000 Hz", "Frequency Response": "20 KHz", "Global Trade Identification Number": "00754610868207", "Headphones Jack": "3.5 mm Jack", "Included Components": "User Manual, 1 * 1-to-2 Y Splitter Cable, 1 * Gaming Headset", "Is Autographed": "No", "Item Weight": "10.6 ounces", "Item model number": "Z20 Black", "Manufacturer": "ZIUMIER", "Material": "Plastic", "Model Name": "Z20", "Noise Control": "None", "Number of Items": "1", "Number of Power Levels": "1", "Package Dimensions": "12.2 x 8.9 x 5.55 inches", "Package Type": "Standard Packing", "Recommended Uses For Product": "Gaming", "Specific Uses For Product": "Gaming", "Style": "Gaming", "Theme": "Video Game", "UPC": "754610868207", "Unit Count": "1.0 Count", "Wireless Communication Technology": "Wired"}] | [{"Brand": "ZIUMIER", "Color": "Black", "Ear Placement": "Over Ear", "Form Factor": "Over Ear", "Impedance": "32 Ohm"}] | https://m.media-amazon.com/images/I/71nh1VxLzuL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61tsYw85INL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61fA6Nd0QbL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71mcE-oBU2L._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61pnc+x52vL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/614UOmc1qzL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/718dl-PD7UL._AC_SL1500_.jpg | [{"asin": "B0CRRSHTH2", "color_name": "Purple"}, {"asin": "B08CZHXRBM", "color_name": "Camouflage"}, {"asin": "B08YNCZDSQ", "color_name": "White"}, {"asin": "B07ZF8T63K", "color_name": "Black"}, {"asin": "B0CKW6753W", "color_name": "Pink"}, {"asin": "B088CZ2Z1B", "color_name": "Green"}] | [{"color_name": ["Black", "Camouflage", "Green", "Pink", "Purple", "White"]}] | - | [{"author_name": "Robyn Simmons", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHFLGDCI5VVQARODNRGA56W2V7PA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I\u2019m really impressed with the ZIUMIER Gaming Headset! The sound quality is fantastic, providing clear and immersive audio that enhances my gaming experience. The bass is deep without being overwhelming, and the overall sound balance is excellent, whether I'm playing games or listening to music. The microphone also works great for in-game chats, with clear voice transmission and noise reduction. The headset is very comfortable to wear for long gaming sessions, thanks to the soft ear cushions and adjustable headband. It fits snugly without being too tight, which is a big plus for me. I also appreciate that it\u2019s compatible with PS4, PS5, Xbox One, PC, and laptops, making it super versatile for all my devices. The build quality feels solid, and the cable is long enough to give me plenty of flexibility. Overall, this is a fantastic gaming headset at a great price, and I highly recommend it to anyone looking for quality sound and comfort.", "review_title": "Great Sound Quality and Comfortable Fit!", "review_url": "https://www.amazon.com/gp/customer-reviews/R3VQKLGWYWDTF8/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K", "reviewed_date": "February 09, 2025", "reviewed_product_variant": "Color: Black"}, {"author_name": "John", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHXOXOWLXCKIXGTIA67MJIFMJTRA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "ZIUMIER Z20 Gaming Headset with Microphone Review Rating: \u2605\u2605\u2605\u2605\u2605 (5/5) Introduction: The ZIUMIER Z20 Gaming Headset is a top-tier choice for gamers seeking an immersive audio experience coupled with exceptional comfort. With 50mm drivers, noise-canceling capabilities, and multi-platform compatibility, this headset is designed to elevate your gaming sessions, whether you're playing on a console, PC, or mobile device. Audio Quality: Equipped with 50mm drivers, the Z20 delivers superior audio performance that immerses you in your game, movie, or music. The virtual surround sound creates a sense of distance and depth, allowing you to pinpoint enemy locations and enjoy an enriched gaming experience. This is especially beneficial in FPS games like God of War, Fortnite, PUBG, and CS: GO. Microphone Performance: The Z20 features an omnidirectional sensitive microphone with advanced noise-canceling technology. This ensures high-quality communication by filtering out background noise, allowing your voice to be heard clearly by your teammates. The result is a significant improvement in voice quality and communication during intense gaming sessions. Comfort and Design: Comfort is a standout feature of the Z20. The lightweight design, breathable protein memory foam ear pads, and flexible headband provide optimal comfort even during long gaming marathons. The retractable head beam adjusts to fit various head sizes, ensuring a snug yet comfortable fit for every gamer. Durability: Constructed with durable materials, the Z20 is designed to withstand the rigors of frequent use. The 6.5ft high tensile strength, anti-winding braided cable ensures longevity and reduces the risk of tangling. The sturdy build quality means this headset will maintain its performance and appearance over time. Compatibility: The Z20 is a versatile headset compatible with multiple platforms, including PC, PS4, PS5, Xbox One, Xbox One S/X, laptops, Macs, tablets, and phones. The 3.5mm audio jack ensures easy connectivity, and while an adapter is required for the older Xbox One controller (model 1537), the headset's broad compatibility makes it a convenient choice for gamers with multiple devices. In-Line Control: The in-line control system of the Z20 is both convenient and user-friendly. The braided cable includes a rotary volume controller and a mute button for the microphone, making it easy to adjust settings on the fly. The USB connection is used exclusively for powering the LED lights, adding a stylish touch to the headset. Conclusion: The ZIUMIER Z20 Gaming Headset with Microphone offers a premium gaming experience with its superior audio quality, noise-canceling microphone, and exceptional comfort. Its robust build and multi-platform compatibility make it a valuable addition to any gamer's setup. Whether you're engaging in a fierce battle or enjoying a cinematic gaming experience, the Z20 delivers on all fronts. Pros: Superior audio performance with 50mm drivers Effective noise-canceling microphone Comfortable design with memory foam ear pads Durable, high-quality construction Wide compatibility with multiple devices Cons: Requires an adapter for older Xbox One controllers (model 1537) In summary, the ZIUMIER Z20 is a five-star gaming headset that provides an immersive and comfortable gaming experience, making it a must-have for serious gamers.", "review_title": "Great Headphones!", "review_url": "https://www.amazon.com/gp/customer-reviews/R3OTAH759ZCF6T/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K", "reviewed_date": "August 02, 2024", "reviewed_product_variant": "Color: Black"}, {"author_name": "Sarah Harless", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFQMPVIWVGWOUBBFQ5YN3A35CGGA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "4.0", "review_text": "I purchased these a while back. My old headphones (and i mean OLD) the audio port was goin bad. It was becoming an annoyance when one moment i could hear, id go to readjust my sitting, and the next moment i cant hear anything. These new headphones are great. The only complaint i have about these is the usb for the LEDs is to short. I dont game infront of a computer, i use a PS5 and there are times id love to plug in the usb, but the split cord for the LEDs isnt long enough to reach my available usb port. It just dangles there next to the audio jack inside my controller. If i could change the cord in manufacturing, id make the usb cord about 4ft long. But thats just me. If u game infront of a computer, these are perfect for u. Theyre comfy as well.", "review_title": "Pretty Good, only 1 complaint.", "review_url": "https://www.amazon.com/gp/customer-reviews/RPDIBM0RBIUBQ/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K", "reviewed_date": "September 22, 2024", "reviewed_product_variant": "Color: Black"}, {"author_name": "Dan", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFEELMRBBEAUQ6X37K2ZEDEN52VQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "Used for gaming, easy to use, affordable and not easily broken. Quality is great too, no crackling or echoing. Easy to hear too", "review_title": "Exactly what I was looking for.", "review_url": "https://www.amazon.com/gp/customer-reviews/R27PLNHOP19DRP/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K", "reviewed_date": "February 01, 2025", "reviewed_product_variant": "Color: Black"}, {"author_name": "NmunniE", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEHHZPZ5KNVXRLWXG6UKHIDRVAIQ/ref=cm_cr_dp_d_gw_pop?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "This headset is quite visually appealing though I\u2019m not entirely sure why that is important to me as they are on the sides of my head during use and for the most part, I am unable to appreciate the true scope of all the rainbow swirly goodness but it\u2019s a nice perk nonetheless. The little mic light also has its own little rainbow light show which is awesome AND visible. The ear cups and headband pad are super squishy and will certainly facilitate hours of Horde comfortably. Aesthetic and comfort wise these things are awesome albeit their sound is disappointing. Voices come in clearly, no complaints there but the game sound is quite tinny and bass leaves a lot to be desired. I did remove a star in the sound rating because of the aforementioned lacking sound quality and I wish the in-line volume went a bit higher. The Xbox One\u2019s controller design is a bit of a nightmare since the port is located at the 6\u2019oclock position and the cord tends to bend awkwardly because it gets in the way and I worry that will break or weaken the copper wire. The headset does include a little Velcro tie to make the long cords more manageable but the bending at the jack is a concern so maybe shrink wrap that part to immobilize it. I kinda of wish that the LED lights didn\u2019t require a second USB cord to work but it\u2019s not a huge issue as the cords are plenty long enough work with. I have a power strip with USB ports so I plug it in there or if you have a headset stand with USB ports even better. All in all it\u2019s a cool headset that gets the job done, and they make my head look enchanted...or like I\u2019m struggling to process something like the rainbow wheel on an Apple computer.", "review_title": "Rad. (Xbox One)", "review_url": "https://www.amazon.com/gp/customer-reviews/RNU3IMAJOZS4W/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K", "reviewed_date": "March 14, 2020", "reviewed_product_variant": "Color: Black"}, {"author_name": "Andrea", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Meravigliose..comodissime e si sentono da Dio", "review_title": "Ottimo materiale", "review_url": null, "reviewed_date": "November 17, 2022", "reviewed_product_variant": "Color: Black"}, {"author_name": "Uschi", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Super heatset gibt nichts dran auszusetzen. Wenn einen die lichter st\u00f6ren kein Problem kann man einfach den Stecker f\u00fcr die lichter entfernen. Man h\u00f6rt seine mitspieler super gut, au\u00dfen Ger\u00e4usche h\u00f6rt man fast gar nicht! Alles im allen ein super Ger\u00e4t kann man nur empfehlen!", "review_title": "Preisleistung top", "review_url": null, "reviewed_date": "May 13, 2022", "reviewed_product_variant": "Color: Black"}, {"author_name": "Cristina", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "funziona benissimo e ha soddisfatto tutte le aspettative. consiglio", "review_title": "ottimo prodotto", "review_url": null, "reviewed_date": "September 17, 2022", "reviewed_product_variant": "Color: Black"}, {"author_name": "Marek", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Ok", "review_title": "Ok", "review_url": null, "reviewed_date": "August 31, 2022", "reviewed_product_variant": "Color: Black"}, {"author_name": "Amazon Kunde", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Toll", "review_title": "Toll", "review_url": null, "reviewed_date": "April 02, 2022", "reviewed_product_variant": "Color: Black"}] | [{"asin": "B01H6GUCCQ", "image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$19.99", "product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo", "rating": "4", "reviews": "108,513", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1NjIyNTUwNjE5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1NjIyNTUwNjE5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UU"}, {"asin": "B08FX7T8Z4", "image_url": "https://m.media-amazon.com/images/I/41pAw9XEAiL._AC_UF480,480_SR480,480_.jpg", "price": "$36.99", "product_name": "EKSA E900 Headset with Microphone for PC, PS4,PS5, Xbox - Detachable Noise Canceling Mic, 3D Surround Sound, Wired Headphone for Gaming, Computer, Laptop, 3.5MM Jack", "rating": "4", "reviews": "3,484", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDIzNTQ5NzUxMTMwMjo6Ojo&url=%2Fdp%2FB08FX7T8Z4%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB08FX7T8Z4%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B09FXFSY6R", "image_url": "https://m.media-amazon.com/images/I/51yg9upokuL._AC_UF480,480_SR480,480_.jpg", "price": "$17.99", "product_name": "Gaming Headset for PC, Ps5, Switch, Mobile, Gaming Headphones for Nintendo with Noi...", "rating": "4", "reviews": "6,743", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDE1OTk3NTA4MDcwMjo6Ojo&url=%2Fdp%2FB09FXFSY6R%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB09FXFSY6R%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B07PRVS98X", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$49.99", "product_name": "EKSA E900 Pro USB Gaming Headset for PC - Computer Headset with Detachable Noise Cancelling Mic, 7.1 Surround Sound, 50MM Driver - Headphones with Microphone for PS4/PS5, Xbox One, Laptop, Office", "rating": "4", "reviews": "5,119", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2NjM1MzI2NDAwMjo6Ojo&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2NjM1MzI2NDAwMjo6Ojo&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B07R4R75DP", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$21.99", "product_name": "Pacrate Gaming Headset for PS5/PS4/Xbox One/Nintendo Switch/PC/Mac, PS5 Headset with Microphone Xbox Headset with LED Lights, Noise Cancelling PS4 Headset for Kids Adults - Blue", "rating": "4", "reviews": "20,306", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ1ODE0OTA0OTQwMjo6Ojo&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ1ODE0OTA0OTQwMjo6Ojo&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0CSZ1CD49", "image_url": "https://m.media-amazon.com/images/I/418PKBl5h3L._AC_UF480,480_SR480,480_.jpg", "price": "$26.99", "product_name": "Gaming Headset with Microphone for PC PS4 PS5 Headset Noise Cancelling Gaming Headphones for Laptop Mac Switch Xbox One Headset with LED Lights Deep Bass for Kids Adults Deep Red", "rating": "4", "reviews": "19,883", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU2NzEwMTg5MzgwMjo6Ojo&url=%2Fdp%2FB0CSZ1CD49%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0CSZ1CD49%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0CH7WLFRN", "image_url": "https://m.media-amazon.com/images/I/417WQ3bhMWL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$19.99", "product_name": "PG1 Gaming Headset for PS4/PS5/PC/Xbox/Nintendo Switch, Xbox One Headset with AI St...", "rating": "4", "reviews": "1,646", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDI3NTAyMTQ1ODAwMjo6Ojo&url=%2Fdp%2FB0CH7WLFRN%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0CH7WLFRN%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B09ZW52XSQ", "image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$212.95", "product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360\u00b0 Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch", "rating": "4", "reviews": "1,280", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjoyMDAwNTk1NTU5MTM4OTg6Ojo6&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B07XHGLSGF", "image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg", "price": "$32.99", "product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center", "rating": "4", "reviews": "12,179", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDAwNzU1MjExMjUwMDI6Ojo6&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B07R4R75DP", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$21.99", "product_name": "Pacrate Gaming Headset for PS5/PS4/Xbox One/Nintendo Switch/PC/Mac, PS5 Headset with Microphone Xbox Headset with LED Lights, Noise Cancelling PS4 Headset for Kids Adults - Blue", "rating": "4", "reviews": "20,306", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA0NTgxNDkwNDk0MDI6Ojo6&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA0NTgxNDkwNDk0MDI6Ojo6&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0878W5F4X", "image_url": "https://m.media-amazon.com/images/I/41EvG7RCdTL._AC_UF480,480_SR480,480_.jpg", "price": "$21.99", "product_name": "Gaming Headset with Microphone for PC PS4 PS5 Headset Noise Cancelling Gaming Headphones for Laptop Mac Switch Xbox One Headset with LED Lights Deep Bass for Kids Adults Black Blue", "rating": "4", "reviews": "19,883", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA1NzQ3MzAxMzA5MDI6Ojo6&url=%2Fdp%2FB0878W5F4X%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0878W5F4X%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B01H6GUCCQ", "image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$19.99", "product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo", "rating": "4", "reviews": "108,513", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjoyMDAwODg1NzA1MTAxOTg6Ojo6&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjoyMDAwODg1NzA1MTAxOTg6Ojo6&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy%26smid%3DA1BCXRJQ9212UU"}, {"asin": "B08FX7T8Z4", "image_url": "https://m.media-amazon.com/images/I/41pAw9XEAiL._AC_UF480,480_SR480,480_.jpg", "price": "$36.99", "product_name": "EKSA E900 Headset with Microphone for PC, PS4,PS5, Xbox - Detachable Noise Canceling Mic, 3D Surround Sound, Wired Headphone for Gaming, Computer, Laptop, 3.5MM Jack", "rating": "4", "reviews": "3,484", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA0MDgwMTU5NzYxMDI6Ojo6&url=%2Fdp%2FB08FX7T8Z4%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB08FX7T8Z4%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B07PRVS98X", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$49.99", "product_name": "EKSA E900 Pro USB Gaming Headset for PC - Computer Headset with Detachable Noise Cancelling Mic, 7.1 Surround Sound, 50MM Driver - Headphones with Microphone for PS4/PS5, Xbox One, Laptop, Office", "rating": "4", "reviews": "5,119", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA2NjIzNjk3NDU3MDI6Ojo6&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA2NjIzNjk3NDU3MDI6Ojo6&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}] | [{"five_star": "67%", "four_star": "14%", "one_star": "7%", "three_star": "8%", "two_star": "4%"}] |
| https://www.amazon.com/Razer-Kraken-Wired-Gaming-Headset/dp/B0BSJYM8FF/ref=sr_1_13?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-13&th=1 | B0BSJYM8FF | Razer Kraken V3 X Wired USB Gaming Headset: Lightweight Build - Triforce 40mm Drivers - HyperClear Cardioid Mic - 7.1 Surround Sound - Chroma RGB Lighting - Black | Razer | Amazon.com | - | 2,071 | [{"level": 1, "name": "Video Games", "url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"}, {"level": 2, "name": "PC", "url": "/PC-Games/b/ref=dp_bc_aui_C_2?ie=UTF8&node=229575"}, {"level": 3, "name": "Accessories", "url": "/PC-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=318813011"}, {"level": 4, "name": "Headsets", "url": "/PC-Game-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=402053011"}] | 4.3 | USD | 39.98 | 69.99 | - | 285G LIGHTWEIGHT BUILD — Experience superior audio and game for hours without being weighed down by the headset - TRIFORCE 40MM DRIVERS — Cutting-edge proprietary design divides the driver into 3 parts for the individual tuning of highs, mids, and lows —producing brighter, clearer audio with richer highs and more powerful lows - HYPERCLEAR CARDIOID MIC — An improved pickup pattern ensures more voice and less noise with the sweet spot easily placed at the mouth because of the mic’s bendable design - HYBRID FABRIC AND MEMORY FOAM EAR CUSHIONS — Wrapped in a combination of breathable fabric and plush leatherette to provide a snug fit to ensure constant comfort for prolonged gaming - 7.1 SURROUND SOUND — Provides accurate positional audio that lets you pinpoint intuitively where every sound is coming from. *Only available on Windows 10 64-bit - POWERED BY RAZER CHROMA RGB — Customizable earcup lighting and greater game immersion, with access to 16.8 million colors and a suite of lighting effects, apply preferred settings and watch it work seamlessly - #1 SELLING PC GAMING PERIPHERALS BRAND IN THE U.S. — Source — Circana, Retail Tracking Service, U.S., Dollar Sales, Gaming Designed Mice, Keyboards, and PC Headsets, Jan. 2019- Dec. 2023 combined | Win the long game with the Razer Kraken V3 X—the ultra-light USB gaming headset made for gaming marathons. With an upgraded mic and drivers for greater sound, improved ear cushions for greater comfort, and Razer Chroma RGB for greater flair, your gaming is set to go the distance. | In Stock | - | RZ04-03750300-R3U1 | color: Black, style: Kraken V3 X | Video Games > PC > Accessories > Headsets | [{"ASIN": "B0BSJYM8FF", "Age Range (Description)": "Adult", "Amazon Best Sellers Rank": "#210 in Video Games , #28 in PC Game Headsets", "Audio Driver Size": "40 Millimeters", "Audio Driver Type": "Dynamic Driver", "Cable Feature": "Retractable", "Compatible Devices": "Laptops, Desktops", "Connectivity Technology": "Wired", "Control Method": "Touch", "Control Type": "Media Control", "Controller Type": "Wired", "Country of Origin": "China", "Date First Available": "January 31, 2023", "Earpiece Shape": "Over Ear", "Frequency Range": "20 Hz - 20,000 Hz", "Hardware Platform": "PC", "Included Components": "Headset", "Is Autographed": "No", "Item Dimensions LxWxH": "8.47 x 6.78 x 3.55 inches", "Item Weight": "9.9 ounces", "Item model number": "RZ04-03750300-R3U1", "Language": "English", "Manufacturer": "Razer", "Material": "Plastic", "Model Name": "Kraken V3 X", "Number of Items": "1", "Operating System": "Windows", "Package Type": "Standard Packaging", "Power Source": "Corded Electric", "Product Dimensions": "8.47 x 6.78 x 3.55 inches", "Recommended Uses For Product": "Gaming", "Series Number": "375", "Specific Uses For Product": "Gaming", "Style": "Kraken V3 X", "Theme": "Video Game", "UPC": "840272903742", "Unit Count": "1 Count", "Wireless Communication Technology": "wired"}] | [{"Brand": "Razer", "Color": "Black", "Ear Placement": "Over Ear", "Form Factor": "Over Ear", "Headphones Jack": "USB"}] | https://m.media-amazon.com/images/I/71NxwEjlU1L._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71Ns3dpNLDL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/610T6qHXK7L._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/61Z8s1ehBHL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/71RnM71BwPL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/712yIMTu+nL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/81tv96YBrUL._AC_SL1500_.jpg | [{"asin": "B09HJYCX5X", "color_name": "Black"}, {"asin": "B0D54V8N2K", "color_name": "Fortnite Edition"}, {"asin": "B09HJC1X9P", "color_name": "Black"}, {"asin": "B0BSJYM8FF", "color_name": "Black"}, {"asin": "B09HJYCX5X", "style_name": "Kraken V3"}, {"asin": "B0D54V8N2K", "style_name": "Kraken V3 X"}, {"asin": "B09HJC1X9P", "style_name": "Kraken V3 HyperSense"}, {"asin": "B0BSJYM8FF", "style_name": "Kraken V3 X"}] | [{"color_name": ["Black", "Fortnite Edition"], "style_name": ["Kraken V3 X", "Kraken V3", "Kraken V3 HyperSense"]}] | [{"link": "https://www.amazon.com/Razer-DeathAdder-Essential-Gaming-Mouse/dp/B094PS5RZQ/ref=pd_bxgy_d_sccl_1/136-5303947-2873247?pd_rd_w=g41WO&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=8KT0SM3BRFVCJ5RGEAAM&pd_rd_wg=bWzoq&pd_rd_r=aeb6806a-1441-45f8-a210-46d399390451&pd_rd_i=B094PS5RZQ&psc=1", "price": "$24.82", "title": "Razer DeathAdder Essential Gaming Mouse: 6400 DPI Optical Sensor - 5 Programmable Buttons - Mechanical Switches - Rubber Side Grips - Classic Black"}, {"link": "https://www.amazon.com/Razer-Ornata-Gaming-Keyboard-Low-Profile/dp/B09X6GJ691/ref=pd_bxgy_d_sccl_2/136-5303947-2873247?pd_rd_w=g41WO&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=8KT0SM3BRFVCJ5RGEAAM&pd_rd_wg=bWzoq&pd_rd_r=aeb6806a-1441-45f8-a210-46d399390451&pd_rd_i=B09X6GJ691&psc=1", "price": "$34.98", "title": "Razer Ornata V3 X Gaming Keyboard: Low Profile Keys - Silent Membrane Switches - Spill Resistant - Chroma RGB Lighting - Ergonomic Wrist Rest - Snap Tap"}] | [{"author_name": "Clifton Gadbois", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AH4Y5A7NTDRY3B3UGG3CFLUYLN5A/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I recently had to replace my aging gaming headphones MPOW EG3's which at the time I bought them worked really well for my needs. I thought that I would get an \"upgrade\" so I tried a pair of wireless headphones which sounded horrible and had no eq software. I tried another wireless headphone and then another. Both times the native sound to the headphones had way too much bass and mids were dull and washy. The software that came with both of them simply did not work; the $140 pair had a reddit post that which gave workarounds for software glitches which they haven't bothered to fix for at least 3 years. Finally I decided to return to wired and I AM SO GLAD that I chose these headphones. Sounded great out of the box, but still a little too much bass. BUT THE EQ SOFTWARE ACTUALLY WORKS! I am a bit of an audiophile as I edit videos for a living, so being able to adjust audio is something I expect. I tried these with a game that know is hard for headphones to get correct, as it has a lot of mixed bass and mids with environmental sounds and music. These headphones with just a few little tweaks SOUND GREAT! They aren't meant for mixing or mastering music--but they ARE GREAT AS GAMING HEADPHONES!", "review_title": "Best gaming headphones I have owned.", "review_url": "https://www.amazon.com/gp/customer-reviews/RP4XQBJMR0BSU/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0BSJYM8FF", "reviewed_date": "October 24, 2024", "reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"}, {"author_name": "AmazonUser", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AF7NB2GOGGZTLSX3SWJ2OG454GLQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "Backstory, I was looking for a new gaming headset, and I went with the very highly reviewed hyperx cloud alpha S, and hated it. I decided to try this one out because I\u2019ve always enjoyed razer products, even if there are a few bad reviews. This headset blows the HyperX out of the water. Better sound, way better comfort, clearer mic, and the hyper sense haptic thing is game changing. Pros: -excellent sound quality -Very comfortable. Ear cups don\u2019t press on jaw like the HyperX, padding is thicker and more resilient feeling. -Noise cancelling is just right. Little things don\u2019t break immersion, but if someone falls down the stairs or the house catches fire, you\u2019ll hear it. -mic is very clear. The synapse tests and peer reviews tell me this is the clearest mic I\u2019ve used, plus it has separate adjustable thresholds for volume, background noise filtering, and voice clarification -Hyper Sense Haptics\u2026. I think this was mostly for People playing FPS games, makes gunfire and such \u201cfeel\u201d more real, but as someone who always has Spotify up while gaming, I Love the simulated base this adds in on low/medium settings. You could never get base like that from speakers that strap to your head, but the haptics can emulate having a nice sub nearby. Very nice touch. -RGB is a tasteful accent, not garish. I also like that I can set which colors I want in my spectrum for various patterns. Setting this to just the shades of blue and green is very nice, and matches the Corsair RGB on my desk/tower Cons: -No mute light on mic. This is a nice feature most brands have and I\u2019ve gotten used to. Nice visible indicator that I have my mic muted to prevent embarrassing over sharing. -Thx surround feature sounds bad. I\u2019m sure it\u2019s great for FPS players that are willing to sacrifice sound quality to have better directional sense, but I\u2019m not a FPS player so it\u2019s not worth the drop in quality. This one isn\u2019t really a detriment, it\u2019s just a feature I don\u2019t use. Sound quality with THX left off is phenomenal. Overall I\u2019m super excited about this one. This is the best headset I\u2019ve had in my 15+ years of gaming headset usage. Highly recommended.", "review_title": "Fantastic.", "review_url": "https://www.amazon.com/gp/customer-reviews/RUOAJ10O8OBT9/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0BSJYM8FF", "reviewed_date": "September 21, 2022", "reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"}, {"author_name": "Thomas", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AG3LM5MV7AZZ23ESSMOKWO47T7SQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "So, right off the bat I'll admit that Razer's programs like Synapse are a bit frustrating, but fortunately they're not necessary for the headset to work. That being said; the Hypersense headphones are extremely comfortable with an easy to adjust design that doesn't pull hair or pinch skin. The ear muffs are soft and feel durable. The head band also sits firmly on your head without digging in. The mic quality is much better than older models where there was a lot less background noise picked up and better clarity. The ability to remove the mic is also a handy feature. Sound is crystal clear and sharp. Noise suppression isn't perfect, but a solid 9/10. I was only able to hear the loudest of noises if I had any sound going through the headset. And the RGB looks great and is very responsive as long as you have the appropriate apps to run it correctly.", "review_title": "An amazing headset", "review_url": "https://www.amazon.com/gp/customer-reviews/R3NCV99ISSZCN4/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0BSJYM8FF", "reviewed_date": "March 05, 2024", "reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"}, {"author_name": "RAFAEL S", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Valeu cada minuto de espera. Headset confort\u00e1vel, com \u00f3timo \u00e1udio e capta\u00e7\u00e3o. Ao plugar o USB no PC, ele pr\u00f3prio instala todos os apps necess\u00e1rios, sendo super intuitivo. Recomendo demais para quem quer conforto e funcionalidade.", "review_title": "Holy cow!", "review_url": null, "reviewed_date": "December 19, 2024", "reviewed_product_variant": "Color: Black | Style: Kraken V3 X"}, {"author_name": "ERIKA CINTORA", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Los utilizo para home office, a\u00edslan perfectamente el sonido y el micr\u00f3fono cancela ruido a la perfecci\u00f3n. Sin duda lo mejor para gaming y trabajar.", "review_title": "Fant\u00e1sticos, est\u00e9ticos y sin falla", "review_url": null, "reviewed_date": "May 11, 2024", "reviewed_product_variant": "Color: Black | Style: Kraken V3"}, {"author_name": "Josu\u00e9 Abraham", "author_profile": null, "badge": "Verified Purchase", "rating": "1.0", "review_text": "Los audifonos tienen un audio decente, pero generan MUCHA est\u00e1tica y eso se ve reflejado en los sonidos \u201cchirriantes\u201d que muy a menudo se escuchan, es la primera vez que unos aud\u00edfonos me generan un sonido tan desagradable, otro aspecto a tomar en cuenta es que su micr\u00f3fono es HORRIBLE pues se escucha muy bajo y con calidad de audio pobre, la verdad no vale la pena tener estos aud\u00edfonos solo por la tecnolog\u00eda h\u00e1ptica, si estas buscando audifonos te recomiendo los EPOS H3, son de mejor calidad y rondan por el mismo precio", "review_title": "Mucha sonido de est\u00e1tica", "review_url": null, "reviewed_date": "March 25, 2023", "reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"}, {"author_name": "Dave D", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "At first I was skeptical, they were a bit tight and there was a screeching noise that would happen occasionally. Over time they've loosened up and a software update got rid of the noise. I think they're awesome. You could save money and go without the hypersense, but the build quality and materials used is nice, everyone has been complimenting my microphone sound, and I enjoy the sound I get, especially spatial audio while gaming. I definitely recommend as a gaming headset, not necessarily for music listening. If you do listen to music, you'll enjoy the bass in bass heavy songs. Update the firmware as soon as you get them**", "review_title": "Very nice gaming headphones", "review_url": null, "reviewed_date": "March 05, 2023", "reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"}, {"author_name": "victor craveiro", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "really nice product", "review_title": "the headphone in the world", "review_url": null, "reviewed_date": "October 22, 2024", "reviewed_product_variant": "Color: Black | Style: Kraken V3 X"}] | [{"asin": "B09ZW52XSQ", "image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$212.95", "product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360\u00b0 Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch", "rating": "4", "reviews": "1,280", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B084CZX3T1", "image_url": "https://m.media-amazon.com/images/I/31n7Q5+I6UL._AC_UF480,480_SR480,480_.jpg", "price": "$39.95", "product_name": "JBL Quantum 200 - Wired over-ear gaming headset with Voice focus directional flip-up mic and memory foam ear cushions (Black)", "rating": "4", "reviews": "2,358", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDAzMTk1MjQzMjU4MTo6Ojo&url=%2Fdp%2FB084CZX3T1%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB084CZX3T1%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B01H6GUCCQ", "image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$19.99", "product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo", "rating": "4", "reviews": "108,513", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UU"}, {"asin": "B07QNZC9V5", "image_url": "https://m.media-amazon.com/images/I/419PSmh-1yL._AC_UF480,480_SR480,480_.jpg", "price": "$89.95", "product_name": "Razer Kraken Gaming Headset: Lightweight Aluminum Frame - Retractable Noise Isolating Microphone - for PC, PS4, PS5, Switch, Xbox One, Xbox Series X & S, Mobile - 3.5 mm Headphone Jack - Black/Blue", "rating": "4", "reviews": "48,125", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU2NjI1NDc2MTEwMjo6Ojo&url=%2Fdp%2FB07QNZC9V5%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB07QNZC9V5%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0C4ND25FT", "image_url": "https://m.media-amazon.com/images/I/41TSn76LbZL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$37.99", "product_name": "FIFINE PC Gaming Headset, USB Headset with 7.1 Surround Sound, Detachable Microphone, Control Box, 3.5mm Headphones Jack, Over-Ear Wired Headset for PS5/Xbox/Switch, Black-AmpliGame H9", "rating": "4", "reviews": "1,332", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDA1NTQ5NDY1MzUwMjo6Ojo&url=%2Fdp%2FB0C4ND25FT%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0C4ND25FT%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B07XHGLSGF", "image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg", "price": "$32.99", "product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center", "rating": "4", "reviews": "12,179", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU5NzUwMjE2MzkwMjo6Ojo&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B08TBF4S42", "image_url": "https://m.media-amazon.com/images/I/41YfyXuYK3L._AC_UF480,480_SR480,480_.jpg", "price": "$38.99", "product_name": "NUBWO G06 Dual Wireless Gaming Headset with Microphone for PS5, PS4, PC - 23ms Low Latency Audio - 100-Hour of Playtime - 50mm Drivers (Black-Orange)", "rating": "4", "reviews": "11,500", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDAzMjM1NzgxNDgwMjo6Ojo&url=%2Fdp%2FB08TBF4S42%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB08TBF4S42%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDAzMjM1NzgxNDgwMjo6Ojo&url=%2Fdp%2FB08TBF4S42%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB08TBF4S42%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"}, {"asin": "B0DB569DF6", "image_url": "https://m.media-amazon.com/images/I/41MclnC9X4L._AC_UF480,480_SR480,480_.jpg", "price": "$32.99", "product_name": "UHURU Dual Wireless Gaming Headset with Microphone for PS5 PS4 PC: Gaming Headphones with Stereo Sound - 32Hr Battery - Cool RGB", "rating": "4", "reviews": "39", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDY2OTI4MzQ1MDgwMjo6Ojo&url=%2Fdp%2FB0DB569DF6%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0DB569DF6%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B081415GCS", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$119.99", "product_name": "Logitech G733 Lightspeed Wireless Gaming Headset with Suspension Headband, Lightsync RGB, Blue VO!CE mic technology and PRO-G audio drivers - Black", "rating": "4", "reviews": "17,266", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDAwMDUyNjA0NjMwMjo6Ojo&url=%2Fdp%2FB081415GCS%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB081415GCS%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDAwMDUyNjA0NjMwMjo6Ojo&url=%2Fdp%2FB081415GCS%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB081415GCS%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B096VRK6J5", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$33.99", "product_name": "BINNUNE Wireless Gaming Headset with Microphone for PC PS4 PS5, 2.4G Wireless Bluetooth USB Gamer Headphones with Mic for Laptop Computer", "rating": "4", "reviews": "11,435", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDMxMDA0NTQ3MTUwMjo6Ojo&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDMxMDA0NTQ3MTUwMjo6Ojo&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0D4QVXY78", "image_url": "https://m.media-amazon.com/images/I/31IcWSpdOAL._AC_UF480,480_SR480,480_.jpg", "price": "$79.99", "product_name": "OXS Storm G2 Wireless Gaming Headsets, 7.1 Virtual Surround Sound, 3 EQ Modes, 2.4G Low Latency, 50mm Driver, 40H Playtime, RGB Light, Bluetooth 5.3, Compatible with PC, Console, Mobile, Black", "rating": "4", "reviews": "74", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDI4OTgyODE3NzIwMjo6Ojo&url=%2Fdp%2FB0D4QVXY78%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0D4QVXY78%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B09ZW52XSQ", "image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$212.95", "product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360\u00b0 Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch", "rating": "4", "reviews": "1,280", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B07PRVS98X", "image_url": "https://m.media-amazon.com/images/I/41hWVo9yTRL._AC_UF480,480_SR480,480_.jpg", "price": "$49.99", "product_name": "EKSA E900 Pro USB Gaming Headset for PC - Computer Headset with Detachable Noise Cancelling Mic, 7.1 Surround Sound, 50MM Driver - Headphones with Microphone for PS4/PS5, Xbox One, Laptop, Office", "rating": "4", "reviews": "5,119", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDA4MDI0MzYzOTgwMjo6Ojo&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B07XHGLSGF", "image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg", "price": "$32.99", "product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center", "rating": "4", "reviews": "12,179", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDU5NzUwMjE2MzkwMjo6Ojo&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}] | [{"five_star": "69%", "four_star": "12%", "one_star": "8%", "three_star": "6%", "two_star": "4%"}] |
| https://www.amazon.com/Turtle-Stealth-Wireless-Multiplatform-Amplified-Headset/dp/B0DB96KTGL/ref=sr_1_9?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-9&th=1 | B0DB96KTGL | Turtle Beach Stealth 700 Gen 3 Wireless Multiplatform Amplified Gaming Headset for Xbox Series X|S, Xbox One, PC, PS5, Mobile – 60mm Drivers, AI Noise-Cancelling Mic, Bluetooth, 80-Hr Battery – Cobalt | Turtle Beach | Amazon.com | - | 701 | [{"level": 1, "name": "Video Games", "url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"}, {"level": 2, "name": "Xbox One", "url": "/Xbox-One-Games-Consoles-Accessories-Hardware/b/ref=dp_bc_aui_C_2?ie=UTF8&node=6469269011"}, {"level": 3, "name": "Accessories", "url": "/Xbox-One-Hardware-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=6469270011"}, {"level": 4, "name": "Headsets", "url": "/Xbox-One-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=6469291011"}] | 4.4 | USD | 188.37 | 199.99 | - | CrossPlay Dual Transmitter Multiplatform Wireless Audio System - Simultaneous Low-latency 2.4GHz wireless + Bluetooth 5.2 - 60mm Eclipse Dual Drivers for Immersive Spatial Audio - Flip-to-Mute Mic with A.I.-Based Noise Reduction - Long-Lasting Battery Life of up to 80-Hours plus Quick-Charge - Memory Foam Cushions with Glasses-Friendly Technology - Lay-Flat, Steel-Reinforced Design - Swarm II Desktop & Mobile App with Advanced 10-Band EQ - Mappable Wheel & Mode Button for Customizable Functions - Built-in EQ modes plus Advanced Superhuman Hearing | The Turtle Beach Stealth 700 Gen 3 wireless multiplatform gaming headset officially licensed for Xbox Series X|S & Xbox One, and works great with PS5 & PS4, Windows PCs, Steam Deck and mobile is redesigned and feature-packed for a 3rd generation of premium gaming prowess. All-new, and exclusive for the Stealth 700 Gen 3, the CrossPlay Wireless Audio System includes two USB wireless transmitters, and using the CrossPlay button on the headset, you can easily switch between your favorite console and PC without having to move transmitters or connect cables. Plus, simultaneous Bluetooth 5.2 lets you connect directly to mobile devices while playing on console or PC so you can chat with friends on Discord or listen to your favorite music from your phone while still hearing game audio on your console or PC. Huge, 60mm Eclipse Dual Drivers are the largest speakers in their class – and the difference is clear with unparalleled acoustic precision and deep bass for immersive spatial audio on console and PC. The dual drivers are designed with a distinct woofer and tweeter to separate low and high frequencies for vastly improved audio detail over conventional drivers. A massive battery life of up to 80-hours is the best in its class for more gametime and less downtime, plus a quick 15-minute charge gets you back in action with 3 hours of battery life. Completely redesigned for the 3rd generation of the Stealth 700, the all-new uni-directional flip-to-mute microphone features A.I. noise reduction to ensure ultra-clear mic quality with the quietest background possible. Using the Swarm II companion app for desktop & mobile devices, you can adjust noise gate, sensitivity, monitoring levels, and choose from four different mic presets, or even make your own with a custom 10-band microphone EQ. And to dial in the 60mm Eclipse drivers to your liking you can use the Swarm II app to cycle through four audio EQ presets, create up to five custom presets with a 10-band audio EQ, adjust game & chat volume mix, chat boost, plus activate, or adjust Turtle Beach exclusive Advanced Superhuman Hearing sound setting. And for added customization, you can remap the wheel & mode button on the headset to different functions to better suit your gameplay. A redesigned headband & ear cushions let you dominate for hours with unmatched comfort. Plush memory foam ear cushions wrapped in a hybrid of leatherette & athletic-weave fabric keep your ears cool and lend to enhanced noise isolation. Plus, the cushions feature ProSpecs glasses relief technology, so whether you wear gaming or prescription glasses, you’ll enjoy the same great comfort. For long-lasting durability and adjustability, the Stealth 700 Gen 3 features a steel-reinforced headband, paired with an adjustable lay-flat design. CrossPlay Multi-platform Wireless Audio System Dual USB wireless transmitters and a single button on the headset allow you to quickly switch between your favorite console or PC without having to move transmitters or connect cables. Simultaneous Wireless + Bluetooth Connect to your gaming console or PC, as well as your smartphone or tablet at the same time with simultaneous 2.4GHz Wireless & Bluetooth 5.2. With dual wireless capabilities, you can chat with friends on Discord, or listen to your favorite music from your phone and still hear game audio from your console or PC. Plus, with independent volume controls, you can easily adjust and mix the levels of wireless and Bluetooth audio sources. Stunning Audio Clarity The largest in their class, our patented 60mm Eclipse dual drivers deliver immersive soundscapes with unparalleled precision and deep bass. The dual drivers are designed with a distinct woofer and tweeter to separate low and high frequencies for vastly improved audio detail over conventional drivers. Exceptional Microphone Performance Completely redesigned for the third generation of Stealth 700, the all-new uni-directional, flip-to-mute microphone features A.I. noise reduction to ensure the quietest background possible. Plus, using the Swarm II app for desktop & mobile, you can further refine microphone specs to dial-in your exact preferences. Unstoppable, 80-Hour Battery Life Power through gaming sessions with a massive battery life of up to 80 hours. Plus, with a quick-charge, you can get back in the action right away with 3 hours of battery life in just a 15-minute charge. Superb Comfort, Unmatched Durability Designed for a comfortable fit that’s built to last through every battle, the Stealth 700 Gen 3 features hybrid leatherette & athletic-weave fabric wrapped memory foam cushions, and durable steel-reinforced construction. Plus, the cushions feature ProSpecs glasses relief technology so every gamer can enjoy the same great comfort. Anywhere Audio Customization Connect to the Swarm II companion app for PC, iOS, or Android to access extensive audio enhancements* including a dynamic 10-band EQ with up to five custom presets you can design based on the type of games or music you listen to. You can also program the mappable wheel and mode button, adjust mic sensitivity, noise gate, monitoring levels and more. Additionally, Swarm II supports over the air firmware updates to ensure your Stealth 700 Gen 3 is always up to date. *Select advanced audio features may not be supported in Bluetooth mode. Remappable Wheel & Mode Button Customize your headset with a remappable wheel & mode button that can be assigned to distinct functions based on your gaming style using the Turtle Beach Swarm II app. Functions for the Mode button include EQ preset selection, multimedia controls on PC, noise gate and chat boost. And the secondary wheel can be reassigned to control Game/Chat Mix, Variable Mic Monitoring, Bass & Treble Boost levels and Noise Gate. Advanced Superhuman Hearing Advanced Superhuman Hearing brings the same great battlefield advantage of Superhuman Hearing, but now with additional adjustability. In the Swarm II app, toggle between three different preset levels and adjust the intensity of Superhuman Hearing, to dial-in the perfect sound for a wide range of games. Easy Access to Audio Presets & Variable Mic Monitoring Enhance your gameplay experience at the touch of a button with four Turtle Beach audio presets including Bass Boost, Signature Sound, Treble Boost, and Vocal Boost. Avoid shouting thanks to variable mic monitoring (or sidetone) which allows you to hear and adjust your voice through the headset while you chat. | In Stock | - | TBS-2101-25 | edition: Stealth 700 XB, color: Cobalt | Video Games > Xbox One > Accessories > Headsets | [{"ASIN": "B0DB96KTGL", "Age Range (Description)": "Teen, Adult", "Amazon Best Sellers Rank": "#188 in Video Games , #6 in Xbox One Headsets , #11 in Xbox Series X & S Accessories", "Audio Driver Size": "60 Millimeters", "Audio Driver Type": "Dynamic Driver", "Batteries": "1 Lithium Polymer batteries required. (included)", "Battery Life": "80 Hours", "Bluetooth Range": "60 Feet", "Bluetooth Version": "5.2", "Cable Feature": "Detachable", "Charging Time": "4 Hours", "Compatible Devices": "Cellphones, Gaming Consoles, Tablets, Laptops, Desktops", "Connectivity Technology": "Wireless", "Control Method": "App", "Control Type": "Touch Control", "Controller Type": "Button, Touch", "Country of Origin": "Vietnam", "Date First Available": "August 19, 2024", "Earpiece Shape": "Oval", "Frequency Range": "2 Hz - 20,000 Hz", "Frequency Response": "20 KHz", "Included Components": "Wireless Gaming Headset, 0.7m / 2.3ft Charging Cable (USB-A to USB-C), Two CrossPlay USB Wireless Transmitters, Quick Start Guide", "Is Autographed": "No", "Item Weight": "14.4 ounces", "Item model number": "TBS-2101-25", "Manufacturer": "Turtle Beach", "Material": "Aluminum, Plastic, Metal, Thermoplastic Elastomer (TPE), Acrylonitrile Butadiene Styrene (ABS)", "Model Name": "700XG3C", "Noise Control": "Passive Noise Cancellation", "Number of Items": "1", "Number of Power Levels": "1", "Number of USB 2 Ports": "1", "Package Type": "Standard Packaging", "Product Dimensions": "7.87 x 6.81 x 3.7 inches", "Recommended Uses For Product": "Gaming", "Sensitivity": "94 dB", "Series Number": "3", "Specific Uses For Product": "Gaming", "Theme": "Video Game", "UPC": "731855021062", "Water Resistance Level": "Not Water Resistant", "Wireless Communication Technology": "Bluetooth, Wi-Fi"}] | [{"Brand": "Turtle Beach", "Color": "Cobalt", "Ear Placement": "Over Ear", "Form Factor": "Over Ear", "Impedance": "33 Ohm"}] | https://m.media-amazon.com/images/I/51I7-qv8A9L._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/61ay9UC1DJL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51YmHZbxedL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/61Lh4YWsiUL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51m0ulsaR+L._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/61tcNVjcLFL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/61JEY3nCh5L._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/61LkHSq2n4L._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51Z+x7xxqQL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51ps9csBFeL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51cs4O3NgjL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/511+gL8wBJL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51kEpHDEYEL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/71T81HAkPpL._AC_SL1500_.jpg, https://m.media-amazon.com/images/I/51kwm601mOL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/41CcoTIKdhL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/41XZ5xeNMPL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51gYjmTnzuL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51bCmY84IBL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/31Tt-aF2fYL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/41qo5tW8NUL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51y02pbenGL._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/51Jd6XVN76L._AC_SL1000_.jpg, https://m.media-amazon.com/images/I/41xKzUMgo+L._AC_SL1000_.jpg | [{"asin": "B0CYWLSCFW", "edition": "Stealth 500 XB"}, {"asin": "B0DB9HZVZV", "edition": "Stealth 700 XB"}, {"asin": "B0DB96KTGL", "edition": "Stealth 700 XB"}, {"asin": "B0DVZ9ZDMD", "edition": "Stealth 500 XB"}, {"asin": "B0CYWFH5Y9", "edition": "Stealth 600 XB"}, {"asin": "B0CYWDPYF4", "edition": "Stealth 600 XB"}, {"asin": "B0CYWLSCFW", "color_name": "Black"}, {"asin": "B0DB9HZVZV", "color_name": "Black"}, {"asin": "B0DB96KTGL", "color_name": "Cobalt"}, {"asin": "B0DVZ9ZDMD", "color_name": "Black/Arctic Camo"}, {"asin": "B0CYWFH5Y9", "color_name": "Black"}, {"asin": "B0CYWDPYF4", "color_name": "White"}] | [{"color_name": ["Black", "Black/Arctic Camo", "Cobalt", "White"], "edition": ["Stealth 500 XB", "Stealth 600 XB", "Stealth 700 XB"]}] | [{"link": "https://www.amazon.com/High-Performance-Wireless-Controller-Licensed-Xbox-X/dp/B0CJVQFZ1S/ref=pd_bxgy_d_sccl_1/139-3471011-9068846?pd_rd_w=5bw0d&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=V9NQ5JPN2WB7W3HWZYDM&pd_rd_wg=MOkSO&pd_rd_r=6803a5fa-0bba-4a1a-996a-8c96a480b9ad&pd_rd_i=B0CJVQFZ1S&psc=1", "price": "$169.99", "title": "Turtle Beach Stealth Ultra High-Performance Wireless Gaming Controller Licensed for Xbox Series X|S, Xbox One, Windows PC & Android \u2013 LED Dashboard, Charge Dock, RGB Lighting, 30-Hr Battery, Bluetooth, Black"}] | [{"author_name": "Dylan De Koning", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEQQOXYFACJWX6VNJWZQCLYRBJLA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I was surprised. I used a Turtle Beach headset years ago and was not happy with my experience. You hear that Turtle Beaches are kinda looked down upon, like Alienware computers. I was happily surprised with the quality of the headset. I was using a Steel Series Arctics 7x for multiplatform and Bluetooth compatibilities. It was a small headset that was very uncomfortable to wear, especially with the headband pressing against my head all the time. The audio was not impressive at all either. With the stealth 700, I couldn't help but open the box with my jaw agape. The cushions are so nice to wear, the drivers are bass heavy and very pleasant to listen to while playing war games like Battlefield. The metal frame makes me feel safe when handling the headset, and it was pretty easy to set up. The firmware update took awhile, but so far no problems, even with connectivity. Overall, very satisfied with the product. Some people mention my mic quality went down, but I'm just happy it's not very sensitive and picking up on every single background noise like my other one. Highly recommend", "review_title": "Actual Premium Headset", "review_url": "https://www.amazon.com/gp/customer-reviews/RCGQYDQ9YSUVV/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DB96KTGL", "reviewed_date": "January 20, 2025", "reviewed_product_variant": "Color: Black | Edition: Stealth 700 XB"}, {"author_name": "Amazon Customer", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHTLPVUQSJSPVQJQ2OKIQ2DT43KQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "This headset sounds great. I had the Steelseries Arctis 7x and my friends complained about the mic dropping out randomly. So I tried these out and the sound and mic is amazing. My friends even said it sounds more like me. Pros: Sound is punchy with deep bass and high treble. I reomend using the Bass and Treble preset. Sounds the best for footsteps. Comes with two dongles so I just have to hit a button to switch from Xbox to my PC. You can also have your phone connected to answer calls or listen to music while you game. The headset has 3 volume controls, the regular volume, chat to game mixer, and the Bluetooth volume. Last is the mic. My friend has the gen 2 version and it sounds like we are talking on the phone, he says I sound the same. This has been the best mic I've had on a headset. Cons: The app is terrible. There aren't numbers on the mixer so you have to figure it out on your own. This is very difficult to figure out if you're not a soundphile person. The presets aren't the greatest. The best I found is the bass and treble preset. The super human hearing setting is awful. It has legacy, gunfire, and footsteps. On the Xbox it just kills the sound, the footsteps and gunfire are punchier on the other presets with this feature turned off. The setting basically sounds like really bad earbuds. The other problem is firmware updates. This requires you to have the dongles plugged into both devices with them turned on. So if you don't have a PC, forget about updating the firmware. The last issue is where the volume controls are. When I wear a hoodie my hood will randomly change the chat mixer. Not a big problem but something to be aware of. Besides the app and firmware, this headset is great. It's the best one I have owned and sounds amazing on all fronts.", "review_title": "Great sound and Mic.", "review_url": "https://www.amazon.com/gp/customer-reviews/R12NSGVMBQKO7Y/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DB96KTGL", "reviewed_date": "February 07, 2025", "reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"}, {"author_name": "Lady A", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEC5JUIE663DK3MF56YLHPRU7WEA/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "I have owned 600s and 700s. The 600 were fine with less quality material but the disconnect issues for both the of them were so annoying. I read a review before getting these again and someone said that issue was fixed so i decided to take a chance. So far, so good. Good quality sound, material, and comfort for the price and zero drops unless I walk way too far to even be gaming. The only real issue was upgrading the firmware because you have to update the dongles and headset at the same time or it won't update. If you have a pc nearby your fine but I didn't. It took many attempts due to connection drops and after a full day, I finally got it to take! Since then, all good. Headset can be used for PS, Xbox, and PC, it has Bluetooth and separately dials for volume and chat/game sound. Charge last a long time too, I didn't have to recharge for a few days. So far, this is a winner! Now if they can last a few years I will be thoroughly impressed!", "review_title": "So far so good!", "review_url": "https://www.amazon.com/gp/customer-reviews/R302AALWQW0K5N/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DB96KTGL", "reviewed_date": "December 18, 2024", "reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"}, {"author_name": "Jocelyn", "author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFVLUOBLN4OFDSILJ5HQQSCSDIEQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8", "badge": "Verified Purchase", "rating": "5.0", "review_text": "These are a really nice quality for the price. They work exactly as they should and fit comfortably. They even have a noise cancellation smart feature to where if you are chewing with the mic out, it will automatically cancel that noise so your buddies can't hear the sound. So if you like to snack while you game, that's a nice feature.", "review_title": "Great Quality", "review_url": "https://www.amazon.com/gp/customer-reviews/RYZAAOMHKB2LB/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DB96KTGL", "reviewed_date": "January 14, 2025", "reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"}, {"author_name": "Chad", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "I've owned Turtle Beach headsets for over a decade. This set is EASILY their best thus far! The 600 had great sound, this set is even better. It has two usb transmitters (dedicated xbox and pc) and there's a button the the set to swap between them. It's very seamless and works really well. The 600 series would lose connection as I walked around, this set does not. Conversations are very clear, both Bluetooth and in game. The major problem with TurtleBeach has always been longevity. The joints at the earcuffs have always broken away on me. This set is completely redesigned and very comfortable. I'll update in a year. So far, they're absolutely worth every cent!", "review_title": "Best of Turtle Beach", "review_url": null, "reviewed_date": "January 17, 2025", "reviewed_product_variant": "Color: Black | Edition: Stealth 700 XB"}, {"author_name": "Yony gilmart", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Los aud\u00edfonos son muy perfectos Lo unci\u00f3 malo fue la paqueteria Fue todo un desastre Se atrasaron y perdieron el paquete Pero el producto funciona muy bien", "review_title": "Aud\u00edfonos", "review_url": null, "reviewed_date": "January 03, 2025", "reviewed_product_variant": "Color: Black | Edition: Stealth 700 XB"}, {"author_name": "anthony salmon", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Used this with my xbox, and sound quality is brilliant, design is nice, mic and chat quaily is great as well, so easy to connect and can be used with multiple devices, I played my xbox one evening for 4 hours and they were super comfortable, my ears didn't sweat or start to hurt, overall this headset is excellent for the price and if your just a general gamer they are perfect, and with the super sound addition you can hear back ground noise like foot steps really clear, big help in games like call of duty.", "review_title": "Great head set.", "review_url": null, "reviewed_date": "February 01, 2025", "reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"}, {"author_name": "Dylan gierczynski", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Re\u00e7u \u00e0 main propre niveau qualit\u00e9 impressionnante je recommande se produit.", "review_title": "Recommande", "review_url": null, "reviewed_date": "January 18, 2025", "reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"}, {"author_name": "Simone Montana Lampo", "author_profile": null, "badge": "Verified Purchase", "rating": "5.0", "review_text": "Nel suo genere uniche bluetooth, xbox e pc insieme! Audio imbattibile acquisto consigliato!", "review_title": "Cuffie perfette!", "review_url": null, "reviewed_date": "January 04, 2025", "reviewed_product_variant": "Color: Black | Edition: Stealth 700 XB"}] | [{"asin": "B09ZW52XSQ", "image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$212.95", "product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360\u00b0 Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch", "rating": "4", "reviews": "1,280", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"}, {"asin": "B0DB9Y81C1", "image_url": "https://m.media-amazon.com/images/I/31+l4UYqQfL._AC_UF480,480_SR480,480_.jpg", "price": "$171.23", "product_name": "Turtle Beach Stealth 700 Gen 3 Wireless Multiplatform Amplified Gaming Headset for PC, PS5, PS4, Mobile \u2013 24-bit Audio, 60mm Drivers, High-Bandwidth Microphone, Bluetooth, 80-Hr Battery \u2013 Black", "rating": "4", "reviews": "91", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjMwMDM4MzIwOTk4NDIwMjo6Ojo&url=%2Fdp%2FB0DB9Y81C1%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0DB9Y81C1%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"}, {"asin": "B0B15QM5LL", "image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=", "price": "$153.99", "product_name": "SteelSeries Arctis Nova 7 Wireless Multi-Platform Gaming Headset \u2014 Neodymium Magnetic Drivers \u2014 2.4GHz + Mixable Bluetooth \u2014 38Hr USB-C Battery \u2014 ClearCast Gen2 AI Mic \u2014 PC, PS5, Switch, VR, Mobile", "rating": "4", "reviews": "5,892", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjIwMDExMzMyNjMyNzQ5ODo6Ojo&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjIwMDExMzMyNjMyNzQ5ODo6Ojo&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"}, {"asin": "B0DB7ZW7J4", "image_url": "https://m.media-amazon.com/images/I/41CcIOb-fOL._AC_UF480,480_SR480,480_.jpg", "price": "$279.99", "product_name": "Logitech G Astro A50 Omni-Platform Wireless Gaming Headset + Base Station for PS5, Xbox, PC: PLAYSYNC Audio Switcher, <16 bit/48kHz (Console), <24 bit/48 kHz (PC), 24hr Battery, 2.4GHz & BT - Black", "rating": "4", "reviews": "633", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjMwMDUwNjk4OTYwMDEwMjo6Ojo&url=%2Fdp%2FB0DB7ZW7J4%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0DB7ZW7J4%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"}, {"asin": "B09ZWKD9TF", "image_url": "https://m.media-amazon.com/images/I/312MvjLsRXL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png", "price": "$306.99", "product_name": "SteelSeries Arctis Nova Pro Wireless Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Active Noise Cancellation Infinity Power System - Stealth Mic - Xbox, PC, PS5, PS4, Switch, Mobile", "rating": "4", "reviews": "5,928", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjIwMDA1OTIyNzIxMDE5ODo6Ojo&url=%2Fdp%2FB09ZWKD9TF%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZWKD9TF%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"}, {"asin": "B0CDHH595L", "image_url": "https://m.media-amazon.com/images/I/41ahQMbSOEL._AC_UF480,480_SR480,480_.jpg", "price": "$85.99", "product_name": "RIG 600 PRO HX Dual Wireless Universal Gaming Headset with Bluetooth for Xbox Series X|S, Xbox One, Playstation PS4, PS5, Nintendo Switch, PC, USB & Mobile", "rating": "4", "reviews": "97", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjMwMDA4NTgzNzUxMzYwMjo6Ojo&url=%2Fdp%2FB0CDHH595L%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0CDHH595L%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"}, {"asin": "B098TV8C93", "image_url": "https://m.media-amazon.com/images/I/31XW2VYbH7L._AC_UF480,480_SR480,480_.jpg", "price": "$89.99", "product_name": "HyperX CloudX Stinger Core \u2013 Wireless Gaming Headset, for Xbox Series X|S and Xbox One, Memory foam & Premium Leatherette Ear Cushions, Noise-Cancelling,Black", "rating": "4", "reviews": "34,211", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjMwMDE4NjEyOTQxOTYwMjo6Ojo&url=%2Fdp%2FB098TV8C93%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB098TV8C93%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"}, {"asin": "B07NH6Q4LB", "image_url": "https://m.media-amazon.com/images/I/311pg5gMKZL._AC_UF480,480_SR480,480_.jpg", "price": "$34.95", "product_name": "Turtle Beach Recon 70 Gaming Headset - Nintendo Switch, Xbox Series X|S, Xbox One, PS5, PS4, PlayStation, Mobile, & PC with 3.5mm - Flip-Up Mic, 40mm Speakers, Stereo \u2013 Black", "rating": "4", "reviews": "84,633", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA2MjQyOTgzODUzMDI6Ojo6&url=%2Fdp%2FB07NH6Q4LB%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB07NH6Q4LB%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0CYWD9PSM", "image_url": "https://m.media-amazon.com/images/I/31MVF59bG3L._AC_UF480,480_SR480,480_.jpg", "price": "$89.99", "product_name": "Turtle Beach Stealth 600 Gen 3 Wireless Multiplatform Amplified Gaming Headset for PS5, PS4, PC, Mobile \u2013 Bluetooth, 80-Hr Battery, AI Noise-Cancelling Flip-to-Mute Mic, 50mm Speakers \u2013 Black", "rating": "4", "reviews": "468", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAxNzA0MzQ2ODk1MDI6Ojo6&url=%2Fdp%2FB0CYWD9PSM%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0CYWD9PSM%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0DKS9NYZM", "image_url": "https://m.media-amazon.com/images/I/31eb+eD9oVL._AC_UF480,480_SR480,480_.jpg", "price": "$245.37", "product_name": "Turtle Beach Victrix Pro KO Leverless All Button Fight Stick, Officially Licensed for Xbox Series X|S, Xbox One, Windows 10/11 PC, Customizable eSports Tournament Ready Controller, Gray", "rating": "3", "reviews": "8", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1MTkzMzcwMzA0MDI6Ojo6&url=%2Fdp%2FB0DKS9NYZM%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0DKS9NYZM%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0CZX7MB48", "image_url": "https://m.media-amazon.com/images/I/31DesTdt70L._AC_UF480,480_SR480,480_.jpg", "price": "$87.00", "product_name": "Turtle Beach Stealth 600 Gen 3 Wireless Multiplatform Amplified Gaming Headset for PC, PS5, PS4, Mobile \u2013 Bluetooth, 80-Hr Battery, AI Noise-Cancelling Flip-to-Mute Mic, Waves 3D Audio \u2013 Black", "rating": "4", "reviews": "293", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAxNzA0Mjg1OTgyMDI6Ojo6&url=%2Fdp%2FB0CZX7MB48%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0CZX7MB48%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B0CJVQFZ1S", "image_url": "https://m.media-amazon.com/images/I/41x-FF2SXwL._AC_UF480,480_SR480,480_.jpg", "price": "$169.99", "product_name": "Turtle Beach Stealth Ultra High-Performance Wireless Gaming Controller Licensed for Xbox Series X|S, Xbox One, Windows PC & Android \u2013 LED Dashboard, Charge Dock, RGB Lighting, 30-Hr Battery, Bluetooth, Black", "rating": "3", "reviews": "1,512", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAwOTg2MjQ4OTQ5MDI6Ojo6&url=%2Fdp%2FB0CJVQFZ1S%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0CJVQFZ1S%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}, {"asin": "B09SQ2L5TN", "image_url": "https://m.media-amazon.com/images/I/31fozsu8esL._AC_UF480,480_SR480,480_.jpg", "price": "$110.45", "product_name": "Turtle Beach Stealth 600 Gen 2 USB Wireless Amplified Gaming Headset - Licensed for Xbox - 24+ Hour Battery, 50mm Speakers, Flip-to-Mute Mic, Spatial Audio - Arctic Camo", "rating": "4", "reviews": "145", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA2NTE4MjYyODk2MDI6Ojo6&url=%2Fdp%2FB09SQ2L5TN%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB09SQ2L5TN%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy%26smid%3DA1FCRFKT22GDXL"}, {"asin": "B006W41W82", "image_url": "https://m.media-amazon.com/images/I/41D0RxWgrYL._AC_UF480,480_SR480,480_.jpg", "price": "$222.99", "product_name": "Turtle Beach Ear Force XP300 Wireless Gaming Headset - Xbox 360", "rating": "3", "reviews": "278", "url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAwMTEwNDY2NjM3MDI6Ojo6&url=%2Fdp%2FB006W41W82%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB006W41W82%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"}] | [{"five_star": "74%", "four_star": "9%", "one_star": "8%", "three_star": "5%", "two_star": "4%"}] |
[
{
"asin": "B0C4F9JGTJ",
"attributes": "color: White",
"availability_status": "In Stock",
"available_quantity": null,
"brand": "Ozeino",
"category": [
{
"level": 1,
"name": "Video Games",
"url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"
},
{
"level": 2,
"name": "Legacy Systems",
"url": "/Systems-Games/b/ref=dp_bc_aui_C_2?ie=UTF8&node=294940"
},
{
"level": 3,
"name": "PlayStation Systems",
"url": "/b/ref=dp_bc_aui_C_3?ie=UTF8&node=23563592011"
},
{
"level": 4,
"name": "PlayStation",
"url": "/PlayStation-Games/b/ref=dp_bc_aui_C_4?ie=UTF8&node=229773"
},
{
"level": 5,
"name": "Accessories",
"url": "/Accessories-PlayStation-Hardware/b/ref=dp_bc_aui_C_5?ie=UTF8&node=15891181"
}
],
"currency": "USD",
"frequently_bought_together": [
{
"link": "https://www.amazon.com/Gtheos-Bluetooth-Headphones-Detachable-Microphone/dp/B0B4B2HW2N/ref=pd_bxgy_d_sccl_1/138-1533047-4336725?pd_rd_w=0e6MV&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=3HYQN9N1DWJ06DEX71N8&pd_rd_wg=oBtem&pd_rd_r=6a03dfba-02b7-4e7d-b756-9adaa7f5ce50&pd_rd_i=B0B4B2HW2N&psc=1",
"price": "$33.99",
"title": "Gtheos 2.4GHz Wireless Gaming Headset for PS5, PS4 Fortnite & Call of Duty/FPS Gamers, PC, Nintendo Switch, Bluetooth 5.3 Gaming Headphones with Noise Canceling Mic, Stereo Sound, 40+Hr Battery -White"
},
{
"link": "https://www.amazon.com/OIVO-Controller-Compatible-Playstation-Indicators/dp/B08LZGPPBH/ref=pd_bxgy_d_sccl_2/138-1533047-4336725?pd_rd_w=0e6MV&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=3HYQN9N1DWJ06DEX71N8&pd_rd_wg=oBtem&pd_rd_r=6a03dfba-02b7-4e7d-b756-9adaa7f5ce50&pd_rd_i=B08LZGPPBH&psc=1",
"price": "$19.99",
"title": "OIVO PS5 Controller Charger PS5 Accessories Kits with Fast Charging AC Adapter, Controller Charging Stand for PlayStation 5, Docking Station Replacement for DualSense Charging Station"
}
],
"full_description": "Previous page Next page 1 Quick Flexible Control 2 Noise Cancelling Mic 3 Amazing Battery Life 4 Soft Memory Foam If low power remind, How long can it use? . If remind low power, at least 10-20 mins left . And we suggest you can charge for 10 mins, then you can play at least for 100 mins . 10 mins charged, 100 mins used Can I use Bluetooth mode with PC and PS5/4? Bluetooth function doesn't directly support PS5, PS4,PC, additional 「USB Bluetooth Adapter」 is required (not included), recommend to use the 2.4G USB mode in PS5, PS4, PC devices. How do I mute the microphone? 1. Turn on/off the mic : Double-click the button \"+\" . 2. Check the mute setting of your device. 3. Directly to ask seller. (We always here) How to connect the PS5/PS4? 1.Connect the USB into USB port on PS4/5 main box 2.Setting headset to 2.4GHz mode 2.Console settings: Main menu-Settings-Devices-Audio-Audio devices-Set input & output device to OW810-Set output to headphones to all audion-Set volume control to 100% Is this headset with wired mode? · We attached a 3.5mm cable, when headset is low power, wired mode could be used for urgent · Note: Our 3.5mm cable & USB transmiter not compatible with xbox series s.",
"highlighted_specifications": {
"Brand": "Ozeino",
"Color": "White",
"Ear Placement": "Over Ear",
"Form Factor": "Over Ear",
"Impedance": "32 Ohm"
},
"image_urls": [
"https://m.media-amazon.com/images/I/71nUYWaf0RL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/816uvsDE8rL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/81RD5G0eFfL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71Lw8KkOo2L._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/7121w4lIQvL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/81FiSCzfkZL._AC_SL1500_.jpg"
],
"model": "OW810",
"name": "2.4GHz Wireless Gaming Headset for PC, Ps5, Ps4 - Lossless Audio USB & Type-C Ultra Stable Gaming Headphones with Flip Microphone, 40-Hr Battery Gamer Headset for Switch, Laptop, Mobile, Mac",
"product_category": "Video Games > Legacy Systems > PlayStation Systems > PlayStation > Accessories",
"product_information": {
"ASIN": "B0C4F9JGTJ",
"Age Range (Description)": "Adult",
"Amazon Best Sellers Rank": "#23 in Video Games , #1 in PlayStation 2 Accessories , #1 in PlayStation Accessories , #3 in PlayStation 5 Headsets",
"Audio Driver Size": "50 Millimeters",
"Audio Driver Type": "Dynamic Driver",
"Audio Latency": "20 Milliseconds",
"Batteries": "1 Lithium Metal batteries required. (included)",
"Battery Life": "40 Hours",
"Bluetooth Range": "15 Feet",
"Bluetooth Version": "5.3",
"Cable Feature": "Detachable",
"Charging Time": "2.98 Hours",
"Compatible Devices": "playstation_2, PlayStation_5, playstation, nintendo_switch, playstation_4",
"Connectivity Technology": "Wireless",
"Control Method": "Touch",
"Control Type": "Volume Control",
"Controller Type": "Touch",
"Country of Origin": "China",
"Date First Available": "May 8, 2023",
"Earpiece Shape": "Circle",
"Headphones Jack": "3.5 mm Jack",
"Included Components": "1* Wireless Gaming Headset Black, 1* USB & Type -C Transmitter, 1* User Manual, 1* 3.5 mm Aux Cable & Charging Cable",
"Is Autographed": "No",
"Item Weight": "1.08 pounds",
"Item model number": "OW810",
"Manufacturer": "Ozeino",
"Material": "Plastic",
"Model Name": "OW810",
"Noise Control": "Sound Isolation",
"Number of Items": "1",
"Package Type": "Standard Packaging",
"Product Dimensions": "5.91 x 3.94 x 7.87 inches",
"Recommended Uses For Product": "Gaming",
"Specific Uses For Product": "Enjoy the game, music",
"Style": "Modern",
"Theme": "Video Game",
"Unit Count": "1.0 Count",
"Wireless Communication Technology": "USB-C&A,Bluetooth"
},
"product_reviews": [
{
"author_name": "Charity Wiberg",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEJZQCDLKS2BWTY4V4LETRFFF6YQ/ref=cm_cr_dp_d_gw_pop?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I have been using this headset for a couple months now and can say I am VERY satisfied. At a budget-friendly price, they deliver impressive sound performance. The build quality feels sturdy, yet lightweight, making them durable without being heavy on the head. They are also extremely comfortable will nice ear muffs. While also having a nice clean color for both the base and LED’s. Its Bluetooth is amazing. I was able to connect it to a Roku TV, laptop, iPhone, and iPad. It remains well connected even after traveling a far distance away from a device. Allowing for music sessions while cleaning. Buttons were easy to use a simple power on and volume adjustment system that was straightforward to use. I overall I recommend these headphones. They have good sound quality for games and it’s good quality for the price.",
"review_title": "Affordable, Quality, And Comfort",
"review_url": "https://www.amazon.com/gp/customer-reviews/R2MN7XJDFQDWED/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ",
"reviewed_date": "January 09, 2025",
"reviewed_product_variant": "Color: White"
},
{
"author_name": "Marjorie",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFPQY5LOYGKB6FYKTSFJPQIXHI5Q/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I bought this Bluetooth headset for my son as a Christmas gift to use with his PS4, and it has exceeded all expectations! He absolutely loves it and says it’s the best headset in the world. The sound quality is incredible, with crystal-clear audio and great bass, making his gaming experience immersive and enjoyable. The mic picks up his voice perfectly, so he has no trouble communicating with his friends during multiplayer games. The headset is also super comfortable, even during long gaming sessions, and the battery life is outstanding—it lasts all day without needing a recharge. Setup was quick and easy, and it connected to his PS4 seamlessly. He hasn’t stopped raving about it, and I’m thrilled I found something he enjoys so much. Highly recommend this headset to any gamer out there—it’s worth every penny!",
"review_title": "Best headset ever",
"review_url": "https://www.amazon.com/gp/customer-reviews/R10ONB3FT7J2MM/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ",
"reviewed_date": "December 29, 2024",
"reviewed_product_variant": "Color: White"
},
{
"author_name": "Professor Anthrax & The Witch",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEXAODXMPHBNDELU76IBTQB2RD2A/ref=cm_cr_dp_d_gw_pop?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "These belong to my wife. She has had these headphones for over six months of constant use. She works a job that requires 8-11 hours per day of use or standby (powered on). She averages 2-4 hours per day of talk time. She tells me these headphones are, and continue to be, very comfortable to use; and the sound quality through the headphones is excellent, with no distortion. She says the microphone gain is also good; she has never had anyone complain they couldn't hear her, like her original headset. Even after over six months of use they are in excellent condition, showing no signs of wear. She uses them primarily with the 2.5 GHz connection, although the few times she used the Bluetooth connection they have also connected quickly and flawlessly. She never had an issue with them running out of charge while working; although she does plug them in each day after work. Overall a decent quality product for the price.",
"review_title": "Comfortable, Good sound quality, Good Microphone quality, Good battery life.",
"review_url": "https://www.amazon.com/gp/customer-reviews/R3L9XNTV2NJH2P/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ",
"reviewed_date": "February 04, 2025",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Cass",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AG6IGXL5SWAOVBOLZ3X7LQOPMDDQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Bought these for my husband so he can ignore his wife and kids with ease (lol) while playing his games. They have great noise cancellation, and he says the mute feature button for the mic is “exclusive” and easy to use quickly while dunking on his opponents or trying to cut off the sound of children screaming in the background. The led lights are sick. Bluetooth is easy to set up and pairs effortlessly. Battery life is incredible. All around good buy. They’ve outlasted several other inferior products by a mile and is quite durable.",
"review_title": "Extraordinary Headphones, with great quality at a great price!",
"review_url": "https://www.amazon.com/gp/customer-reviews/R1F19H0FUUPW1A/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ",
"reviewed_date": "January 08, 2025",
"reviewed_product_variant": "Color: White"
},
{
"author_name": "Jennifer",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHGNQVNCPGABQ3XZHGKZTDILTCHA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I recently purchased this headset for my son, and it’s been an absolute game-changer! It works flawlessly with the PS5, delivering great sound quality and crystal-clear communication. The noise-cancellation feature really helps him immerse in the game without distractions, and the comfort level is top-notch—perfect for those long gaming sessions. The durability is impressive as well. After a few weeks of heavy use, it’s holding up great, which is a relief for me as a parent. The built-in mic works perfectly for in-game chats, making it easy to communicate with friends or teammates. Overall, this headset has exceeded expectations. Highly recommend it for anyone looking for a reliable, high-quality option for PS5 gaming!",
"review_title": "Perfect headset",
"review_url": "https://www.amazon.com/gp/customer-reviews/RKJ2UD7FJ7BF3/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ",
"reviewed_date": "December 30, 2024",
"reviewed_product_variant": "Color: White"
},
{
"author_name": "Miranda Ryan",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEMVKC2MVQGYU5SULN3VESBGEFSQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "4.0",
"review_text": "Like all the other reviews posted for this product, I've been impressed with the sound, functionality, and comfort the headset provides. Soft padding for the ears and the top of the head makes you forget you're wearing a headset, and the button commands for a quick mute, or to change songs, play songs, etc, are easy to map out and memorize once they're on your head. Unfortunately, after only 3-4 months of owning the product, the mic has come loose, and my party/call members are complaining of static through the mic. The mic is busted now, but the sound quality still lives; so no more calls for these headphones. :( If you decide to get these, note that the reviews are accurate; I've been incredibly happy with the performance and comfort -- just, treat the mic real gently, or you might put it in an early grave.",
"review_title": "Fragile Mic",
"review_url": "https://www.amazon.com/gp/customer-reviews/R2KHAKAG2CRBU0/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ",
"reviewed_date": "January 15, 2025",
"reviewed_product_variant": "Color: White"
},
{
"author_name": "Jordan Baker",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AGM47O2TFY7TOLBNPQDWLI7HYBWQ/ref=cm_cr_dp_d_gw_pop?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I like the say on the low end of headsets because I do not want to spend $100-$200 in my opinion. These good great for gaming and they are builds with arguably good quality. For the price these are pretty good and I believe they have a multi switch so you can plug the usb like I did into your control and the smaller into your computer Vic Versa. Lastly just love the way they feel on my head and really comfortable at that as well. Sound quality is great and I can shake my head around and they won’t come off. Has a wireless or wire mode is is a plus and also again everthing your getting at this price is probably one of the better headphones on Amazon you can buy at a reasonable good price .",
"review_title": "Good Gaming Headset for the price",
"review_url": "https://www.amazon.com/gp/customer-reviews/R35217UUCTC5SE/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0C4F9JGTJ",
"reviewed_date": "January 17, 2025",
"reviewed_product_variant": "Color: White"
},
{
"author_name": "Roger Handt",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Das Headset ist stabil verarbeitet und es ist aufgrund des relativ geringen Gewichts sehr angenehm zu tragen. Ich habe relativ große Ohren und deshalb Probleme, ein passendes Headset zu finden. Mit diesem habe ich keine Probleme. Zur technischen Seite: Die WiFi-Konnektivität funktioniert hervorragend, sowohl mit dem beiliegenden Adapter als auch per Bluetooth mit dem Smartphone gekoppelt. Das Noise-Canceling ist solide, der Kopfhörer umschließt die Ohren vollständig und einigermaßen stramm, so werden Umgebungsgeräusche eh schon gut gedämpft. Die Akkulaufzeit hab ich noch nicht vollständig ausgereizt, aber auch eine lange Gaming-Session über hat der Akku bisher gut gehalten. Die Mikrofon-Qualität ist gemäß meiner Mitspieler auch sehr solide. Wer ein günstiges Headset sucht, ist mit diesem Modell in jedem Fall gut beraten.",
"review_title": "Sehr gute Preis/Leistung!",
"review_url": null,
"reviewed_date": "January 25, 2025",
"reviewed_product_variant": "Color: White"
},
{
"author_name": "Mickael",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Ce casque OZeing est une vraie surprise ! La connexion 2.4 GHz en Wi-Fi est ultra stable, sans latence, ce qui est parfait pour le gaming. Le son est clair, bien équilibré, avec des basses immersives qui donnent une vraie profondeur aux jeux. Le micro est également de bonne qualité, avec une voix nette et sans bruit parasite. Côté confort, rien à redire : les coussinets sont doux et agréables même après plusieurs heures de jeu. Et l’autonomie est excellente, ce qui évite d’avoir à le recharger trop souvent. Bref, un excellent rapport qualité-prix pour ceux qui cherchent un casque sans fil performant et abordable. Je recommande sans hésiter.",
"review_title": "Excellent casque gaming sans fil !",
"review_url": null,
"reviewed_date": "January 15, 2025",
"reviewed_product_variant": "Color: White"
},
{
"author_name": "Tina",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Dieses Headset hat mich wirklich überzeugt und gehört definitiv zu den besten, die ich bisher genutzt habe. *Schnelle Lieferung*: Die Lieferung war unglaublich flott! Innerhalb kürzester Zeit war das Headset bei mir, sicher verpackt und in einwandfreiem Zustand. So muss es sein! *Stabil und hochwertig*: Die Verarbeitung ist top. Das Headset fühlt sich sehr robust an und macht den Eindruck, dass es auch bei häufiger Nutzung lange hält. *Exzellente Klang- und Sprachqualität*: Der Sound ist ein echtes Highlight – detailliert, kraftvoll und perfekt abgestimmt. Egal ob für Gaming, Musik oder Filme, der Klang ist einfach fantastisch. Das Mikrofon liefert zudem eine klare Übertragung ohne Störgeräusche, was gerade beim Spielen mit Freunden super wichtig ist. *Modernes Design*: Das Headset sieht richtig gut aus! Es kombiniert ein modernes, ansprechendes Design mit hohem Tragekomfort. Selbst nach Stunden bleibt es bequem und angenehm zu tragen. Alles in allem bin ich mehr als zufrieden. Dieses Headset ist für jeden Gamer, der Wert auf Qualität und Design legt, eine ausgezeichnete Wahl. Von mir gibt es volle 5 Sterne!",
"review_title": "Perfektes Gaming-Headset – klare Empfehlung!",
"review_url": null,
"reviewed_date": "December 11, 2024",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Nikkolos",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Au premier abord,j'ai voulu le renvoyer ,mais après comparaison avec un jbl d' un prix plus élevée : résultat = y a pas photo ! c'est un super casque ! Compatible avec tout ( ma tv , console ps5/ps4, mon téléphone, d'une simplicité enfantine pour se connecter à tout ses appareils. Le son est excellent, immersif et les basses profondes sans Passés au dessus des aiguës et médium. Plage de fréquences excellente je suis bluffé ! Pour une utilisation domestique sur console, regarder un film sur tv et écouter la musique sur you tube par ex. C'est le Top ! J'ai des casques haut de gammes, Marshall, jbl , Bose ect....il a rien à leurs envier ,ce casque est vraiment très bon ! Ne sature pas lvl à fond. N'hésitez pas et l' écoutez !!! Vous serez pas déçu et après 10h00 d'écoute il fonctionne encore ! Qe recharge super vite(2 h00) mais en 10 min de charges vous avez déjà minimum 2 h00 d'écoute. J'ai vérifié ! J'ai rajouter une mousse sur l'arceau de tête pour améliorer son confort et il me fait pas mal aux oreilles ni à la tête ! Le micro rétractable est super bien bien pensé et les boutons sont simples et intuitifs ( pas besoins d'un bac + 5 ) . On vois que c'est un casque consu par un des gamers, qui aime la qualité du son . Avec ps5 j'ai le son 3D Sony qui est excellent. ( sur ps5 tout les casques milieu de game sont compatible 3D) pas besoin du casque officiel c tjrs bon à savoir. Bon jeu et bonne écoute surtout !",
"review_title": "Rapport qualité prix géniale",
"review_url": null,
"reviewed_date": "September 21, 2024",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Sandrine S",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Bon son, confortable, beau design, fonctionne en Bluetooth ou 2.4G avec clé USB. Très bon rapport qualité/ prix.",
"review_title": "Très bon casque gaming.",
"review_url": null,
"reviewed_date": "January 14, 2025",
"reviewed_product_variant": "Color: Black"
}
],
"product_variations": {
"color_name": [
"Black",
"Blue",
"Camouflage",
"Pink",
"Red",
"White",
"Yellow"
]
},
"rating": "4.4",
"rating_histogram": {
"five_star": "77%",
"four_star": "8%",
"one_star": "7%",
"three_star": "5%",
"two_star": "3%"
},
"regular_price": "49.99",
"review_count": "7,920",
"sale_price": "32.08",
"seller": "WU MEIJIAO storeWU MEIJIAO store",
"seller_url": "https://www.amazon.com/gp/help/seller/at-a-glance.html/ref=dp_merchant_link?ie=UTF8&seller=A3AUHWT8COGTZ8&asin=B0C4F9JGTJ&ref_=dp_merchant_link&isAmazonFulfilled=1",
"shipping_charge": null,
"small_description": "【Amazing Stable Connection-Quick Access to Games】Real-time gaming audio with our 2.4GHz USB & Type-C ultra-low latency wireless connection. With less than 30ms delay, you can enjoy smoother operation and stay ahead of the competition, so you can enjoy an immersive lag-free wireless gaming experience. - 【Game Communication-Better Bass and Accuracy】The 50mm driver plus 2.4G lossless wireless transports you to the gaming world, letting you hear every critical step, reload, or vocal in Fortnite, Call of Duty, The Legend of Zelda and RPG, so you will never miss a step or shot during game playing. You will completely in awe with the range, precision, and audio quality your ears were experiencing. - 【Flexible and Convenient Design-Effortless in Game】Ideal intuitive button layout on the headphones for user. Multi-functional button controls let you instantly crank or lower volume and mute, quickly answer phone calls, cut songs, turn on lights, etc. Ease of use and customization, are all done with passion and priority for the user. - 【Less plug, More Play-Dual Input From 2.4GHz & Bluetooth】 Wireless gaming headset adopts high performance dual mode design. With a 2.4GHz USB dongle, which is super sturdy, lag<30ms, perfectly made for gamers. Bluetooth mode only work for phone, laptop and switch. And 3.5mm wired mode (Only support music and call). - 【Wide Compatibility with Gaming Devices】Setup the perfect entertainment system by plugging in 2.4G USB. The convenience of dual USB work seamlessly with your PS5,PS4, PC, Mac, Laptop, Switch and saves you from swapping cables. - Bluetooth function CANT'T directly SUPPORT with Mac, Ps5, Ps4,Pc, additional USB Bluetooth Adapter is required (not included). Recommend to use the 2.4G mode, it easy and amazing connect. - The 2 in 1 USB transmitter needs to be combined to connect for Ps/Ps2/Ps5/Ps4/PC/Laptop/Mac, can't be used separately. NOT:OW810 wireless gaming headset NOT Compatible with Xbox.",
"sponsored_products": [
{
"asin": "B0DJW2X8BX",
"image_url": "https://m.media-amazon.com/images/I/41ofZctOgqL._AC_UF480,480_SR480,480_.jpg",
"price": "$39.99",
"product_name": "Wireless Gaming Headset for PS5, PS4, Elden Ring, PC, Mac, Switch, Bluetooth 5.3 Ga...",
"rating": "5",
"reviews": "534",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2MTMzMTYwNTIwMjo6Ojo&url=%2Fdp%2FB0DJW2X8BX%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0DJW2X8BX%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0D69Z3QR4",
"image_url": "https://m.media-amazon.com/images/I/41Rjxnr8aUL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$32.99",
"product_name": "3D Stereo Wireless Gaming Headset for PC, PS4, PS5, Mac, Switch, Mobile | Bluetooth...",
"rating": "4",
"reviews": "400",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY0Nzk1NzI0NjUwMjo6Ojo&url=%2Fdp%2FB0D69Z3QR4%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0D69Z3QR4%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B09TB15CTL",
"image_url": "https://m.media-amazon.com/images/I/41o-o1sxliL._AC_UF480,480_SR480,480_.jpg",
"price": "$16.99",
"product_name": "Gaming Headset for PC, Ps4, Ps5, Xbox Headset with 7.1 Surround Sound, Gaming Headp...",
"rating": "4",
"reviews": "5,095",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ4NDU3MTU0NzcwMjo6Ojo&url=%2Fdp%2FB09TB15CTL%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB09TB15CTL%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ4NDU3MTU0NzcwMjo6Ojo&url=%2Fdp%2FB09TB15CTL%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB09TB15CTL%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0BFR75H2G",
"image_url": "https://m.media-amazon.com/images/I/41LAVzxA7pL._AC_UF480,480_SR480,480_.jpg",
"price": "$59.99",
"product_name": "SOMIC G810 Wireless Headset 2.4G Low Latency Headset for PC PS4 PS5 Laptop, Bluetooth 5.2 Wireless Headphone with Built-in Mic, 50H Playtime, RGB Light Foldable for Gamer (Xbox Only Work in Wired)",
"rating": "4",
"reviews": "278",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE2MDI4MTQ2NjM5ODo6Ojo&url=%2Fdp%2FB0BFR75H2G%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0BFR75H2G%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0D3HV5M3Y",
"image_url": "https://m.media-amazon.com/images/I/41MUVUXwcyL._AC_UF480,480_SR480,480_.jpg",
"price": "$29.99",
"product_name": "Wireless Gaming Headset for PC, PS4, PS5, Mac,Switch,2.4GHz USB Gaming Headset with...",
"rating": "4",
"reviews": "359",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2ODU1OTI5NDcwMjo6Ojo&url=%2Fdp%2FB0D3HV5M3Y%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0D3HV5M3Y%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0878W5F4X",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$21.99",
"product_name": "Gaming Headset with Microphone for PC PS4 PS5 Headset Noise Cancelling Gaming Headphones for Laptop Mac Switch Xbox One Headset with LED Lights Deep Bass for Kids Adults Black Blue",
"rating": "4",
"reviews": "19,883",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU3NDUwNDg5ODYwMjo6Ojo&url=%2Fdp%2FB0878W5F4X%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0878W5F4X%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU3NDUwNDg5ODYwMjo6Ojo&url=%2Fdp%2FB0878W5F4X%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0878W5F4X%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0B4B2HW2N",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$33.99",
"product_name": "2.4GHz Wireless Gaming Headset for PS5, PS4 Fortnite & Call of Duty/FPS Gamers, PC,...",
"rating": "4",
"reviews": "9,011",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDE0NjQ2NjYwMzcwMjo6Ojo&url=%2Fdp%2FB0B4B2HW2N%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0B4B2HW2N%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MToyOTU5MjgxMzIyMjQ5NzUzOjE3Mzk5MDYyOTY6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDE0NjQ2NjYwMzcwMjo6Ojo&url=%2Fdp%2FB0B4B2HW2N%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0B4B2HW2N%26pd_rd_w%3DCImLL%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0B4B2HW2N",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$33.99",
"product_name": "2.4GHz Wireless Gaming Headset for PS5, PS4 Fortnite & Call of Duty/FPS Gamers, PC,...",
"rating": "4",
"reviews": "9,011",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDAxNDY0NjY2MDM3MDI6Ojo6&url=%2Fdp%2FB0B4B2HW2N%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0B4B2HW2N%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDAxNDY0NjY2MDM3MDI6Ojo6&url=%2Fdp%2FB0B4B2HW2N%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0B4B2HW2N%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0CLLJC6QC",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$39.99",
"product_name": "Wireless Gaming Headset, 7.1 Surround Sound, 2.4Ghz USB Gaming Headphones with Blue...",
"rating": "4",
"reviews": "895",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDAyMDI2MDcxNTU0MDI6Ojo6&url=%2Fdp%2FB0CLLJC6QC%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0CLLJC6QC%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDAyMDI2MDcxNTU0MDI6Ojo6&url=%2Fdp%2FB0CLLJC6QC%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0CLLJC6QC%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B09JFZC7D6",
"image_url": "https://m.media-amazon.com/images/I/41kn-1bwKKL._AC_UF480,480_SR480,480_.jpg",
"price": "$29.99",
"product_name": "Bluetooth Cat Ear Headphones for Kids, Wireless & Wired Mode Foldable Headset with ...",
"rating": "4",
"reviews": "604",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2NjYxMDQ4MTk3MDI6Ojo6&url=%2Fdp%2FB09JFZC7D6%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB09JFZC7D6%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0D3HV5M3Y",
"image_url": "https://m.media-amazon.com/images/I/41MUVUXwcyL._AC_UF480,480_SR480,480_.jpg",
"price": "$29.99",
"product_name": "Wireless Gaming Headset for PC, PS4, PS5, Mac,Switch,2.4GHz USB Gaming Headset with...",
"rating": "4",
"reviews": "359",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2Njg1NTkyOTQ3MDI6Ojo6&url=%2Fdp%2FB0D3HV5M3Y%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0D3HV5M3Y%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0DJW2X8BX",
"image_url": "https://m.media-amazon.com/images/I/41ofZctOgqL._AC_UF480,480_SR480,480_.jpg",
"price": "$39.99",
"product_name": "Wireless Gaming Headset for PS5, PS4, Elden Ring, PC, Mac, Switch, Bluetooth 5.3 Ga...",
"rating": "5",
"reviews": "534",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2NjEzMzE2MDUyMDI6Ojo6&url=%2Fdp%2FB0DJW2X8BX%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0DJW2X8BX%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0D69Z3QR4",
"image_url": "https://m.media-amazon.com/images/I/41Rjxnr8aUL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$32.99",
"product_name": "3D Stereo Wireless Gaming Headset for PC, PS4, PS5, Mac, Switch, Mobile | Bluetooth...",
"rating": "4",
"reviews": "400",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2NDc5NTcyNDY1MDI6Ojo6&url=%2Fdp%2FB0D69Z3QR4%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0D69Z3QR4%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0CNVHKVVL",
"image_url": "https://m.media-amazon.com/images/I/41+mB9ThR+L._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$35.99",
"product_name": "2.4GHz Wireless Gaming Headset with Wired Mode, 5.4 Bluetooth Gaming Headphones for...",
"rating": "4",
"reviews": "494",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozNTk0MDk5MjAyMTI5MDgyOjE3Mzk5MDYyOTY6c3BfZGV0YWlsMjozMDA2NjQ2NDQxODA0MDI6Ojo6&url=%2Fdp%2FB0CNVHKVVL%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0CNVHKVVL%26pd_rd_w%3D55FTJ%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3HYQN9N1DWJ06DEX71N8%26pd_rd_wg%3DoBtem%26pd_rd_r%3D6a03dfba-02b7-4e7d-b756-9adaa7f5ce50%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
}
],
"url": "https://www.amazon.com/Ozeino-2-4GHz-Wireless-Gaming-Headset/dp/B0C4F9JGTJ/ref=sr_1_3?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-3&th=1",
"variation_asin": [
{
"asin": "B0DR8YG8D5",
"color_name": "Red"
},
{
"asin": "B0DR8WLWDF",
"color_name": "Blue"
},
{
"asin": "B0C4F9JGTJ",
"color_name": "White"
},
{
"asin": "B0C49F6NG6",
"color_name": "Black"
},
{
"asin": "B0DF7D1WLM",
"color_name": "Pink"
},
{
"asin": "B0DJR519T2",
"color_name": "Camouflage"
},
{
"asin": "B0D95Y2Z1K",
"color_name": "Yellow"
}
]
},
{
"asin": "B0B7X6PWMR",
"attributes": "access_method: Wired, edition: Arctis Nova 1P White, platform_for_display: PC, PlayStation",
"availability_status": "In Stock",
"available_quantity": null,
"brand": "SteelSeries",
"category": [
{
"level": 1,
"name": "Video Games",
"url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"
},
{
"level": 2,
"name": "PlayStation 4",
"url": "/PlayStation-4-Games-Consoles-Accessories-Hardware/b/ref=dp_bc_aui_C_2?ie=UTF8&node=6427814011"
},
{
"level": 3,
"name": "Accessories",
"url": "/PlayStation-4-Hardware-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=6427815011"
},
{
"level": 4,
"name": "Headsets",
"url": "/PlayStation-4-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=6427826011"
}
],
"currency": "USD",
"frequently_bought_together": [
{
"link": "https://www.amazon.com/SteelSeries-Apex-RGB-Gaming-Keyboard/dp/B07ZGDPT4M/ref=pd_day0fbt_hardlines_d_sccl_1/136-0100575-5165336?pd_rd_w=ydCPA&content-id=amzn1.sym.06aea998-aa9c-454e-b467-b476407c7977&pf_rd_p=06aea998-aa9c-454e-b467-b476407c7977&pf_rd_r=3KKGC4TCWSZ3S47PSWC3&pd_rd_wg=SEDPc&pd_rd_r=ac78a567-1eb0-40fa-b9df-35ce45746884&pd_rd_i=B07ZGDPT4M&psc=1",
"price": "$39.99",
"title": "SteelSeries Apex 3 RGB Gaming Keyboard – 10-Zone RGB Illumination – IP32 Water Resistant – Premium Magnetic Wrist Rest (Whisper Quiet Gaming Switch)"
},
{
"link": "https://www.amazon.com/SteelSeries-Arctis-Multi-Platform-Gaming-Mobile-Headset/dp/B0B8QP5BGD/ref=pd_day0fbt_hardlines_d_sccl_2/136-0100575-5165336?pd_rd_w=ydCPA&content-id=amzn1.sym.06aea998-aa9c-454e-b467-b476407c7977&pf_rd_p=06aea998-aa9c-454e-b467-b476407c7977&pf_rd_r=3KKGC4TCWSZ3S47PSWC3&pd_rd_wg=SEDPc&pd_rd_r=ac78a567-1eb0-40fa-b9df-35ce45746884&pd_rd_i=B0B8QP5BGD&psc=1",
"price": "$135.99",
"title": "SteelSeries Arctis Nova 7X Wireless Multi-Platform Gaming Headset — Neodymium Magnetic Drivers — 2.4GHz+Bluetooth — 38Hr USB-C Battery — AI Mic — Xbox Series X|S, PC, PS5, Switch, VR, Mobile - Black"
}
],
"full_description": "Almighty Audio has never been more accessible, as the Arctis Nova 1P combines hardware and software to deliver superior sound quality with high-fidelity drivers, immersive 360° spatial sound, and a 10-band parametric EQ for countless customizations. The ComfortMax system allows 4 adjustment points, easily finding a perfect fit on the lightweight helmet with AirWeave Memory Foam Pads. The professional-grade noise-cancelling mic reduces background noise, which ensures clear communication while you play and comfortable even during long gaming sessions. The Arctis Nova 1P features a 3.5mm jack that works with virtually any platform, including PlayStation, PC, Xbox, Switch and your mobile device. Easily adjust the volume and mute your voice with the controls on the headset.",
"highlighted_specifications": {
"Brand": "SteelSeries",
"Color": "White",
"Ear Placement": "Over Ear",
"Form Factor": "Circumauricular",
"Noise Control": "Active Noise Cancellation"
},
"image_urls": [
"https://m.media-amazon.com/images/I/61czC2G0+NL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/616gH-ueIYL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61WpgrSOKgL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/614cUP5fg-L._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61tdfqUb1zL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61z46+emekL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/611X5YNe6NL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/713716y2IyL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71WHn7XTr5L._AC_SL1500_.jpg"
],
"model": "Arctis Nova 1P White",
"name": "SteelSeries Arctis Nova 1P PS5 Headphones - Gaming Headset - 360° Space Sound - Memory Foam Ear Pads - Noise Cancelling Microphone - Also for PC, PS4, Switch, Xbox - White",
"product_category": "Video Games > PlayStation 4 > Accessories > Headsets",
"product_information": {
"ASIN": "B0B7X6PWMR",
"Age Range (Description)": "Adult",
"Amazon Best Sellers Rank": "#20,806 in Video Games , #238 in PlayStation 4 Headsets , #298 in PlayStation 5 Headsets",
"Audio Driver Type": "Dynamic Driver",
"Cable Feature": "Without Cable",
"Compatible Devices": "Cellphones, Gaming Consoles, Laptops, Desktops",
"Connectivity Technology": "Wired",
"Control Method": "Remote",
"Control Type": "noise cancelling",
"Country of Origin": "China",
"Date First Available": "March 12, 2023",
"Earpiece Shape": "over-ear",
"Frequency Range": "20Hz - 20,000Hz",
"Headphones Jack": "3.5 mm Jack",
"Included Components": "Cable, Ear Cushions, Headband",
"Is Autographed": "No",
"Item Weight": "9.5 ounces",
"Item model number": "Arctis Nova 1P White",
"Language": "English",
"Manufacturer": "SteelSeries",
"Material": "Leather",
"Model Name": "SteelSeries Arctis Nova 1P White",
"Number of Items": "1",
"Package Type": "Rigid packaging",
"Product Dimensions": "3.43 x 6.89 x 7.48 inches",
"Recommended Uses For Product": "Hunting Instinct",
"Series Number": "1",
"Specific Uses For Product": "Gaming",
"Style": "Nova White for PlayStation",
"Theme": "Video Game",
"UPC": "657768613418",
"Water Resistance Level": "Not Water Resistant",
"Wireless Communication Technology": "Telephone"
},
"product_reviews": [
{
"author_name": "Elizabeth R Webster",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AG46C2OEIF6OY7KIISCENS7S5QSA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "4.0",
"review_text": "Had to buy a seperate cord splitter so the headphones could be used for my computer. Maybe this is something they could offer as an option in the packaging in the future. After buying the splitter, it works great now",
"review_title": "nice! minimalist",
"review_url": "https://www.amazon.com/gp/customer-reviews/R3KORH5B293ITL/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0B7X6PWMR",
"reviewed_date": "January 31, 2025",
"reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"
},
{
"author_name": "HOMMEL Frédéric",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Le son est génial, le confort également, utilisé sur PS5, j'ai juste acheter un adaptateur pour pouvoir l'utiliser aussi sur mon PC.",
"review_title": "Le casque qu'il faut pour PS5",
"review_url": null,
"reviewed_date": "December 15, 2024",
"reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"
},
{
"author_name": "steven",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Pure quality, comfort and sound . Highly recommend",
"review_title": "Great headset for PS5",
"review_url": null,
"reviewed_date": "December 26, 2024",
"reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"
},
{
"author_name": "Luca Massironi",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "le ha usate per tantissimo tempo soprattutto per giocare alla Play e mi sono sempre trovato benissimo, vendute solo per passaggio a modello ma dopo due anni erano ancora pulite e intatte",
"review_title": "comode e leggere",
"review_url": null,
"reviewed_date": "December 06, 2024",
"reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"
},
{
"author_name": "Kati",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Super sond ,ein klarer Klang ,einfach zu bedienen kurz gesagt es ist sein Geld werd",
"review_title": "1+ mit sternchen",
"review_url": null,
"reviewed_date": "August 19, 2024",
"reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"
},
{
"author_name": "Cliente Amazon",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Este tipo de auriculares me gustan mucho porque pesan poco y son muy cómodos con la esponjita esta que viene. Además se escuchan muy bien, los volvería a comprar sin duda.",
"review_title": "Muy buenos",
"review_url": null,
"reviewed_date": "June 02, 2024",
"reviewed_product_variant": "Platform For Display: PC, PlayStation | Edition: Arctis Nova 1P White | Access Method: Wired"
}
],
"product_variations": {
"access_method": [
"Wired"
],
"edition": [
"Arctis Nova 1P White"
],
"platform_for_display": [
"PC, PlayStation"
]
},
"rating": "4.0",
"rating_histogram": {
"five_star": "57%",
"four_star": "17%",
"one_star": "13%",
"three_star": "7%",
"two_star": "5%"
},
"regular_price": "83.79",
"review_count": "352",
"sale_price": "83.79",
"seller": "Amazon.com",
"seller_url": null,
"shipping_charge": null,
"small_description": "Almighty Audio — The custom-designed Nova acoustic system delivers best-in-class sound for gaming with High Fidelity Drivers. Completely customize your ideal sound experience with a professional-grade built-in video game parametric equalizer. - 360° SPACE SOUND - Immersive surround sound transports you into the gaming world, allowing you to hear every step, charge or voice cue to give you the edge. *Compatible with Tempest 3D Audio for PS5 / Microsoft Spatial Sound - Adjustable for a Perfect Fit - The ComfortMAX System includes rotatable, height-adjustable ear cups with AirWeave memory pad and an expandable band. The lightweight headset keeps you comfortable no matter how long you play. - Noise-Cancelling Mic - ClearCast Gen 2 reduces background noise by up to 25dB on any platform to give you crystal clear communications. Completely hide the mic in the earpiece for a more elegant look. - Multi-Platform Support - Easily connect to any game console, PlayStation, PC, Xbox, or Switch, with a 3.5mm jack. Also works great with mobile devices.",
"sponsored_products": [
{
"asin": "B0B8Q9FGMD",
"image_url": "https://m.media-amazon.com/images/I/41gPS37DbpL._AC_UF480,480_SR480,480_.jpg",
"price": "$175.99",
"product_name": "SteelSeries Arctis Nova 7P Wireless Multi-Platform Gaming Headset — Neodymium Magnetic Drivers — 2.4GHz + Bluetooth — 38Hr USB-C Battery — Gen2 AI Mic — PlayStation, PC, Switch, VR, Mobile - Black",
"rating": "4",
"reviews": "5,892",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDExNDg4MzcyODg5ODo6Ojo&url=%2Fdp%2FB0B8Q9FGMD%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0B8Q9FGMD%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B01H6GUCCQ",
"image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$19.99",
"product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo",
"rating": "4",
"reviews": "108,513",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UU"
},
{
"asin": "B0DJW2X8BX",
"image_url": "https://m.media-amazon.com/images/I/41ofZctOgqL._AC_UF480,480_SR480,480_.jpg",
"price": "$39.99",
"product_name": "Wireless Gaming Headset for PS5, PS4, Elden Ring, PC, Mac, Switch, Bluetooth 5.3 Ga...",
"rating": "5",
"reviews": "534",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2MTM1NTkxMjkwMjo6Ojo&url=%2Fdp%2FB0DJW2X8BX%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0DJW2X8BX%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0D3V4HZJV",
"image_url": "https://m.media-amazon.com/images/I/31upse7J5HL._AC_UF480,480_SR480,480_.jpg",
"price": "$19.99",
"product_name": "CM7002 Gaming Headset for PS5, PS4, PC, Mac, Switch, Xbox Series, Surround Sound RG...",
"rating": "4",
"reviews": "1,374",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ5NTY5MTQ1NDUwMjo6Ojo&url=%2Fdp%2FB0D3V4HZJV%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0D3V4HZJV%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B09ZW52XSQ",
"image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$212.95",
"product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360° Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch",
"rating": "4",
"reviews": "1,280",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B09ZWKD9TF",
"image_url": "https://m.media-amazon.com/images/I/312MvjLsRXL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$306.99",
"product_name": "SteelSeries Arctis Nova Pro Wireless Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Active Noise Cancellation Infinity Power System - Stealth Mic - Xbox, PC, PS5, PS4, Switch, Mobile",
"rating": "4",
"reviews": "5,928",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA1OTIyNzIxMDE5ODo6Ojo&url=%2Fdp%2FB09ZWKD9TF%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB09ZWKD9TF%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B08BTHXJFN",
"image_url": "https://m.media-amazon.com/images/I/2129YqrQiuL._AC_UF480,480_SR480,480_.jpg",
"price": "$72.82",
"product_name": "HyperX HHSS1C-KB-WT/G Cloud Stinger Core – Wireless Gaming Headset, for PS4, PS5, PC, Lightweight, Durable Steel Sliders, Noise-Cancelling Microphone - White",
"rating": "4",
"reviews": "8,533",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MToxMDk2Mzg2MjUzMDk0NTk5OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDI5MTIzNDkyMjQwMjo6Ojo&url=%2Fdp%2FB08BTHXJFN%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB08BTHXJFN%26pd_rd_w%3DfwnfA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0DB7ZW7J4",
"image_url": "https://m.media-amazon.com/images/I/41CcIOb-fOL._AC_UF480,480_SR480,480_.jpg",
"price": "$279.99",
"product_name": "Logitech G Astro A50 Omni-Platform Wireless Gaming Headset + Base Station for PS5, Xbox, PC: PLAYSYNC Audio Switcher, <16 bit/48kHz (Console), <24 bit/48 kHz (PC), 24hr Battery, 2.4GHz & BT - Black",
"rating": "4",
"reviews": "633",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1MDY5ODk2MDAxMDI6Ojo6&url=%2Fdp%2FB0DB7ZW7J4%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0DB7ZW7J4%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0D3XMVS73",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$26.99",
"product_name": "Wireless Gaming Headset for PC, PS5, PS4, Mac, Nintendo Switch, Gaming Headphones w...",
"rating": "4",
"reviews": "1,182",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1OTIwOTEwMTc0MDI6Ojo6&url=%2Fdp%2FB0D3XMVS73%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0D3XMVS73%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1OTIwOTEwMTc0MDI6Ojo6&url=%2Fdp%2FB0D3XMVS73%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0D3XMVS73%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0B7V128P9",
"image_url": "https://m.media-amazon.com/images/I/31QbTaOMqiL._AC_UF480,480_SR480,480_.jpg",
"price": "$119.99",
"product_name": "Turtle Beach Stealth 600 Gen 2 MAX Wireless Amplified Multiplatform Gaming Headset for PS5, PS4, Nintendo Switch, PC & Mac with 48+ Hour Battery, Lag-free Wireless, & 50mm Speakers – Black",
"rating": "4",
"reviews": "2,425",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAyOTc0MDkzMzYxMDI6Ojo6&url=%2Fdp%2FB0B7V128P9%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0B7V128P9%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B07JYRWJ4G",
"image_url": "https://m.media-amazon.com/images/I/41M5uTQidfL._AC_UF480,480_SR480,480_.jpg",
"price": "$9.80",
"product_name": "NewFantasia Replacement Audio Cable Compatible with SteelSeries Arctis 3, Arctis Prime, Arctis 5, Arctis 7, Arctis Pro Gaming Headset 1.3meters/4.3feet",
"rating": "4",
"reviews": "2,348",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwMDk1MzQ3Nzk3NTE6Ojo6&url=%2Fdp%2FB07JYRWJ4G%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB07JYRWJ4G%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B09ZW52XSQ",
"image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$212.95",
"product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360° Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch",
"rating": "4",
"reviews": "1,280",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwNTk1NTU5MTM4OTg6Ojo6&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0B15QM5LL",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$153.99",
"product_name": "SteelSeries Arctis Nova 7 Wireless Multi-Platform Gaming Headset — Neodymium Magnetic Drivers — 2.4GHz + Mixable Bluetooth — 38Hr USB-C Battery — ClearCast Gen2 AI Mic — PC, PS5, Switch, VR, Mobile",
"rating": "4",
"reviews": "5,892",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAxMTMzMjYzMjc0OTg6Ojo6&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAxMTMzMjYzMjc0OTg6Ojo6&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B09ZWKD9TF",
"image_url": "https://m.media-amazon.com/images/I/312MvjLsRXL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$306.99",
"product_name": "SteelSeries Arctis Nova Pro Wireless Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Active Noise Cancellation Infinity Power System - Stealth Mic - Xbox, PC, PS5, PS4, Switch, Mobile",
"rating": "4",
"reviews": "5,928",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NzEzODc3Mjc4MjI0NjY3OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwNTkyMjcyMTAxOTg6Ojo6&url=%2Fdp%2FB09ZWKD9TF%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB09ZWKD9TF%26pd_rd_w%3D9KpKG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D3KKGC4TCWSZ3S47PSWC3%26pd_rd_wg%3DSEDPc%26pd_rd_r%3Dac78a567-1eb0-40fa-b9df-35ce45746884%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
}
],
"url": "https://www.amazon.com/SteelSeries-Arctis-Nova-1P-White/dp/B0B7X6PWMR/ref=sr_1_5?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-5&th=1",
"variation_asin": [
{
"access_method": "Wired",
"asin": "B0B7X6PWMR"
},
{
"asin": "B0B7X6PWMR",
"edition": "Arctis Nova 1P White"
},
{
"asin": "B0B7X6PWMR",
"platform_for_display": "PC, PlayStation"
}
]
},
{
"asin": "B086PKMZ21",
"attributes": "size: 3.5mm, color: Black, style: PC",
"availability_status": "In Stock",
"available_quantity": null,
"brand": "Razer",
"category": [
{
"level": 1,
"name": "Video Games",
"url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"
},
{
"level": 2,
"name": "PC",
"url": "/PC-Games/b/ref=dp_bc_aui_C_2?ie=UTF8&node=229575"
},
{
"level": 3,
"name": "Accessories",
"url": "/PC-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=318813011"
},
{
"level": 4,
"name": "Headsets",
"url": "/PC-Game-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=402053011"
}
],
"currency": "USD",
"frequently_bought_together": [
{
"link": "https://www.amazon.com/Razer-DeathAdder-Essential-Gaming-Mouse/dp/B094PS5RZQ/ref=pd_bxgy_d_sccl_1/145-8288250-4808110?pd_rd_w=zICGu&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=G7TM5EQGRGESEZ1GWYQY&pd_rd_wg=5UENK&pd_rd_r=4f8fd24c-0296-4b05-b4a7-dea7015779fe&pd_rd_i=B094PS5RZQ&psc=1",
"price": "$24.82",
"title": "Razer DeathAdder Essential Gaming Mouse: 6400 DPI Optical Sensor - 5 Programmable Buttons - Mechanical Switches - Rubber Side Grips - Classic Black"
},
{
"link": "https://www.amazon.com/Razer-Ornata-Gaming-Keyboard-Low-Profile/dp/B09X6GJ691/ref=pd_bxgy_d_sccl_2/145-8288250-4808110?pd_rd_w=zICGu&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=G7TM5EQGRGESEZ1GWYQY&pd_rd_wg=5UENK&pd_rd_r=4f8fd24c-0296-4b05-b4a7-dea7015779fe&pd_rd_i=B09X6GJ691&psc=1",
"price": "$34.98",
"title": "Razer Ornata V3 X Gaming Keyboard: Low Profile Keys - Silent Membrane Switches - Spill Resistant - Chroma RGB Lighting - Ergonomic Wrist Rest - Snap Tap"
}
],
"full_description": "Embrace the sound of esports with the Razer BlackShark V2 X-a triple threat of amazing audio, superior mic clarity and supreme sound isolation. With our best headset mic and audio drivers packed into a unique aviation-style headset, your competitive play is destined to turn pro.",
"highlighted_specifications": {
"Brand": "Razer",
"Color": "Black",
"Ear Placement": "Over Ear",
"Form Factor": "Over Ear",
"Impedance": "32 Ohm"
},
"image_urls": [
"https://m.media-amazon.com/images/I/51FRJHB7XOL._AC_SL1001_.jpg",
"https://m.media-amazon.com/images/I/61YIiVcTxzL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61b4IyVq4GL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61tpG4baChL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71DONh6d2aL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71kyUi6dtfL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71DgjgWcCTL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71++Y1XWs2L._AC_SL1500_.jpg"
],
"model": "RZ04-03240100-R3U1",
"name": "Razer BlackShark V2 X Gaming Headset: 7.1 Surround Sound - 50mm Drivers - Memory Foam Cushion - For PC, PS4, PS5, Switch - 3.5mm Audio Jack - Black",
"product_category": "Video Games > PC > Accessories > Headsets",
"product_information": {
"ASIN": "B086PKMZ21",
"Age Range (Description)": "Adult",
"Amazon Best Sellers Rank": "#78 in Video Games , #6 in PC Game Headsets",
"Audio Driver Size": "50 Millimeters",
"Audio Driver Type": "Dynamic Driver",
"Cable Feature": "Retractable",
"Carrying Case Color": "Black or gray",
"Compatible Devices": "PlayStation 4, Switch, Laptops, Desktops, Mac",
"Connectivity Technology": "Wired",
"Control Method": "Remote",
"Control Type": "Noise Control",
"Country of Origin": "China",
"Date First Available": "July 30, 2020",
"Earpiece Shape": "Over-ear with oval cushions",
"Frequency Range": "100 Hz - 10 kHz",
"Frequency Response": "28 KHz",
"Headphones Jack": "3.5 mm Jack",
"Included Components": "Important Product Information Guide, Audio/mic splitter extension cable, Razer BlackShark V2 X",
"Is Autographed": "No",
"Item Weight": "1.2 pounds",
"Item model number": "RZ04-03240100-R3U1",
"Manufacturer": "Razer",
"Material": "Titanium, Memory Foam",
"Model Name": "BlackShark V2 X",
"Noise Control": "Sound Isolation",
"Number of Items": "1",
"Package Type": "Standard Packaging",
"Product Dimensions": "7.6 x 6.76 x 3.86 inches",
"Recommended Uses For Product": "Gaming",
"Sensitivity": "100 dB",
"Specific Uses For Product": "Personal, Gaming",
"Style": "PC",
"Theme": "Video Game",
"UPC": "811659037572",
"Unit Count": "1.0 Count",
"Water Resistance Level": "Not Water Resistant",
"Wireless Communication Technology": "Bluetooth"
},
"product_reviews": [
{
"author_name": "Justin O",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFHWT2JADKRVSGR2KBL7JGJIVQ6A/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "For what it costs, I had relatively low expectations of this headset. I came from a Corsair Virtuoso SE wireless headset that had a great mic and very good sound, but the connection with my PS4 was never very solid and I would notice relatively frequent dropouts in audio. Friends with PS4s swore by using the 3.5mm jack on the controller and I decided to use this to test. Build Quality When you pick up the headset the first thing you notice is just how light it is. It feels somewhat solid, but also it's clear that this is not a headset that prioritized premium materials. It's also extremely comfortable because of how light it is. Although I've never had issues with heavier headsets and neck pain, if that is a consideration the light materials should be great for long term sessions. The pads are faux leather on the interior ring and exterior ring. The part that rests against your head feels like something a little more breathable. I don't think I will have any issues wearing these for long sessions. The clamping force is a good moderate level where they won't fall off accidentally, but I don't feel like I am in a death grip. Mic Quality I made some calls using the mic and, I believe this to be a great compliment to the quality of the mic, no one thought I was on a headset. \"It's like you were actually talking through your phone.\" Although they have a gamer vibe, I could definitely see using these on conference calls (as long as the video was off.) Basically, the mic is great. Audio Quality Here's where I was expecting things to fall apart, but they really didn't. I decided to make a completely unfair comparison between these and my pair of Sennheiser HD600s run off of an AudioQuest DragonFly Black DAC/AMP. There was clearly no contest between the two headphones in terms of vocals or detail retrieval, but the Razer wasn't a bad headphone by any means. It had a clear and present bass, without being muddy. I do feel like the Corsair Virtuoso had a more full sound, but the spotty connection ruined it. Gaming tends to be, I think, more forgiving than listening to music ... so I ran through a couple of games as a test. I tried a game that I feel focuses on background music (Unravel), which sounded great. I also tried something with more exploding (Borderlands 3) and the headset felt equally competent. Flaws (But Not Deal Breakers) The volume knob goes the opposite of the way my mind treats every other volume knob in my life. Clockwise turns the sound down?! WHY?! I would have loved an LED to remind me that I'm muted. My first attempted call failed because the mute was engaged. Conclusion The Razer Blackshark V2 X might have a terrible name, but it's an amazing product at the price point. I don't play as many games online as I used to and I listen to a lot more music. For me, it makes sense to have a great pair of headphones for music and solo play as well as a cheap headset for online play with friends and conference calls. This works for me.",
"review_title": "A (Really) Great Entry Level Wired Headset",
"review_url": "https://www.amazon.com/gp/customer-reviews/R2NOY9XYZJ5N5D/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21",
"reviewed_date": "August 04, 2020",
"reviewed_product_variant": "Color: Black | Size: 3.5mm | Style: PC"
},
{
"author_name": "Kill.dmg",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AG3HBBVG5XL4CTGZZOQR4FEUVVCA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "The best cheap headphone you can get. The 7.1 is perfect for gaming. Turned up high I can hear close footsteps exactly where they are on the map when players use ninja on bo6. They are extremely comfortable, the memory foam is great. They are very light perfect for long gaming. The noise cancellation is very good. mic could be better. The bass isn't the best. But overall the quality of sound is very good.",
"review_title": "best cheap headphones on earth.",
"review_url": "https://www.amazon.com/gp/customer-reviews/R18AU6RQTVH2D1/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21",
"reviewed_date": "February 06, 2025",
"reviewed_product_variant": "Color: Black | Size: 3.5mm | Style: PC"
},
{
"author_name": "ObtuseAglet",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AGPWYAA3XMVVCZIBF3PH7P5EPJIQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "As a person who plays video games and has pets and a small child I eat through my fair share of headsets. This headset not only gives me hope that it might outlast the others in its price category (sub-$100) but that it might be one of the best quality ones in the category too. Two things stand out about the headset: 1. Build quality is above average for this price. I am unsure of if this is because this is a cheaper version of a more expensive headset from Razer, or if they are just good at building them, but these don't feel flimsy, and they don't sound flimsy either. This leads to point 2. Sound Quality is comparable to most $100-120 headsets I've used. Digital surround has come a long way since it's debut, and it's easy to forget that these headphones don't feature multiple speakers on each side. Beyond that the microphone provides crisp, quiet audio comparable to that of a Shure SM58. When run through even a middling on board audio card on a desktop, there shouldn't be much of an audible difference between your microphone and those that others spent 4-5x the amount that you did. The physical knob for volume is an exceptional touch at this price, and honestly makes the headset so much more usable than on that requires pressing small buttons to change volume on. As the headset is wired you can use the volume knob on the headset to find tune the volume from your computer (which ideally you set at ~70% and then use the headset to set to the volume you truly want, this gives the best experience). I love these and I would love to get my hands on a pair of the Pro version to see just how much more incredible goodness Razer has crammed into them.",
"review_title": "Probably The Best Sub $100 Headset",
"review_url": "https://www.amazon.com/gp/customer-reviews/RZ36G7R5TENOL/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21",
"reviewed_date": "January 29, 2025",
"reviewed_product_variant": "Color: Green | Size: 3.5mm | Style: PC"
},
{
"author_name": "alex",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFRJKMYCFL5RIEDCX2J3LQH5XO2Q/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "4.0",
"review_text": "the headset is good and all the cushion part is nice and soft but it’s a little small on me as well as you others u are playing with can hear a little noise in the background but everything else is good headset is really loud when all the way up",
"review_title": "good except one thing",
"review_url": "https://www.amazon.com/gp/customer-reviews/RHQAF9KQSVV7Z/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21",
"reviewed_date": "January 20, 2025",
"reviewed_product_variant": "Color: White | Size: 3.5mm | Style: PC"
},
{
"author_name": "Amazon Customer",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEXGGJIPPH7VDBPXNOWO4ORMSYFQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I recently picked up a set of headphones for my Xbox, and I couldn’t be happier with the purchase. From the second I put them on, I could tell they were built to last. The construction is top-notch, with a solid yet comfortable design that feels durable without being too heavy. The ear cushions are super soft, making long gaming sessions feel effortless. When it comes to sound quality, these headphones truly shine. The audio is crystal clear, with deep, immersive bass and crisp highs that make every game feel more lifelike. It could be the subtle footsteps of an enemy in a shooter or the booming soundtrack of an open-world adventure, the sound is perfectly balanced and incredibly detailed. The surround sound effect is spot on, giving me a competitive edge in multiplayer games by making it easy to pinpoint enemy locations. The microphone is another highlight—my teammates hear me loud and clear without any distortion or background noise interference, with zero lag or dropouts, making the experience completely seamless. Overall, these headphones are a solid set for gaming. With their high-quality build, excellent comfort, and outstanding sound performance, they are easily one of the best gaming accessories I’ve ever owned. Highly recommended!",
"review_title": "Outstanding Headphones",
"review_url": "https://www.amazon.com/gp/customer-reviews/R2EYMTGMPDDA2W/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B086PKMZ21",
"reviewed_date": "February 03, 2025",
"reviewed_product_variant": "Color: Classic Black | Size: 3.5mm | Style: Xbox"
},
{
"author_name": "Emiliano Arce",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Me gustó mucho que su audio tiene buenos bajos y tonos fuertes para los que nos gusta escuchar música a alto volumen y también para juegos obviamente, Respecto al diseño son muy cómodos y ligeros que al paso del tiempo olvidas que están ahí además que en la caja de incluye pegatinas y una bolsa para transportarlos, Recomendados👍",
"review_title": "Cómodos y ligeros, excelente audio",
"review_url": null,
"reviewed_date": "January 22, 2025",
"reviewed_product_variant": "Color: White | Size: 3.5mm | Style: PC"
},
{
"author_name": "David leal",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Baratos, llegó a tiempo y sonido increíble, se siente de un material muy resistente, buenas alfombras y buen colchón de la diadema Había escuchado reseñas de que no se escuchaba cuando se hacían llamadas por Xbox, pero a mi sí me sirvió, ahora me escucho mejor con ese micrófono de los audífonos",
"review_title": "Increíble y sí se escucha el micro en Xbox",
"review_url": null,
"reviewed_date": "December 30, 2024",
"reviewed_product_variant": "Color: Green | Size: 3.5mm | Style: PC"
},
{
"author_name": "Max",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Excelente bien empaquetado y la entrega fue rápida",
"review_title": "Black Shark Xbox",
"review_url": null,
"reviewed_date": "December 29, 2024",
"reviewed_product_variant": "Color: Classic Black | Size: 3.5mm | Style: Xbox"
},
{
"author_name": "Mikel",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "El producto es cómodo, no esa y se siente resistente, de muy buena calidad! Es hermoso. Se escucha bien y el micrófono es bueno. Lo uso para mi Xbox",
"review_title": "10 de 10",
"review_url": null,
"reviewed_date": "December 15, 2024",
"reviewed_product_variant": "Color: Quartz Pink | Size: 3.5mm | Style: PC"
},
{
"author_name": "cristina",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "El producto llegó en excelente condiciones y funciona muy bien",
"review_title": "Lo recomiendo",
"review_url": null,
"reviewed_date": "December 12, 2024",
"reviewed_product_variant": "Color: Black | Size: USB | Style: PC"
}
],
"product_variations": {
"color_name": [
"Black",
"Classic Black",
"Green",
"Quartz Pink",
"White"
],
"size_name": [
"3.5mm",
"USB"
],
"style_name": [
"PlayStation",
"Xbox",
"PC"
]
},
"rating": "4.4",
"rating_histogram": {
"five_star": "72%",
"four_star": "14%",
"one_star": "6%",
"three_star": "5%",
"two_star": "3%"
},
"regular_price": "59.99",
"review_count": "20,701",
"sale_price": "39.99",
"seller": "Amazon.com",
"seller_url": null,
"shipping_charge": null,
"small_description": "ADVANCED PASSIVE NOISE CANCELLATION — sturdy closed earcups fully cover ears to prevent noise from leaking into the headset, with its cushions providing a closer seal for more sound isolation. - 7.1 SURROUND SOUND FOR POSITIONAL AUDIO — Outfitted with custom-tuned 50 mm drivers, capable of software-enabled surround sound. *Only available on Windows 10 64-bit - TRIFORCE TITANIUM 50MM HIGH-END SOUND DRIVERS — With titanium-coated diaphragms for added clarity, our new, cutting-edge proprietary design divides the driver into 3 parts for the individual tuning of highs, mids, and lowsproducing brighter, clearer audio with richer highs and more powerful lows - LIGHTWEIGHT DESIGN WITH BREATHABLE FOAM EAR CUSHIONS — At just 240g, the BlackShark V2X is engineered from the ground up for maximum comfort - RAZER HYPERCLEAR CARDIOID MIC — Improved pickup pattern ensures more voice and less noise as it tapers off towards the mic’s back and sides - CROSS-PLATFORM COMPATIBILITY — Works with PC, Mac, PS4, Xbox One, Nintendo Switch via 3.5mm jack, enjoy unfair audio advantage across almost every platform. *Xbox One stereo adapter may be required, purchase separately - #1 SELLING PC GAMING PERIPHERALS BRAND IN THE U.S. — Source — Circana, Retail Tracking Service, U.S., Dollar Sales, Gaming Designed Mice, Keyboards, and PC Headsets, Jan. 2019- Dec. 2023 combined",
"sponsored_products": [
{
"asin": "B09ZW52XSQ",
"image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$212.95",
"product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360° Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch",
"rating": "4",
"reviews": "1,280",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0BY1HQBSX",
"image_url": "https://m.media-amazon.com/images/I/41rBaCbsqtL._AC_UF480,480_SR480,480_.jpg",
"price": "$179.99",
"product_name": "Razer BlackShark V2 Pro Wireless Gaming Headset 2023 Edition: Detachable Mic - Pro-Tuned FPS Profiles - 50mm Drivers - Noise-Isolating Earcups w/Ultra-Soft Memory Foam - 70 Hr Battery Life - White",
"rating": "4",
"reviews": "11,324",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2MzUxNTQyOTkwMjo6Ojo&url=%2Fdp%2FB0BY1HQBSX%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0BY1HQBSX%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B07QNZC9V5",
"image_url": "https://m.media-amazon.com/images/I/419PSmh-1yL._AC_UF480,480_SR480,480_.jpg",
"price": "$89.95",
"product_name": "Razer Kraken Gaming Headset: Lightweight Aluminum Frame - Retractable Noise Isolating Microphone - for PC, PS4, PS5, Switch, Xbox One, Xbox Series X & S, Mobile - 3.5 mm Headphone Jack - Black/Blue",
"rating": "4",
"reviews": "48,125",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU2NjQ2MzEzOTUwMjo6Ojo&url=%2Fdp%2FB07QNZC9V5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB07QNZC9V5%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0CW34HBKZ",
"image_url": "https://m.media-amazon.com/images/I/41tkhLYy1mL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$69.99",
"product_name": "Logitech G Pro X SE Wired Gaming Headset: Blue VO!CE Detachable Boom Mic, DTS 7.1, 50 mm Drivers, USB/3.5mm Aux, USB DAC Included, for PC, Xbox, PS5, PS4 - Black - G Pro X SE Wired Gaming Headset",
"rating": "4",
"reviews": "6,729",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDM1Mjk5NjU0NTgwMjo6Ojo&url=%2Fdp%2FB0CW34HBKZ%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0CW34HBKZ%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0B15QM5LL",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$153.99",
"product_name": "SteelSeries Arctis Nova 7 Wireless Multi-Platform Gaming Headset — Neodymium Magnetic Drivers — 2.4GHz + Mixable Bluetooth — 38Hr USB-C Battery — ClearCast Gen2 AI Mic — PC, PS5, Switch, VR, Mobile",
"rating": "4",
"reviews": "5,892",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDExMzMyNjMyNzQ5ODo6Ojo&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDExMzMyNjMyNzQ5ODo6Ojo&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0DDKK2R3C",
"image_url": "https://m.media-amazon.com/images/I/41xz798fVLL._AC_UF480,480_SR480,480_.jpg",
"price": "$33.99",
"product_name": "SENZER SG600 Pro Wireless Gaming Headset with Microphone - 7.1 Surround Sound, Noise Canceling Mic, 2.4GHz Wireless & Bluetooth 5.3 - Foldable Gaming Headphones for PC PS5 PS4 (Not Xbox Compatible)",
"rating": "4",
"reviews": "481",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU4NzQ3NDMwMTEwMjo6Ojo&url=%2Fdp%2FB0DDKK2R3C%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0DDKK2R3C%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B01H6GUCCQ",
"image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$19.99",
"product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo",
"rating": "4",
"reviews": "108,513",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODg2Njg3NjM4MDk3MjAyOjE3Mzk5MDYyOTU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3Dh7dv0%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UU"
},
{
"asin": "B0C1NT9W9K",
"image_url": "https://m.media-amazon.com/images/I/412vPN0VcdL._AC_UF480,480_SR480,480_.jpg",
"price": "$17.99",
"product_name": "USB Headset with Microphone for PC Laptop - Wired Computer Headphones with Noise Ca...",
"rating": "4",
"reviews": "655",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDA0MjM0ODgwNzkwMDI6Ojo6&url=%2Fdp%2FB0C1NT9W9K%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0C1NT9W9K%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B09ZWKD9TF",
"image_url": "https://m.media-amazon.com/images/I/312MvjLsRXL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$306.99",
"product_name": "SteelSeries Arctis Nova Pro Wireless Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Active Noise Cancellation Infinity Power System - Stealth Mic - Xbox, PC, PS5, PS4, Switch, Mobile",
"rating": "4",
"reviews": "5,928",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjoyMDAwNTkyMjcyMTAxOTg6Ojo6&url=%2Fdp%2FB09ZWKD9TF%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB09ZWKD9TF%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0D3XMVS73",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$26.99",
"product_name": "Wireless Gaming Headset for PC, PS5, PS4, Mac, Nintendo Switch, Gaming Headphones w...",
"rating": "4",
"reviews": "1,182",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDA1ODc3NTIwMDY0MDI6Ojo6&url=%2Fdp%2FB0D3XMVS73%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0D3XMVS73%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDA1ODc3NTIwMDY0MDI6Ojo6&url=%2Fdp%2FB0D3XMVS73%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0D3XMVS73%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0D4QVXY78",
"image_url": "https://m.media-amazon.com/images/I/31IcWSpdOAL._AC_UF480,480_SR480,480_.jpg",
"price": "$79.99",
"product_name": "OXS Storm G2 Wireless Gaming Headsets, 7.1 Virtual Surround Sound, 3 EQ Modes, 2.4G Low Latency, 50mm Driver, 40H Playtime, RGB Light, Bluetooth 5.3, Compatible with PC, Console, Mobile, Black",
"rating": "4",
"reviews": "74",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDAyODk4MjgxNzcyMDI6Ojo6&url=%2Fdp%2FB0D4QVXY78%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0D4QVXY78%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B09ZW52XSQ",
"image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$212.95",
"product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360° Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch",
"rating": "4",
"reviews": "1,280",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjoyMDAwNTk1NTU5MTM4OTg6Ojo6&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0BY1HQBSX",
"image_url": "https://m.media-amazon.com/images/I/41rBaCbsqtL._AC_UF480,480_SR480,480_.jpg",
"price": "$179.99",
"product_name": "Razer BlackShark V2 Pro Wireless Gaming Headset 2023 Edition: Detachable Mic - Pro-Tuned FPS Profiles - 50mm Drivers - Noise-Isolating Earcups w/Ultra-Soft Memory Foam - 70 Hr Battery Life - White",
"rating": "4",
"reviews": "11,324",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjozMDA2NjM1MTU0Mjk5MDI6Ojo6&url=%2Fdp%2FB0BY1HQBSX%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0BY1HQBSX%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0B15QM5LL",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$153.99",
"product_name": "SteelSeries Arctis Nova 7 Wireless Multi-Platform Gaming Headset — Neodymium Magnetic Drivers — 2.4GHz + Mixable Bluetooth — 38Hr USB-C Battery — ClearCast Gen2 AI Mic — PC, PS5, Switch, VR, Mobile",
"rating": "4",
"reviews": "5,892",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjoyMDAxMTMzMjYzMjc0OTg6Ojo6&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo3NjgxOTA2NDkzNzgzOTQ5OjE3Mzk5MDYyOTU6c3BfZGV0YWlsMjoyMDAxMTMzMjYzMjc0OTg6Ojo6&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3DvXRjG%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DG7TM5EQGRGESEZ1GWYQY%26pd_rd_wg%3D5UENK%26pd_rd_r%3D4f8fd24c-0296-4b05-b4a7-dea7015779fe%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
}
],
"url": "https://www.amazon.com/Razer-BlackShark-V2-Gaming-Headset/dp/B086PKMZ21/ref=sr_1_4?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-4&th=1",
"variation_asin": [
{
"asin": "B0CXGTGPZQ",
"size_name": "3.5mm"
},
{
"asin": "B0CXH14PPD",
"size_name": "3.5mm"
},
{
"asin": "B0B7KKD78B",
"size_name": "USB"
},
{
"asin": "B09PZG4R17",
"size_name": "3.5mm"
},
{
"asin": "B086PKMZ21",
"size_name": "3.5mm"
},
{
"asin": "B09CLWQ45V",
"size_name": "3.5mm"
},
{
"asin": "B0BFJS31G8",
"size_name": "3.5mm"
},
{
"asin": "B0CXGTGPZQ",
"color_name": "Classic Black"
},
{
"asin": "B0CXH14PPD",
"color_name": "Classic Black"
},
{
"asin": "B0B7KKD78B",
"color_name": "Black"
},
{
"asin": "B09PZG4R17",
"color_name": "White"
},
{
"asin": "B086PKMZ21",
"color_name": "Black"
},
{
"asin": "B09CLWQ45V",
"color_name": "Green"
},
{
"asin": "B0BFJS31G8",
"color_name": "Quartz Pink"
},
{
"asin": "B0CXGTGPZQ",
"style_name": "Xbox"
},
{
"asin": "B0CXH14PPD",
"style_name": "PlayStation"
},
{
"asin": "B0B7KKD78B",
"style_name": "PC"
},
{
"asin": "B09PZG4R17",
"style_name": "PC"
},
{
"asin": "B086PKMZ21",
"style_name": "PC"
},
{
"asin": "B09CLWQ45V",
"style_name": "PC"
},
{
"asin": "B0BFJS31G8",
"style_name": "PC"
}
]
},
{
"asin": "B01H6GUCCQ",
"attributes": "color: Blue",
"availability_status": "In Stock",
"available_quantity": null,
"brand": "BENGOO",
"category": [
{
"level": 1,
"name": "Video Games",
"url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"
},
{
"level": 2,
"name": "Legacy Systems",
"url": "/Systems-Games/b/ref=dp_bc_aui_C_2?ie=UTF8&node=294940"
},
{
"level": 3,
"name": "Nintendo Systems",
"url": "/b/ref=dp_bc_aui_C_3?ie=UTF8&node=23563593011"
},
{
"level": 4,
"name": "Nintendo 3DS & 2DS",
"url": "/Nintendo-3DS-Games-Hardware-Consoles/b/ref=dp_bc_aui_C_4?ie=UTF8&node=2622269011"
},
{
"level": 5,
"name": "Accessories",
"url": "/Nintendo-3DS-Accessories/b/ref=dp_bc_aui_C_5?ie=UTF8&node=2622272011"
}
],
"currency": "USD",
"frequently_bought_together": null,
"full_description": "Previous page Next page The video showcases the product in use. The video guides you through product setup. The video compares multiple products. The video shows the product being unpacked.",
"highlighted_specifications": {
"Brand": "BENGOO",
"Color": "Blue",
"Ear Placement": "Over Ear",
"Form Factor": "Over Ear",
"Noise Control": "Sound Isolation"
},
"image_urls": [
"https://m.media-amazon.com/images/I/61CGHv6kmWL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/71z2WmHMtZL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/71UAwQgt-cL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/71Ie8vokMuL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/71rxKLsCxqL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/71dybzbdO9L._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/71732pdsbQL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/71sOPtDbN7L._AC_SL1000_.jpg"
],
"model": "G9000",
"name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo",
"product_category": "Video Games > Legacy Systems > Nintendo Systems > Nintendo 3DS & 2DS > Accessories",
"product_information": {
"ASIN": "B01H6GUCCQ",
"Age Range (Description)": "Adult",
"Amazon Best Sellers Rank": "#20 in Video Games , #1 in Nintendo 3DS & 2DS Accessories , #2 in PC Game Headsets , #2 in Mac Game Headsets",
"Audio Driver Type": "Dynamic Driver",
"Cable Feature": "Detachable",
"Carrying Case Weight": "0.1 Pounds",
"Compatible Devices": "PS4, Xbox One, PS5, PC, NES, Mac",
"Connectivity Technology": "Wired",
"Control Method": "Touch",
"Control Type": "Volume Control",
"Country of Origin": "China",
"Date First Available": "June 22, 2016",
"Global Trade Identification Number": "00613865268579",
"Hardware Platform": "PCPS4MACXBOX ONEXBOX 360",
"Headphones Jack": "3.5 mm Jack",
"Included Components": "Headphone",
"Is Autographed": "No",
"Is Discontinued By Manufacturer": "No",
"Item Dimensions LxWxH": "8.3 x 4.4 x 7.9 inches",
"Item Weight": "9.6 ounces",
"Item model number": "G9000",
"Manufacturer": "BENGOO",
"Material": "Faux Leather, Metal",
"Model Name": "G9000",
"Package Type": "FFP (Flat Free Package) or equivalent Amazon certified package",
"Product Dimensions": "8.3 x 4.4 x 7.9 inches",
"Recommended Uses For Product": "Calling, Gaming",
"Specific Uses For Product": "Gaming",
"Theme": "Video Game",
"UPC": "716045368943 712073576640 613865268579 716045603754 715668392526 759321850411 608560160938 712073576169 791313786056 601490994185",
"Unit Count": "1.0 Count"
},
"product_reviews": [
{
"author_name": "Robyn Simmons",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHFLGDCI5VVQARODNRGA56W2V7PA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I’m so impressed with this gaming headset! It’s truly plug and play—no complicated setup, just plug it in and you’re good to go. The sound quality is amazing, and the microphone picks up my voice clearly without any issues. It’s also incredibly comfortable to wear for long gaming sessions. The ear cups are soft and fit well, so no discomfort even after hours of use. The headset feels sturdy and well-built, so I’m confident it will last through lots of gaming sessions. Overall, this is a fantastic headset for the price. It’s easy to use, comfortable, and durable—exactly what I was looking for. Highly recommend it to any gamer!",
"review_title": "Fantastic Gaming Headset – Easy, Comfortable, and Durable!",
"review_url": "https://www.amazon.com/gp/customer-reviews/R2YIRGYRQJYKPW/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ",
"reviewed_date": "February 09, 2025",
"reviewed_product_variant": "Color: Blue"
},
{
"author_name": "Dee",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AGK6AUZYYRFNSSLOW4UEJ6F5HBXQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "\"I’m really impressed with the BENGOO G9000 Stereo Gaming Headset. It’s perfect for PS4, PC, Xbox One, PS5, and other platforms. The sound quality is fantastic, with bass surround that enhances the gaming experience. The noise-cancelling mic works great for clear communication during games, and the LED light adds a cool touch to the overall design. The over-ear headphones are very comfortable, and the soft memory earmuffs don’t hurt my ears after long gaming sessions. It’s well-built, with solid sound quality and clear mic performance for gaming or chatting. Plus, it’s compatible with multiple devices like laptops, Macs, and even Nintendo NES Games, making it a versatile headset. Pros: Excellent sound quality and bass surround Noise-cancelling mic for clear communication LED lights for a cool look Soft memory earmuffs for comfort Compatible with multiple gaming platforms Cons: None! Very happy with the headset. Overall, I highly recommend this headset for anyone looking for a comfortable, high-quality gaming experience!\"",
"review_title": "Excellent Gaming Headset – Comfortable and Great Sound Quality",
"review_url": "https://www.amazon.com/gp/customer-reviews/RRZ06YZC2JJH1/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ",
"reviewed_date": "January 25, 2025",
"reviewed_product_variant": "Color: Blue"
},
{
"author_name": "JUAN",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHMO42DMDCWHPZIC7VBOG4ONNAWQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "4.0",
"review_text": "I use these for call of duty and youtube some times my oculus 2. The rgb works with a smooth fade out loop although it's not addressable rgb it's pretty nice they even send adapters so it you want to power the rgb when your on xbox or ps5 it's independent from the controller power source (batteries) for pc you can just hook it up. Con the volume and mute switch on mine usually faces inward not a huge problem but sometimes moving around with raise or lower the volume a minor inconvenience if I would have designed it one would be on each side instead. Pros decent sound quality yesterday it saved me from being shot from behind in cod mw 2.0 the surround sound is decently crisp. The company is eager to please to to make sure you like it by the time I got it and started using it after a week they were checking up on how I liked it. After a couple messages back and forth he/she told me about the rgb being independent from the jack. Most of the rgb wired headphones I've seen aren't separated and only work on the pc. Now even watching TV (I have a projector) I can use the rgb. Microphone works as it should noise canceling I never hear complains from other players. The top fabric for comfort is comfortable I'm keeping the plastic they package it with to keep it clean. Each ear side get an addition inch approximately of length for people with bigger heads. The plastic ear cuffs are not going to flex unless to beat it with a heavy object the head band has just enough flex to it. And the microphone can be moved as it's flexible but also turned all the way pointing up . The head jack and usb splitter is pretty long about 6ft or so and it comes with a quality velcro cord piece to roll up for non use meaning if you wanted to you could put it on a headphone stand and hide the cords from you cat so it's not dangling. Suggestions to the company slightly thicker ear cups would be nice I got big ears so they kinda touch the inner fabric of the cuff and if I squeeze a little bit there's a little but of suction in my ears. Change the volume scrolling wheel to a sliding one and put it opposite of the microphone mute switch. Possible issues sometimes the microphone doesn't register on cod mw 2.0. However this is more likely to be call of duty chat program than the headphones because it happened multiple times with other headphones as well.",
"review_title": "Good headphones",
"review_url": "https://www.amazon.com/gp/customer-reviews/R25BORH9KHEJ5Y/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ",
"reviewed_date": "October 05, 2024",
"reviewed_product_variant": "Color: Blue"
},
{
"author_name": "RealDeal",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHZNOQG6ZOUC6U4YN2R6FXBI7CMA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "These Bengoo G9000 wired heaphones are my go to headphones when playing Xbox One! I just plug it into my controller and I'm all set for gaming and chat. They are comfortable after hours of play, don't hurt my ears, have great sound quality, and the mic still works great! In the past, I've had Turtle Beach headphones ($200+), some other no-name brand headphones (also for about $20 on Amazon), and even Amazon Basic blue tooth headphones. All of these have broken or had its problems with connection or wiring, hurting my head and ears, or just stopped working; which is why I'm writing this review. Just letting others know if they are on the fence about this headset, they are pretty solid. The cons that I have with these after 4 years of use are: 1) 3.5mm plug - would be better if it had the option to go either 3.5mm or USB for voice/sound but I only use these for Xbox gaming so the 3.5mm works great for me. 2) After 4 years, the ear pads are starting to flake off so finding replacement ear pads has been challenging. It's almost cheaper to just buy a new set of G9000 but that seems like a real waste. 3) in-cable mic volume and on/off switch seems to be a little fragile; I don't play around with it much so that's not an issue for me Pros: 1) work like they should, never had issues with sound, connection, microphone 2) comfortable - my head doesn't hurt after long hours of use, my ears aren't sore or burning hot from being sucked into a vacuum by the ear cups 3) the cord is extra long so I can move about when I need to",
"review_title": "Bought these Bengoo G9000 Wired Headphones in 2021 and still going strong in 2025!",
"review_url": "https://www.amazon.com/gp/customer-reviews/R398O2SPMRMQB4/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ",
"reviewed_date": "February 14, 2025",
"reviewed_product_variant": "Color: Blue"
},
{
"author_name": "B&K Garside",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHQUWFSXCI7HBEIYV2K6NAJ5FC2Q/ref=cm_cr_dp_d_gw_pop?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I was skeptical due to price but it's very comfortable to wear. I like the adjustable length around the head, especially the soft head rest underneath at the top and the soft over the ear muffs and decent speakers for good quality sound. I was pleasantly surprised. The mic works just fine. Took me a few secs to figure out the mic but it works great. I like the adjustable controls. All around a good product.",
"review_title": "Functions great. Good quality for reasonable price.",
"review_url": "https://www.amazon.com/gp/customer-reviews/RU7ETQJU72NA0/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B01H6GUCCQ",
"reviewed_date": "January 13, 2025",
"reviewed_product_variant": "Color: Blue"
},
{
"author_name": "Michael",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "These headphones are amazing! they are pretty cool, I love it when I first saw it. It has two plugs for two different things. It's realy easy for me to change the volume, and you can mute/open the mic pretty easily. Everything I heard from it is really clear, you can hear everything that your friend says, even whispers. And these are not easy to break, it can really survive from some normal hits. These are one of the best headphones I've used!",
"review_title": "Amazing headphones!",
"review_url": null,
"reviewed_date": "November 17, 2024",
"reviewed_product_variant": "Color: Blue"
},
{
"author_name": "Carlos",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Son cómodos y tiene un buen sonido nada espectacular pero bueno para juegos",
"review_title": "Buen sonido",
"review_url": null,
"reviewed_date": "August 11, 2023",
"reviewed_product_variant": "Color: Blue"
},
{
"author_name": "SANTOS SOTA",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "MAGNÍFICO SONIDO ESTÉREO. LO YA INDICADO RELACIÓN CALIDAD/PRECIO, ENVÍO MUY RÁPIDO POR PARTE DEL VENDEDOR. TANTO POSITIVO QUE HE COMPRADO OTRO PARA TENERLO DE REPUESTO SIN BUSCAR NADA CUANDO CON EL TIEMPO DE USO SE ESTROPEE ÉSTE",
"review_title": "OPTIMA RELACIÓN CALIDAD/PRECIO",
"review_url": null,
"reviewed_date": "December 21, 2024",
"reviewed_product_variant": "Color: Blue"
},
{
"author_name": "Rony",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "3.0",
"review_text": "واجهتنا مشكله في الاسلاك ولكن المنتج لاباس به",
"review_title": "جيد",
"review_url": null,
"reviewed_date": "November 16, 2024",
"reviewed_product_variant": "Color: Blue"
},
{
"author_name": "A.R.1969",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Die Kopfhörer wurden jetzt schon mehrmals von uns bestellt. Für den Preis bieten sie eine angemessene Qualität. Sie lassen sich gut tragen, die Klangqualität ist völlig in Ordnung und ihre Lebensdauer ist bei normaler Nutzung absolut ok. Ich bin positiv überrascht und empfehle denjenigen einen Kauf, die keine überhohen Ansprüche an die Kopfhörer haben, denn Profi-Geräte gibt es zu diesem Preis ganz bestimmt nicht.",
"review_title": "Gür den Preis ein richtiges Schnäppchen!",
"review_url": null,
"reviewed_date": "March 26, 2024",
"reviewed_product_variant": "Color: Blue"
}
],
"product_variations": {
"color_name": [
"Black",
"Blue",
"Green",
"Orange",
"Pink",
"Purple",
"Red",
"White"
]
},
"rating": "4.3",
"rating_histogram": {
"five_star": "66%",
"four_star": "15%",
"one_star": "7%",
"three_star": "8%",
"two_star": "4%"
},
"regular_price": "35.99",
"review_count": "108,513",
"sale_price": "19.99",
"seller": "Bengoo Inc.Bengoo Inc.",
"seller_url": "https://www.amazon.com/gp/help/seller/at-a-glance.html/ref=dp_merchant_link?ie=UTF8&seller=A1BCXRJQ9212UU&asin=B01H6GUCCQ&ref_=dp_merchant_link&isAmazonFulfilled=1",
"shipping_charge": null,
"small_description": "【Multi-Platform Compatible】Support PlayStation 4, New Xbox One, PC, Nintendo 3DS, Laptop, PSP, Tablet, iPad, Computer, Mobile Phone. Please note you need an extra Microsoft Adapter (Not Included) when connect with an old version Xbox One controller. - 【Surrounding Stereo Subwoofer】Clear sound operating strong brass, splendid ambient noise isolation and high precision 40mm magnetic neodymium driver, acoustic positioning precision enhance the sensitivity of the speaker unit, bringing you vivid sound field, sound clarity, shock feeling sound. Perfect for various games like Halo 5 Guardians, Metal Gear Solid, Call of Duty, Star Wars Battlefront, Overwatch, World of Warcraft Legion, etc. - 【Noise Isolating Microphone】Headset integrated onmi-directional microphone can transmits high quality communication with its premium noise-concellng feature, can pick up sounds with great sensitivity and remove the noise, which enables you clearly deliver or receive messages while you are in a game. Long flexible mic design very convenient to adjust angle of the microphone. - 【Great Humanized Design】Superior comfortable and good air permeability protein over-ear pads, muti-points headbeam, acord with human body engineering specification can reduce hearing impairment and heat sweat.Skin friendly leather material for a longer period of wearing. Glaring LED lights desigend on the earcups to highlight game atmosphere. - 【Effortlessly Volume Control】High tensile strength, anti-winding braided USB cable with rotary volume controller and key microphone mute effectively prevents the 49-inches long cable from twining and allows you to control the volume easily and mute the mic as effortless volume control one key mute.",
"sponsored_products": [
{
"asin": "B07XHGLSGF",
"image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg",
"price": "$32.99",
"product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center",
"rating": "4",
"reviews": "12,179",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU5NzUwMjE2MzkwMjo6Ojo&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B09FXFSY6R",
"image_url": "https://m.media-amazon.com/images/I/51yg9upokuL._AC_UF480,480_SR480,480_.jpg",
"price": "$17.99",
"product_name": "Gaming Headset for PC, Ps5, Switch, Mobile, Gaming Headphones for Nintendo with Noi...",
"rating": "4",
"reviews": "6,743",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDE1OTk3NTA4MDcwMjo6Ojo&url=%2Fdp%2FB09FXFSY6R%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB09FXFSY6R%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B096VRK6J5",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$33.99",
"product_name": "BINNUNE Wireless Gaming Headset with Microphone for PC PS4 PS5, 2.4G Wireless Bluetooth USB Gamer Headphones with Mic for Laptop Computer",
"rating": "4",
"reviews": "11,435",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDMxMDA0NTQ3MTUwMjo6Ojo&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDMxMDA0NTQ3MTUwMjo6Ojo&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B076DWKD5B",
"image_url": "https://m.media-amazon.com/images/I/41GMkz1amLL._AC_UF480,480_SR480,480_.jpg",
"price": "$23.98",
"product_name": "BENGOO V-4 Gaming Headset for Xbox Series X|S, Xbox One, PS5, PC, Mac, Nintendo Switch, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs",
"rating": "4",
"reviews": "18,635",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA4ODYxMDQ2MTcxMTo6Ojo&url=%2Fdp%2FB076DWKD5B%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB076DWKD5B%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0DCZLZ43C",
"image_url": "https://m.media-amazon.com/images/I/51aF0fiPIUL._AC_UF480,480_SR480,480_.jpg",
"price": "$25.99",
"product_name": "Wireless Gaming Headset for Ps5 Ps4 PC Switch Wireless Gaming Headphones 2.4GHz USB...",
"rating": "4",
"reviews": "86",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU3OTE4MjA5MTAwMjo6Ojo&url=%2Fdp%2FB0DCZLZ43C%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0DCZLZ43C%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1MCUL09GNRZKI"
},
{
"asin": "B0DBLHVGV7",
"image_url": "https://m.media-amazon.com/images/I/41AsluAshiL._AC_UF480,480_SR480,480_.jpg",
"price": "$15.99",
"product_name": "S30 Gaming Headset with Microphone,198g Lightweight Design, Gaming Headphones for X...",
"rating": "4",
"reviews": "360",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ3MjI4OTE2OTMwMjo6Ojo&url=%2Fdp%2FB0DBLHVGV7%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0DBLHVGV7%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B07R4R75DP",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$21.99",
"product_name": "Pacrate Gaming Headset for PS5/PS4/Xbox One/Nintendo Switch/PC/Mac, PS5 Headset with Microphone Xbox Headset with LED Lights, Noise Cancelling PS4 Headset for Kids Adults - Blue",
"rating": "4",
"reviews": "20,306",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDYwNzA3MTk2MDMwMjo6Ojo&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo2NTc3ODUxMDMyNTk4MDUwOjE3Mzk5MDYyOTQ6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDYwNzA3MTk2MDMwMjo6Ojo&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DUPWKA%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B09ZW52XSQ",
"image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$212.95",
"product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360° Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch",
"rating": "4",
"reviews": "1,280",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwNTk1NTU5MTM4OTg6Ojo6&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B081415GCS",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$119.99",
"product_name": "Logitech G733 Lightspeed Wireless Gaming Headset with Suspension Headband, Lightsync RGB, Blue VO!CE mic technology and PRO-G audio drivers - Black",
"rating": "4",
"reviews": "17,266",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAyMTIwMTgxOTgzMDI6Ojo6&url=%2Fdp%2FB081415GCS%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB081415GCS%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAyMTIwMTgxOTgzMDI6Ojo6&url=%2Fdp%2FB081415GCS%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB081415GCS%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0C4ND25FT",
"image_url": "https://m.media-amazon.com/images/I/41TSn76LbZL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$37.99",
"product_name": "FIFINE PC Gaming Headset, USB Headset with 7.1 Surround Sound, Detachable Microphone, Control Box, 3.5mm Headphones Jack, Over-Ear Wired Headset for PS5/Xbox/Switch, Black-AmpliGame H9",
"rating": "4",
"reviews": "1,332",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAwNTU0OTQ2NTM1MDI6Ojo6&url=%2Fdp%2FB0C4ND25FT%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0C4ND25FT%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0CLLJC6QC",
"image_url": "https://m.media-amazon.com/images/I/41PGf7xj-iL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$39.99",
"product_name": "Wireless Gaming Headset, 7.1 Surround Sound, 2.4Ghz USB Gaming Headphones with Blue...",
"rating": "4",
"reviews": "895",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAyMDI2MDcxNTU0MDI6Ojo6&url=%2Fdp%2FB0CLLJC6QC%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0CLLJC6QC%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B07XHGLSGF",
"image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg",
"price": "$32.99",
"product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center",
"rating": "4",
"reviews": "12,179",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1OTc1MDIxNjM5MDI6Ojo6&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B096VRK6J5",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$33.99",
"product_name": "BINNUNE Wireless Gaming Headset with Microphone for PC PS4 PS5, 2.4G Wireless Bluetooth USB Gamer Headphones with Mic for Laptop Computer",
"rating": "4",
"reviews": "11,435",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAzMTAwNDU0NzE1MDI6Ojo6&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAzMTAwNDU0NzE1MDI6Ojo6&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B076DWKD5B",
"image_url": "https://m.media-amazon.com/images/I/41GMkz1amLL._AC_UF480,480_SR480,480_.jpg",
"price": "$23.98",
"product_name": "BENGOO V-4 Gaming Headset for Xbox Series X|S, Xbox One, PS5, PC, Mac, Nintendo Switch, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs",
"rating": "4",
"reviews": "18,635",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTozMjA3MTEyMDA5OTc5MTQ1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjoyMDAwODg2MTA0NjE3MTE6Ojo6&url=%2Fdp%2FB076DWKD5B%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB076DWKD5B%26pd_rd_w%3DBuih3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DSVK9676XYGQYEJD85VAN%26pd_rd_wg%3DMDKM6%26pd_rd_r%3D629b11f6-1b9f-458e-8282-0be8db84c1df%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
}
],
"url": "https://www.amazon.com/BENGOO-G9000-Controller-Cancelling-Headphones/dp/B01H6GUCCQ/ref=sr_1_8?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-8&th=1",
"variation_asin": [
{
"asin": "B0982NYVQV",
"color_name": "Black"
},
{
"asin": "B08ZCHLZX9",
"color_name": "Green"
},
{
"asin": "B082VCPF1W",
"color_name": "Orange"
},
{
"asin": "B081JP3MJK",
"color_name": "Red"
},
{
"asin": "B01H6GUCCQ",
"color_name": "Blue"
},
{
"asin": "B08FDPNVJC",
"color_name": "Pink"
},
{
"asin": "B07VVHV6XV",
"color_name": "Purple"
},
{
"asin": "B08ZCQWGTG",
"color_name": "White"
}
]
},
{
"asin": "B0DM9HBJW7",
"attributes": null,
"availability_status": "In Stock",
"available_quantity": null,
"brand": "PHNIXGAM",
"category": [],
"currency": "USD",
"frequently_bought_together": null,
"full_description": null,
"highlighted_specifications": {
"Brand": "PHNIXGAM",
"Color": "Purple",
"Ear Placement": "Over Ear",
"Form Factor": "Over Ear",
"Noise Control": "Active Noise Cancellation"
},
"image_urls": [
"https://m.media-amazon.com/images/I/61Kj23p1XxL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/611FgU+A0OL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61opHx7lk3L._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71GSaj0R3YL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71oWtZP1fZL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61QfzbumooL._AC_SL1500_.jpg"
],
"model": "K9 07",
"name": "Gaming Headset for PS4, PS5, Xbox One X/S (No Adapter), 3.5mm Wired Headphones with Detachable Cat Ears, Microphone, RGB Backlight, Surround Sound, Purple",
"product_category": null,
"product_information": {
"ASIN": "B0DM9HBJW7",
"Age Range (Description)": "Adult",
"Audio Driver Size": "5E+1 Millimeters",
"Audio Driver Type": "Dynamic Driver",
"Compatible Devices": "Mobile Phones, Tablets, Computers, PS4, PS5, Xbox One (with adapter for older models)",
"Connectivity Technology": "Wired",
"Control Type": "Media Control",
"Controller Type": "Gamepad",
"Country of Origin": "China",
"Date First Available": "November 7, 2024",
"Earpiece Shape": "over_ear",
"Headphones Jack": "3.5 mm Jack",
"Included Components": "1 * User Manual, 1 * Gaming Headset",
"Is Autographed": "No",
"Item Weight": "1.21 pounds",
"Item model number": "K9 07",
"Manufacturer": "PHNIXGAM",
"Material": "Memory Foam",
"Model Name": "K9 07",
"Number of Items": "1",
"Package Dimensions": "8.86 x 7.87 x 3.9 inches",
"Package Type": "Box Packaging",
"Recommended Uses For Product": "Gaming",
"Specific Uses For Product": "Gaming",
"Style": "Gaming",
"Theme": "Anime",
"Water Resistance Level": "Not Water Resistant"
},
"product_reviews": [
{
"author_name": "Draknus",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEAI6OSRCNT7WT4FQF6O6IZV2LUQ/ref=cm_cr_dp_d_gw_pop?ie=UTF8",
"badge": null,
"rating": "5.0",
"review_text": "The cat ears are very easily removable and easy to put back on, which is great because I have weak hands. I love the volume wheel on the side of the little toggle box, and I love how easy it is to mute and unmute. The mic being able to be stowed out of the way is also great. It's a really comfortable headset to use, and the sound quality is above average in my opinion. No regrets here, it's cute and good quality and I love it.",
"review_title": "Cute And Comfortable Headset!",
"review_url": "https://www.amazon.com/gp/customer-reviews/RNMC4A8JVO31I/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7",
"reviewed_date": "January 27, 2025",
"reviewed_product_variant": null
},
{
"author_name": "John Baltisberger",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AGUEAG4BHFHYE5A37AOHD4HTFE4Q/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": null,
"rating": "5.0",
"review_text": "Got these for my daughter, she loves them, the ears are detachable so you can choose whether to wear them or not.",
"review_title": "Daughter loves these",
"review_url": "https://www.amazon.com/gp/customer-reviews/R2K561S25KN60K/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7",
"reviewed_date": "February 05, 2025",
"reviewed_product_variant": null
},
{
"author_name": "Hardman",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHPMUTP2LYCR3JITW34AAF2XL4FA/ref=cm_cr_dp_d_gw_pop?ie=UTF8",
"badge": null,
"rating": "4.0",
"review_text": "These Headphones are a stylish and functional choice for gamers, offering a range of features to enhance the gaming experience. The 3.5mm wired connection is convenient for multiple platforms like PS4, PS5, and Xbox One X/S, requiring no additional adapter. The headset boasts a detachable cat ear design, which adds a fun, customizable touch, especially for those who love a bit of flair. These were happily recieved by my 7 year old daughter who really loves the kitty ears look. The \"noise-canceling\" microphone is supposed to ensure clear communication, while the RGB backlight adds a vibrant, immersive effect. The microphone performance is okay. Additionally, the surround sound feature provides an engaging audio experience. Overall, it’s a good choice for gamers looking for both aesthetics and performance in a budget-friendly headset.",
"review_title": "“Time spent with cats is never wasted.”",
"review_url": "https://www.amazon.com/gp/customer-reviews/R2WL35IBXS2HGS/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7",
"reviewed_date": "December 31, 2024",
"reviewed_product_variant": null
},
{
"author_name": "Smosh",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEUATSS6NCFIET36AYT6KYK4MERQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": null,
"rating": "5.0",
"review_text": "It is more comfortable that I expected. Good padding on the ears and headpiece. The cat ears are easily removable if you so choose, but why would you want to? Easy set up, just plugged them in and they worked. Easy controls on the cord. While I can't hear myself, other say they sound clear.",
"review_title": "Nice gaming headset",
"review_url": "https://www.amazon.com/gp/customer-reviews/RHDYRLVOMF4WX/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7",
"reviewed_date": "January 12, 2025",
"reviewed_product_variant": null
},
{
"author_name": "wl79",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHG27EAZPHL6T57WBZIIBJ5MJ7BA/ref=cm_cr_dp_d_gw_pop?ie=UTF8",
"badge": null,
"rating": "5.0",
"review_text": "My rabbit chewed up the cord to my old gaming headset, which I needed for a remote job I am interviewing for! This headset is a godsend! I will be going through the interview on Monday, but I've been using it on my laptop and it's working wonderfully. It also matches my computer keyboard and mouse :) The cat ears are detachable!! I really wanted the cute ears....but you have to be professional sometime; this offers the best of both worlds 💜",
"review_title": "Loving it!",
"review_url": "https://www.amazon.com/gp/customer-reviews/R1331CZJF1V6KT/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7",
"reviewed_date": "January 04, 2025",
"reviewed_product_variant": null
},
{
"author_name": "Clemen Samuels",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEBKIUGDJBED4UH7PSPFARNFBQ6Q/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": null,
"rating": "2.0",
"review_text": "I went thru a period of time thinking my xbox wireless headset by xbox/microsoft were failing for no reason and there was no recovering them to their golden days... Turns out my series X was overheating and a result was constant signal drops, notifications constantly saying \"headset connected\", going silent, and such... I was deep in a pubg game with 8 or less sometime and my headphones would go silent. Since fixed the issue with a fan and my headset has no issues. Hopefully this review will help at least one person. So...I ordered every headset I saw for about 2 weeks. Controller dongle with earbuds attached via bluetooth..3 earbud sets, 2 wired sets and. Dongle had interference issues with the paired earbuds. Only one wired set was worth mentioning, so I will. NUBWO, made some acceptable headphones. Will definitely look through their products in the future",
"review_title": "The sizing was not for me, they were just too big to be used",
"review_url": "https://www.amazon.com/gp/customer-reviews/RAEI1N9R1SAGL/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7",
"reviewed_date": "January 20, 2025",
"reviewed_product_variant": null
},
{
"author_name": "StacyLynn",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AH5EHU7EJUXQ73YSLECFWSPTL43Q/ref=cm_cr_dp_d_gw_pop?ie=UTF8",
"badge": null,
"rating": "5.0",
"review_text": "I LOVE them! I am rating 5 ⭐️'s for... ⭐️⭐️⭐️⭐️⭐️ Comfortable ear muffs! ⭐️⭐️⭐️⭐️⭐️ Excellent sound quality! ⭐️⭐️⭐️⭐️⭐️ Awesome \"giftable\" packaging! ⭐️⭐️⭐️⭐️⭐️ Working great with my laptop and my Xbox! ⭐️⭐️⭐️⭐️⭐️ Removeable kitty ears! ⭐️⭐️⭐️⭐️⭐️ My favorite color purple! ⭐️⭐️⭐️⭐️⭐️ THE FACT THAT THEY ARE TOTALLY ADORABLE! Who doesn't love kitty ears?! I just had to have these in my life, and I think you will love them too!",
"review_title": "I didnt think I would like these.",
"review_url": "https://www.amazon.com/gp/customer-reviews/R3B0CTR56BC72N/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7",
"reviewed_date": "January 06, 2025",
"reviewed_product_variant": null
},
{
"author_name": "Lara Cee",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AE4DTCVBS3GPDSCXHVE3ZRK24CWQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": null,
"rating": "4.0",
"review_text": "These headphones looked exactly like the photos and are super high quality. Love the lavender color and the cat ears. They work great too but the sound could be better.",
"review_title": "Cute high quality headphones",
"review_url": "https://www.amazon.com/gp/customer-reviews/R2A8FVIYGS1F9C/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DM9HBJW7",
"reviewed_date": "January 02, 2025",
"reviewed_product_variant": null
}
],
"product_variations": {},
"rating": "4.5",
"rating_histogram": {
"five_star": "71%",
"four_star": "20%",
"one_star": "0%",
"three_star": "0%",
"two_star": "9%"
},
"regular_price": null,
"review_count": "16",
"sale_price": "32.99",
"seller": "PHNIXGAM USPHNIXGAM US",
"seller_url": "https://www.amazon.com/gp/help/seller/at-a-glance.html/ref=dp_merchant_link?ie=UTF8&seller=A29F6LGV4C2HK5&asin=B0DM9HBJW7&ref_=dp_merchant_link&isAmazonFulfilled=1",
"shipping_charge": null,
"small_description": "Lovely Design: With purple appearance, removable silicon cat ears and cool RGB lighting, the headset will make you girls women look much adorable. The RGB backlight can be turned off with the switch on its line control - Comfortable to Wear: The headband has 7 adjustable sizes to fit different head shapes. The ear cups are large enough to wrap eras, and the ear-pads are made of memory foam. Comfortable to wear for a long time - Retractable Microphone: The microphone is rotating and can reduce environment noises to the maximum. Also it is retractable and retracted into the mic hole, so you need to pull it out for use. The mic can be turned off with the mute button on the line control - Surround Sound: With 50mm audio driver, the headphones deliver stereo sound. With them on ears, you can enjoy high quality music time or hear clearly where your rivals are in video games - Compatibility: This headset is wired, so it can only work with 3.5mm supported mobile phones, tablets, computers and game consoles like P54, PS5 and Xbox One. It does not work with wireless supported devices like XBOX REMOTE. It needs an extra Microsoft adapter to connect with an older Xbox One model. The headset USB cable is only used for RGB backlight. Connect the USB cable, then turn on the RGB switch on wire control box, the RGB will light up",
"sponsored_products": [],
"url": "https://www.amazon.com/Headphones-Detachable-Microphone-Backlight-Surround/dp/B0DM9HBJW7/ref=sr_1_10?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming+headphones&qid=1739906138&sprefix=gaming+headphones%2Caps%2C299&sr=8-10",
"variation_asin": []
},
{
"asin": "B07ZF8T63K",
"attributes": "color: Black",
"availability_status": "In Stock",
"available_quantity": null,
"brand": "ZIUMIER",
"category": [
{
"level": 1,
"name": "Video Games",
"url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"
},
{
"level": 2,
"name": "PlayStation 4",
"url": "/PlayStation-4-Games-Consoles-Accessories-Hardware/b/ref=dp_bc_aui_C_2?ie=UTF8&node=6427814011"
},
{
"level": 3,
"name": "Accessories",
"url": "/PlayStation-4-Hardware-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=6427815011"
},
{
"level": 4,
"name": "Headsets",
"url": "/PlayStation-4-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=6427826011"
}
],
"currency": "USD",
"frequently_bought_together": null,
"full_description": "The video showcases the product in use. The video guides you through product setup. The video compares multiple products. The video shows the product being unpacked. Surround Sound Gaming Headset Hear Enemies From All Sides Z20 Series is the wired headset for competitive gamers, with 50mm drivers to deliver premium audio tuned for gaming and create an immersive audio experience. Noise-Cancelling Microphone The Omnidirectional microphone focuses on your voice for crystal-clear voice comms that are heard loudly and clearly. Long-Lasting Comfort It's fitted with large-diameter breathable protein ear cushions which fit completely around the ears and provide passive noise isolation so you can enjoy gaming for hours One Headset for All Game Platfroms For gaming and Streaming Plug the 3.5mm jack into your gaming device, it supports PlayStation 4, Playstation 5, Xbox One, Xbox Series S, Xbox Series X, PC, Mac Compare gaming headsets Z20 Add to Cart Z66 Z30 M09 Buying Options Customer Reviews 4.3 out of 5 stars 10,466 10,971 4.2 out of 5 stars 3,729 3.9 out of 5 stars 107 Price $19.99 $ 19 . 99 $15.99 15 $28.99 28 — Connection Wired Wireless+Bluetooth Driver Size 50mm Inputs 3.5mm USB Controls In-Line Remote On-Ear Controls MIC undetachable,omnidirectional Detachable,omnidirectional Compatibility PS5,PS4,XBOX,Switch,PC,MAC PS5,PS4,Switch,PC,MAC",
"highlighted_specifications": {
"Brand": "ZIUMIER",
"Color": "Black",
"Ear Placement": "Over Ear",
"Form Factor": "Over Ear",
"Impedance": "32 Ohm"
},
"image_urls": [
"https://m.media-amazon.com/images/I/71nh1VxLzuL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61tsYw85INL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61fA6Nd0QbL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71mcE-oBU2L._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61pnc+x52vL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/614UOmc1qzL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/718dl-PD7UL._AC_SL1500_.jpg"
],
"model": "Z20 Black",
"name": "ZIUMIER Gaming Headset with Microphone, Compatible with PS4 PS5 Xbox One PC Laptop, Over-Ear Headphones with LED RGB Light, Noise Canceling Mic, 7.1 Stereo Surround Sound",
"product_category": "Video Games > PlayStation 4 > Accessories > Headsets",
"product_information": {
"ASIN": "B07ZF8T63K",
"Age Range (Description)": "Adults,Teens",
"Amazon Best Sellers Rank": "#229 in Video Games , #11 in PlayStation 4 Headsets",
"Audio Driver Size": "50 Millimeters",
"Audio Driver Type": "Dynamic Driver",
"Cable Feature": "Fixed",
"Carrying Case Color": "Black",
"Compatible Devices": "PC, PS4,PS5 controller, Xbox One,Xbox One S/X controller, Mac, laptop, Phone,Mac",
"Connectivity Technology": "Wired",
"Control Method": "Remote",
"Control Type": "Volume Control",
"Controller Type": "Button",
"Country of Origin": "China",
"Date First Available": "November 26, 2019",
"Earpiece Shape": "Over-Ear",
"Frequency Range": "20 Hz - 20,000 Hz",
"Frequency Response": "20 KHz",
"Global Trade Identification Number": "00754610868207",
"Headphones Jack": "3.5 mm Jack",
"Included Components": "User Manual, 1 * 1-to-2 Y Splitter Cable, 1 * Gaming Headset",
"Is Autographed": "No",
"Item Weight": "10.6 ounces",
"Item model number": "Z20 Black",
"Manufacturer": "ZIUMIER",
"Material": "Plastic",
"Model Name": "Z20",
"Noise Control": "None",
"Number of Items": "1",
"Number of Power Levels": "1",
"Package Dimensions": "12.2 x 8.9 x 5.55 inches",
"Package Type": "Standard Packing",
"Recommended Uses For Product": "Gaming",
"Specific Uses For Product": "Gaming",
"Style": "Gaming",
"Theme": "Video Game",
"UPC": "754610868207",
"Unit Count": "1.0 Count",
"Wireless Communication Technology": "Wired"
},
"product_reviews": [
{
"author_name": "Robyn Simmons",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHFLGDCI5VVQARODNRGA56W2V7PA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I’m really impressed with the ZIUMIER Gaming Headset! The sound quality is fantastic, providing clear and immersive audio that enhances my gaming experience. The bass is deep without being overwhelming, and the overall sound balance is excellent, whether I'm playing games or listening to music. The microphone also works great for in-game chats, with clear voice transmission and noise reduction. The headset is very comfortable to wear for long gaming sessions, thanks to the soft ear cushions and adjustable headband. It fits snugly without being too tight, which is a big plus for me. I also appreciate that it’s compatible with PS4, PS5, Xbox One, PC, and laptops, making it super versatile for all my devices. The build quality feels solid, and the cable is long enough to give me plenty of flexibility. Overall, this is a fantastic gaming headset at a great price, and I highly recommend it to anyone looking for quality sound and comfort.",
"review_title": "Great Sound Quality and Comfortable Fit!",
"review_url": "https://www.amazon.com/gp/customer-reviews/R3VQKLGWYWDTF8/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K",
"reviewed_date": "February 09, 2025",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "John",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHXOXOWLXCKIXGTIA67MJIFMJTRA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "ZIUMIER Z20 Gaming Headset with Microphone Review Rating: ★★★★★ (5/5) Introduction: The ZIUMIER Z20 Gaming Headset is a top-tier choice for gamers seeking an immersive audio experience coupled with exceptional comfort. With 50mm drivers, noise-canceling capabilities, and multi-platform compatibility, this headset is designed to elevate your gaming sessions, whether you're playing on a console, PC, or mobile device. Audio Quality: Equipped with 50mm drivers, the Z20 delivers superior audio performance that immerses you in your game, movie, or music. The virtual surround sound creates a sense of distance and depth, allowing you to pinpoint enemy locations and enjoy an enriched gaming experience. This is especially beneficial in FPS games like God of War, Fortnite, PUBG, and CS: GO. Microphone Performance: The Z20 features an omnidirectional sensitive microphone with advanced noise-canceling technology. This ensures high-quality communication by filtering out background noise, allowing your voice to be heard clearly by your teammates. The result is a significant improvement in voice quality and communication during intense gaming sessions. Comfort and Design: Comfort is a standout feature of the Z20. The lightweight design, breathable protein memory foam ear pads, and flexible headband provide optimal comfort even during long gaming marathons. The retractable head beam adjusts to fit various head sizes, ensuring a snug yet comfortable fit for every gamer. Durability: Constructed with durable materials, the Z20 is designed to withstand the rigors of frequent use. The 6.5ft high tensile strength, anti-winding braided cable ensures longevity and reduces the risk of tangling. The sturdy build quality means this headset will maintain its performance and appearance over time. Compatibility: The Z20 is a versatile headset compatible with multiple platforms, including PC, PS4, PS5, Xbox One, Xbox One S/X, laptops, Macs, tablets, and phones. The 3.5mm audio jack ensures easy connectivity, and while an adapter is required for the older Xbox One controller (model 1537), the headset's broad compatibility makes it a convenient choice for gamers with multiple devices. In-Line Control: The in-line control system of the Z20 is both convenient and user-friendly. The braided cable includes a rotary volume controller and a mute button for the microphone, making it easy to adjust settings on the fly. The USB connection is used exclusively for powering the LED lights, adding a stylish touch to the headset. Conclusion: The ZIUMIER Z20 Gaming Headset with Microphone offers a premium gaming experience with its superior audio quality, noise-canceling microphone, and exceptional comfort. Its robust build and multi-platform compatibility make it a valuable addition to any gamer's setup. Whether you're engaging in a fierce battle or enjoying a cinematic gaming experience, the Z20 delivers on all fronts. Pros: Superior audio performance with 50mm drivers Effective noise-canceling microphone Comfortable design with memory foam ear pads Durable, high-quality construction Wide compatibility with multiple devices Cons: Requires an adapter for older Xbox One controllers (model 1537) In summary, the ZIUMIER Z20 is a five-star gaming headset that provides an immersive and comfortable gaming experience, making it a must-have for serious gamers.",
"review_title": "Great Headphones!",
"review_url": "https://www.amazon.com/gp/customer-reviews/R3OTAH759ZCF6T/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K",
"reviewed_date": "August 02, 2024",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Sarah Harless",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFQMPVIWVGWOUBBFQ5YN3A35CGGA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "4.0",
"review_text": "I purchased these a while back. My old headphones (and i mean OLD) the audio port was goin bad. It was becoming an annoyance when one moment i could hear, id go to readjust my sitting, and the next moment i cant hear anything. These new headphones are great. The only complaint i have about these is the usb for the LEDs is to short. I dont game infront of a computer, i use a PS5 and there are times id love to plug in the usb, but the split cord for the LEDs isnt long enough to reach my available usb port. It just dangles there next to the audio jack inside my controller. If i could change the cord in manufacturing, id make the usb cord about 4ft long. But thats just me. If u game infront of a computer, these are perfect for u. Theyre comfy as well.",
"review_title": "Pretty Good, only 1 complaint.",
"review_url": "https://www.amazon.com/gp/customer-reviews/RPDIBM0RBIUBQ/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K",
"reviewed_date": "September 22, 2024",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Dan",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFEELMRBBEAUQ6X37K2ZEDEN52VQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Used for gaming, easy to use, affordable and not easily broken. Quality is great too, no crackling or echoing. Easy to hear too",
"review_title": "Exactly what I was looking for.",
"review_url": "https://www.amazon.com/gp/customer-reviews/R27PLNHOP19DRP/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K",
"reviewed_date": "February 01, 2025",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "NmunniE",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEHHZPZ5KNVXRLWXG6UKHIDRVAIQ/ref=cm_cr_dp_d_gw_pop?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "This headset is quite visually appealing though I’m not entirely sure why that is important to me as they are on the sides of my head during use and for the most part, I am unable to appreciate the true scope of all the rainbow swirly goodness but it’s a nice perk nonetheless. The little mic light also has its own little rainbow light show which is awesome AND visible. The ear cups and headband pad are super squishy and will certainly facilitate hours of Horde comfortably. Aesthetic and comfort wise these things are awesome albeit their sound is disappointing. Voices come in clearly, no complaints there but the game sound is quite tinny and bass leaves a lot to be desired. I did remove a star in the sound rating because of the aforementioned lacking sound quality and I wish the in-line volume went a bit higher. The Xbox One’s controller design is a bit of a nightmare since the port is located at the 6’oclock position and the cord tends to bend awkwardly because it gets in the way and I worry that will break or weaken the copper wire. The headset does include a little Velcro tie to make the long cords more manageable but the bending at the jack is a concern so maybe shrink wrap that part to immobilize it. I kinda of wish that the LED lights didn’t require a second USB cord to work but it’s not a huge issue as the cords are plenty long enough work with. I have a power strip with USB ports so I plug it in there or if you have a headset stand with USB ports even better. All in all it’s a cool headset that gets the job done, and they make my head look enchanted...or like I’m struggling to process something like the rainbow wheel on an Apple computer.",
"review_title": "Rad. (Xbox One)",
"review_url": "https://www.amazon.com/gp/customer-reviews/RNU3IMAJOZS4W/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B07ZF8T63K",
"reviewed_date": "March 14, 2020",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Andrea",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Meravigliose..comodissime e si sentono da Dio",
"review_title": "Ottimo materiale",
"review_url": null,
"reviewed_date": "November 17, 2022",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Uschi",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Super heatset gibt nichts dran auszusetzen. Wenn einen die lichter stören kein Problem kann man einfach den Stecker für die lichter entfernen. Man hört seine mitspieler super gut, außen Geräusche hört man fast gar nicht! Alles im allen ein super Gerät kann man nur empfehlen!",
"review_title": "Preisleistung top",
"review_url": null,
"reviewed_date": "May 13, 2022",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Cristina",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "funziona benissimo e ha soddisfatto tutte le aspettative. consiglio",
"review_title": "ottimo prodotto",
"review_url": null,
"reviewed_date": "September 17, 2022",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Marek",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Ok",
"review_title": "Ok",
"review_url": null,
"reviewed_date": "August 31, 2022",
"reviewed_product_variant": "Color: Black"
},
{
"author_name": "Amazon Kunde",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Toll",
"review_title": "Toll",
"review_url": null,
"reviewed_date": "April 02, 2022",
"reviewed_product_variant": "Color: Black"
}
],
"product_variations": {
"color_name": [
"Black",
"Camouflage",
"Green",
"Pink",
"Purple",
"White"
]
},
"rating": "4.3",
"rating_histogram": {
"five_star": "67%",
"four_star": "14%",
"one_star": "7%",
"three_star": "8%",
"two_star": "4%"
},
"regular_price": "29.99",
"review_count": "10,466",
"sale_price": "19.99",
"seller": "ZIUMIERZIUMIER",
"seller_url": "https://www.amazon.com/gp/help/seller/at-a-glance.html/ref=dp_merchant_link?ie=UTF8&seller=A1JXNP286MCB23&asin=B07ZF8T63K&ref_=dp_merchant_link&isAmazonFulfilled=1",
"shipping_charge": null,
"small_description": "PROFESSIONAL GAMING HEADPHONE. with 50mm drivers that deliver superior audio performance, ZIUMIER PS4 headset can generate a virtual surround sound experience to create distance and depth that enhances any gaming, movie or music experience. perfect for most FPS games like God of war, Fortnite, PUBG or CS: GO. - BUILT FOR COMFORT. ZIUMIER Z20 lightweight design Xbox one headset comes with breathable protein memory foam ear pads, retractable headbeam, and flexible headband to make sure every gamer can enjoy optimal wearing comfort in a long-time fierce game. - NOISE CANCELING MICROPHONE. An omnidirectional sensitive microphone with noise-cancelling tech can transmit high-quality communication. Get clearer voice quality and reduced background noise for an improved voice experience. - MULTI-PLATFORMS HEADSET. This gaming headset with a 3.5mm audio jack is compatible with PC, PlayStation 4, PlayStation 5, Xbox One, Xbox Series S, Xbox Series X (For Xbox One controller 1537, an adapter will be required to use this headset), Nintendo Switch, Laptop, Mac, Tablet, Phone - EFFORTLESSLY IN-LINE CONTROL. Our pc headset comes with 5ft high tensile strength, anti-winding braided cable with rotary volume controller & mute button for the microphone. Easy to reach, convenient to use. (The USB connection is ONLY used for lighting glaring moving LED lights)",
"sponsored_products": [
{
"asin": "B01H6GUCCQ",
"image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$19.99",
"product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo",
"rating": "4",
"reviews": "108,513",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1NjIyNTUwNjE5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1NjIyNTUwNjE5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UU"
},
{
"asin": "B08FX7T8Z4",
"image_url": "https://m.media-amazon.com/images/I/41pAw9XEAiL._AC_UF480,480_SR480,480_.jpg",
"price": "$36.99",
"product_name": "EKSA E900 Headset with Microphone for PC, PS4,PS5, Xbox - Detachable Noise Canceling Mic, 3D Surround Sound, Wired Headphone for Gaming, Computer, Laptop, 3.5MM Jack",
"rating": "4",
"reviews": "3,484",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDIzNTQ5NzUxMTMwMjo6Ojo&url=%2Fdp%2FB08FX7T8Z4%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB08FX7T8Z4%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B09FXFSY6R",
"image_url": "https://m.media-amazon.com/images/I/51yg9upokuL._AC_UF480,480_SR480,480_.jpg",
"price": "$17.99",
"product_name": "Gaming Headset for PC, Ps5, Switch, Mobile, Gaming Headphones for Nintendo with Noi...",
"rating": "4",
"reviews": "6,743",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDE1OTk3NTA4MDcwMjo6Ojo&url=%2Fdp%2FB09FXFSY6R%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB09FXFSY6R%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B07PRVS98X",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$49.99",
"product_name": "EKSA E900 Pro USB Gaming Headset for PC - Computer Headset with Detachable Noise Cancelling Mic, 7.1 Surround Sound, 50MM Driver - Headphones with Microphone for PS4/PS5, Xbox One, Laptop, Office",
"rating": "4",
"reviews": "5,119",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2NjM1MzI2NDAwMjo6Ojo&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDY2NjM1MzI2NDAwMjo6Ojo&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B07R4R75DP",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$21.99",
"product_name": "Pacrate Gaming Headset for PS5/PS4/Xbox One/Nintendo Switch/PC/Mac, PS5 Headset with Microphone Xbox Headset with LED Lights, Noise Cancelling PS4 Headset for Kids Adults - Blue",
"rating": "4",
"reviews": "20,306",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ1ODE0OTA0OTQwMjo6Ojo&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDQ1ODE0OTA0OTQwMjo6Ojo&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0CSZ1CD49",
"image_url": "https://m.media-amazon.com/images/I/418PKBl5h3L._AC_UF480,480_SR480,480_.jpg",
"price": "$26.99",
"product_name": "Gaming Headset with Microphone for PC PS4 PS5 Headset Noise Cancelling Gaming Headphones for Laptop Mac Switch Xbox One Headset with LED Lights Deep Bass for Kids Adults Deep Red",
"rating": "4",
"reviews": "19,883",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU2NzEwMTg5MzgwMjo6Ojo&url=%2Fdp%2FB0CSZ1CD49%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0CSZ1CD49%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0CH7WLFRN",
"image_url": "https://m.media-amazon.com/images/I/417WQ3bhMWL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$19.99",
"product_name": "PG1 Gaming Headset for PS4/PS5/PC/Xbox/Nintendo Switch, Xbox One Headset with AI St...",
"rating": "4",
"reviews": "1,646",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODQ0NDM3MTM5MzMzMjU4OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDI3NTAyMTQ1ODAwMjo6Ojo&url=%2Fdp%2FB0CH7WLFRN%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB0CH7WLFRN%26pd_rd_w%3DxLuIg%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B09ZW52XSQ",
"image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$212.95",
"product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360° Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch",
"rating": "4",
"reviews": "1,280",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjoyMDAwNTk1NTU5MTM4OTg6Ojo6&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B07XHGLSGF",
"image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg",
"price": "$32.99",
"product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center",
"rating": "4",
"reviews": "12,179",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDAwNzU1MjExMjUwMDI6Ojo6&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B07R4R75DP",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$21.99",
"product_name": "Pacrate Gaming Headset for PS5/PS4/Xbox One/Nintendo Switch/PC/Mac, PS5 Headset with Microphone Xbox Headset with LED Lights, Noise Cancelling PS4 Headset for Kids Adults - Blue",
"rating": "4",
"reviews": "20,306",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA0NTgxNDkwNDk0MDI6Ojo6&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA0NTgxNDkwNDk0MDI6Ojo6&url=%2Fdp%2FB07R4R75DP%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB07R4R75DP%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0878W5F4X",
"image_url": "https://m.media-amazon.com/images/I/41EvG7RCdTL._AC_UF480,480_SR480,480_.jpg",
"price": "$21.99",
"product_name": "Gaming Headset with Microphone for PC PS4 PS5 Headset Noise Cancelling Gaming Headphones for Laptop Mac Switch Xbox One Headset with LED Lights Deep Bass for Kids Adults Black Blue",
"rating": "4",
"reviews": "19,883",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA1NzQ3MzAxMzA5MDI6Ojo6&url=%2Fdp%2FB0878W5F4X%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0878W5F4X%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B01H6GUCCQ",
"image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$19.99",
"product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo",
"rating": "4",
"reviews": "108,513",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjoyMDAwODg1NzA1MTAxOTg6Ojo6&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjoyMDAwODg1NzA1MTAxOTg6Ojo6&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy%26smid%3DA1BCXRJQ9212UU"
},
{
"asin": "B08FX7T8Z4",
"image_url": "https://m.media-amazon.com/images/I/41pAw9XEAiL._AC_UF480,480_SR480,480_.jpg",
"price": "$36.99",
"product_name": "EKSA E900 Headset with Microphone for PC, PS4,PS5, Xbox - Detachable Noise Canceling Mic, 3D Surround Sound, Wired Headphone for Gaming, Computer, Laptop, 3.5MM Jack",
"rating": "4",
"reviews": "3,484",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA0MDgwMTU5NzYxMDI6Ojo6&url=%2Fdp%2FB08FX7T8Z4%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB08FX7T8Z4%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B07PRVS98X",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$49.99",
"product_name": "EKSA E900 Pro USB Gaming Headset for PC - Computer Headset with Detachable Noise Cancelling Mic, 7.1 Surround Sound, 50MM Driver - Headphones with Microphone for PS4/PS5, Xbox One, Laptop, Office",
"rating": "4",
"reviews": "5,119",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA2NjIzNjk3NDU3MDI6Ojo6&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4ODc2MDIzMzA0MjMwOTU1OjE3Mzk5MDYzMDU6c3BfZGV0YWlsMjozMDA2NjIzNjk3NDU3MDI6Ojo6&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DUmsWK%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DJXR6Q40J155ZAEB6B7QY%26pd_rd_wg%3DxCMLH%26pd_rd_r%3Da987cea1-daf4-4a71-a727-6c3324d8b8ba%26s%3Delectronics%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
}
],
"url": "https://www.amazon.com/ZIUMIER-Microphone-Surround-Over-Ear-Headphones/dp/B07ZF8T63K/ref=sr_1_11?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-11&th=1",
"variation_asin": [
{
"asin": "B0CRRSHTH2",
"color_name": "Purple"
},
{
"asin": "B08CZHXRBM",
"color_name": "Camouflage"
},
{
"asin": "B08YNCZDSQ",
"color_name": "White"
},
{
"asin": "B07ZF8T63K",
"color_name": "Black"
},
{
"asin": "B0CKW6753W",
"color_name": "Pink"
},
{
"asin": "B088CZ2Z1B",
"color_name": "Green"
}
]
},
{
"asin": "B0BSJYM8FF",
"attributes": "color: Black, style: Kraken V3 X",
"availability_status": "In Stock",
"available_quantity": null,
"brand": "Razer",
"category": [
{
"level": 1,
"name": "Video Games",
"url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"
},
{
"level": 2,
"name": "PC",
"url": "/PC-Games/b/ref=dp_bc_aui_C_2?ie=UTF8&node=229575"
},
{
"level": 3,
"name": "Accessories",
"url": "/PC-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=318813011"
},
{
"level": 4,
"name": "Headsets",
"url": "/PC-Game-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=402053011"
}
],
"currency": "USD",
"frequently_bought_together": [
{
"link": "https://www.amazon.com/Razer-DeathAdder-Essential-Gaming-Mouse/dp/B094PS5RZQ/ref=pd_bxgy_d_sccl_1/136-5303947-2873247?pd_rd_w=g41WO&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=8KT0SM3BRFVCJ5RGEAAM&pd_rd_wg=bWzoq&pd_rd_r=aeb6806a-1441-45f8-a210-46d399390451&pd_rd_i=B094PS5RZQ&psc=1",
"price": "$24.82",
"title": "Razer DeathAdder Essential Gaming Mouse: 6400 DPI Optical Sensor - 5 Programmable Buttons - Mechanical Switches - Rubber Side Grips - Classic Black"
},
{
"link": "https://www.amazon.com/Razer-Ornata-Gaming-Keyboard-Low-Profile/dp/B09X6GJ691/ref=pd_bxgy_d_sccl_2/136-5303947-2873247?pd_rd_w=g41WO&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=8KT0SM3BRFVCJ5RGEAAM&pd_rd_wg=bWzoq&pd_rd_r=aeb6806a-1441-45f8-a210-46d399390451&pd_rd_i=B09X6GJ691&psc=1",
"price": "$34.98",
"title": "Razer Ornata V3 X Gaming Keyboard: Low Profile Keys - Silent Membrane Switches - Spill Resistant - Chroma RGB Lighting - Ergonomic Wrist Rest - Snap Tap"
}
],
"full_description": "Win the long game with the Razer Kraken V3 X—the ultra-light USB gaming headset made for gaming marathons. With an upgraded mic and drivers for greater sound, improved ear cushions for greater comfort, and Razer Chroma RGB for greater flair, your gaming is set to go the distance.",
"highlighted_specifications": {
"Brand": "Razer",
"Color": "Black",
"Ear Placement": "Over Ear",
"Form Factor": "Over Ear",
"Headphones Jack": "USB"
},
"image_urls": [
"https://m.media-amazon.com/images/I/71NxwEjlU1L._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71Ns3dpNLDL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/610T6qHXK7L._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/61Z8s1ehBHL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/71RnM71BwPL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/712yIMTu+nL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/81tv96YBrUL._AC_SL1500_.jpg"
],
"model": "RZ04-03750300-R3U1",
"name": "Razer Kraken V3 X Wired USB Gaming Headset: Lightweight Build - Triforce 40mm Drivers - HyperClear Cardioid Mic - 7.1 Surround Sound - Chroma RGB Lighting - Black",
"product_category": "Video Games > PC > Accessories > Headsets",
"product_information": {
"ASIN": "B0BSJYM8FF",
"Age Range (Description)": "Adult",
"Amazon Best Sellers Rank": "#210 in Video Games , #28 in PC Game Headsets",
"Audio Driver Size": "40 Millimeters",
"Audio Driver Type": "Dynamic Driver",
"Cable Feature": "Retractable",
"Compatible Devices": "Laptops, Desktops",
"Connectivity Technology": "Wired",
"Control Method": "Touch",
"Control Type": "Media Control",
"Controller Type": "Wired",
"Country of Origin": "China",
"Date First Available": "January 31, 2023",
"Earpiece Shape": "Over Ear",
"Frequency Range": "20 Hz - 20,000 Hz",
"Hardware Platform": "PC",
"Included Components": "Headset",
"Is Autographed": "No",
"Item Dimensions LxWxH": "8.47 x 6.78 x 3.55 inches",
"Item Weight": "9.9 ounces",
"Item model number": "RZ04-03750300-R3U1",
"Language": "English",
"Manufacturer": "Razer",
"Material": "Plastic",
"Model Name": "Kraken V3 X",
"Number of Items": "1",
"Operating System": "Windows",
"Package Type": "Standard Packaging",
"Power Source": "Corded Electric",
"Product Dimensions": "8.47 x 6.78 x 3.55 inches",
"Recommended Uses For Product": "Gaming",
"Series Number": "375",
"Specific Uses For Product": "Gaming",
"Style": "Kraken V3 X",
"Theme": "Video Game",
"UPC": "840272903742",
"Unit Count": "1 Count",
"Wireless Communication Technology": "wired"
},
"product_reviews": [
{
"author_name": "Clifton Gadbois",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AH4Y5A7NTDRY3B3UGG3CFLUYLN5A/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I recently had to replace my aging gaming headphones MPOW EG3's which at the time I bought them worked really well for my needs. I thought that I would get an \"upgrade\" so I tried a pair of wireless headphones which sounded horrible and had no eq software. I tried another wireless headphone and then another. Both times the native sound to the headphones had way too much bass and mids were dull and washy. The software that came with both of them simply did not work; the $140 pair had a reddit post that which gave workarounds for software glitches which they haven't bothered to fix for at least 3 years. Finally I decided to return to wired and I AM SO GLAD that I chose these headphones. Sounded great out of the box, but still a little too much bass. BUT THE EQ SOFTWARE ACTUALLY WORKS! I am a bit of an audiophile as I edit videos for a living, so being able to adjust audio is something I expect. I tried these with a game that know is hard for headphones to get correct, as it has a lot of mixed bass and mids with environmental sounds and music. These headphones with just a few little tweaks SOUND GREAT! They aren't meant for mixing or mastering music--but they ARE GREAT AS GAMING HEADPHONES!",
"review_title": "Best gaming headphones I have owned.",
"review_url": "https://www.amazon.com/gp/customer-reviews/RP4XQBJMR0BSU/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0BSJYM8FF",
"reviewed_date": "October 24, 2024",
"reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"
},
{
"author_name": "AmazonUser",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AF7NB2GOGGZTLSX3SWJ2OG454GLQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Backstory, I was looking for a new gaming headset, and I went with the very highly reviewed hyperx cloud alpha S, and hated it. I decided to try this one out because I’ve always enjoyed razer products, even if there are a few bad reviews. This headset blows the HyperX out of the water. Better sound, way better comfort, clearer mic, and the hyper sense haptic thing is game changing. Pros: -excellent sound quality -Very comfortable. Ear cups don’t press on jaw like the HyperX, padding is thicker and more resilient feeling. -Noise cancelling is just right. Little things don’t break immersion, but if someone falls down the stairs or the house catches fire, you’ll hear it. -mic is very clear. The synapse tests and peer reviews tell me this is the clearest mic I’ve used, plus it has separate adjustable thresholds for volume, background noise filtering, and voice clarification -Hyper Sense Haptics…. I think this was mostly for People playing FPS games, makes gunfire and such “feel” more real, but as someone who always has Spotify up while gaming, I Love the simulated base this adds in on low/medium settings. You could never get base like that from speakers that strap to your head, but the haptics can emulate having a nice sub nearby. Very nice touch. -RGB is a tasteful accent, not garish. I also like that I can set which colors I want in my spectrum for various patterns. Setting this to just the shades of blue and green is very nice, and matches the Corsair RGB on my desk/tower Cons: -No mute light on mic. This is a nice feature most brands have and I’ve gotten used to. Nice visible indicator that I have my mic muted to prevent embarrassing over sharing. -Thx surround feature sounds bad. I’m sure it’s great for FPS players that are willing to sacrifice sound quality to have better directional sense, but I’m not a FPS player so it’s not worth the drop in quality. This one isn’t really a detriment, it’s just a feature I don’t use. Sound quality with THX left off is phenomenal. Overall I’m super excited about this one. This is the best headset I’ve had in my 15+ years of gaming headset usage. Highly recommended.",
"review_title": "Fantastic.",
"review_url": "https://www.amazon.com/gp/customer-reviews/RUOAJ10O8OBT9/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0BSJYM8FF",
"reviewed_date": "September 21, 2022",
"reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"
},
{
"author_name": "Thomas",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AG3LM5MV7AZZ23ESSMOKWO47T7SQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "So, right off the bat I'll admit that Razer's programs like Synapse are a bit frustrating, but fortunately they're not necessary for the headset to work. That being said; the Hypersense headphones are extremely comfortable with an easy to adjust design that doesn't pull hair or pinch skin. The ear muffs are soft and feel durable. The head band also sits firmly on your head without digging in. The mic quality is much better than older models where there was a lot less background noise picked up and better clarity. The ability to remove the mic is also a handy feature. Sound is crystal clear and sharp. Noise suppression isn't perfect, but a solid 9/10. I was only able to hear the loudest of noises if I had any sound going through the headset. And the RGB looks great and is very responsive as long as you have the appropriate apps to run it correctly.",
"review_title": "An amazing headset",
"review_url": "https://www.amazon.com/gp/customer-reviews/R3NCV99ISSZCN4/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0BSJYM8FF",
"reviewed_date": "March 05, 2024",
"reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"
},
{
"author_name": "RAFAEL S",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Valeu cada minuto de espera. Headset confortável, com ótimo áudio e captação. Ao plugar o USB no PC, ele próprio instala todos os apps necessários, sendo super intuitivo. Recomendo demais para quem quer conforto e funcionalidade.",
"review_title": "Holy cow!",
"review_url": null,
"reviewed_date": "December 19, 2024",
"reviewed_product_variant": "Color: Black | Style: Kraken V3 X"
},
{
"author_name": "ERIKA CINTORA",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Los utilizo para home office, aíslan perfectamente el sonido y el micrófono cancela ruido a la perfección. Sin duda lo mejor para gaming y trabajar.",
"review_title": "Fantásticos, estéticos y sin falla",
"review_url": null,
"reviewed_date": "May 11, 2024",
"reviewed_product_variant": "Color: Black | Style: Kraken V3"
},
{
"author_name": "Josué Abraham",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "1.0",
"review_text": "Los audifonos tienen un audio decente, pero generan MUCHA estática y eso se ve reflejado en los sonidos “chirriantes” que muy a menudo se escuchan, es la primera vez que unos audífonos me generan un sonido tan desagradable, otro aspecto a tomar en cuenta es que su micrófono es HORRIBLE pues se escucha muy bajo y con calidad de audio pobre, la verdad no vale la pena tener estos audífonos solo por la tecnología háptica, si estas buscando audifonos te recomiendo los EPOS H3, son de mejor calidad y rondan por el mismo precio",
"review_title": "Mucha sonido de estática",
"review_url": null,
"reviewed_date": "March 25, 2023",
"reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"
},
{
"author_name": "Dave D",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "At first I was skeptical, they were a bit tight and there was a screeching noise that would happen occasionally. Over time they've loosened up and a software update got rid of the noise. I think they're awesome. You could save money and go without the hypersense, but the build quality and materials used is nice, everyone has been complimenting my microphone sound, and I enjoy the sound I get, especially spatial audio while gaming. I definitely recommend as a gaming headset, not necessarily for music listening. If you do listen to music, you'll enjoy the bass in bass heavy songs. Update the firmware as soon as you get them**",
"review_title": "Very nice gaming headphones",
"review_url": null,
"reviewed_date": "March 05, 2023",
"reviewed_product_variant": "Color: Black | Style: Kraken V3 HyperSense"
},
{
"author_name": "victor craveiro",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "really nice product",
"review_title": "the headphone in the world",
"review_url": null,
"reviewed_date": "October 22, 2024",
"reviewed_product_variant": "Color: Black | Style: Kraken V3 X"
}
],
"product_variations": {
"color_name": [
"Black",
"Fortnite Edition"
],
"style_name": [
"Kraken V3 X",
"Kraken V3",
"Kraken V3 HyperSense"
]
},
"rating": "4.3",
"rating_histogram": {
"five_star": "69%",
"four_star": "12%",
"one_star": "8%",
"three_star": "6%",
"two_star": "4%"
},
"regular_price": "69.99",
"review_count": "2,071",
"sale_price": "39.98",
"seller": "Amazon.com",
"seller_url": null,
"shipping_charge": null,
"small_description": "285G LIGHTWEIGHT BUILD — Experience superior audio and game for hours without being weighed down by the headset - TRIFORCE 40MM DRIVERS — Cutting-edge proprietary design divides the driver into 3 parts for the individual tuning of highs, mids, and lows —producing brighter, clearer audio with richer highs and more powerful lows - HYPERCLEAR CARDIOID MIC — An improved pickup pattern ensures more voice and less noise with the sweet spot easily placed at the mouth because of the mic’s bendable design - HYBRID FABRIC AND MEMORY FOAM EAR CUSHIONS — Wrapped in a combination of breathable fabric and plush leatherette to provide a snug fit to ensure constant comfort for prolonged gaming - 7.1 SURROUND SOUND — Provides accurate positional audio that lets you pinpoint intuitively where every sound is coming from. *Only available on Windows 10 64-bit - POWERED BY RAZER CHROMA RGB — Customizable earcup lighting and greater game immersion, with access to 16.8 million colors and a suite of lighting effects, apply preferred settings and watch it work seamlessly - #1 SELLING PC GAMING PERIPHERALS BRAND IN THE U.S. — Source — Circana, Retail Tracking Service, U.S., Dollar Sales, Gaming Designed Mice, Keyboards, and PC Headsets, Jan. 2019- Dec. 2023 combined",
"sponsored_products": [
{
"asin": "B09ZW52XSQ",
"image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$212.95",
"product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360° Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch",
"rating": "4",
"reviews": "1,280",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B084CZX3T1",
"image_url": "https://m.media-amazon.com/images/I/31n7Q5+I6UL._AC_UF480,480_SR480,480_.jpg",
"price": "$39.95",
"product_name": "JBL Quantum 200 - Wired over-ear gaming headset with Voice focus directional flip-up mic and memory foam ear cushions (Black)",
"rating": "4",
"reviews": "2,358",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDAzMTk1MjQzMjU4MTo6Ojo&url=%2Fdp%2FB084CZX3T1%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB084CZX3T1%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B01H6GUCCQ",
"image_url": "https://m.media-amazon.com/images/I/51q0meZK6WL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$19.99",
"product_name": "BENGOO G9000 Stereo Gaming Headset for PS4 PC Xbox One PS5 Controller, Noise Cancelling Over Ear Headphones with Mic, LED Light, Bass Surround, Soft Memory Earmuffs for Nintendo",
"rating": "4",
"reviews": "108,513",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UUhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjIwMDE1MjY0NDg5OTg5ODo6Ojo&url=%2Fdp%2FB01H6GUCCQ%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB01H6GUCCQ%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM%26smid%3DA1BCXRJQ9212UU"
},
{
"asin": "B07QNZC9V5",
"image_url": "https://m.media-amazon.com/images/I/419PSmh-1yL._AC_UF480,480_SR480,480_.jpg",
"price": "$89.95",
"product_name": "Razer Kraken Gaming Headset: Lightweight Aluminum Frame - Retractable Noise Isolating Microphone - for PC, PS4, PS5, Switch, Xbox One, Xbox Series X & S, Mobile - 3.5 mm Headphone Jack - Black/Blue",
"rating": "4",
"reviews": "48,125",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU2NjI1NDc2MTEwMjo6Ojo&url=%2Fdp%2FB07QNZC9V5%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB07QNZC9V5%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0C4ND25FT",
"image_url": "https://m.media-amazon.com/images/I/41TSn76LbZL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$37.99",
"product_name": "FIFINE PC Gaming Headset, USB Headset with 7.1 Surround Sound, Detachable Microphone, Control Box, 3.5mm Headphones Jack, Over-Ear Wired Headset for PS5/Xbox/Switch, Black-AmpliGame H9",
"rating": "4",
"reviews": "1,332",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDA1NTQ5NDY1MzUwMjo6Ojo&url=%2Fdp%2FB0C4ND25FT%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0C4ND25FT%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B07XHGLSGF",
"image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg",
"price": "$32.99",
"product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center",
"rating": "4",
"reviews": "12,179",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDU5NzUwMjE2MzkwMjo6Ojo&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B08TBF4S42",
"image_url": "https://m.media-amazon.com/images/I/41YfyXuYK3L._AC_UF480,480_SR480,480_.jpg",
"price": "$38.99",
"product_name": "NUBWO G06 Dual Wireless Gaming Headset with Microphone for PS5, PS4, PC - 23ms Low Latency Audio - 100-Hour of Playtime - 50mm Drivers (Black-Orange)",
"rating": "4",
"reviews": "11,500",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDAzMjM1NzgxNDgwMjo6Ojo&url=%2Fdp%2FB08TBF4S42%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB08TBF4S42%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWMhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NjAxMDExMTk1NzI5OTI3OjE3Mzk5MDYzMDU6c3BfZGV0YWlsX3RoZW1hdGljOjMwMDAzMjM1NzgxNDgwMjo6Ojo&url=%2Fdp%2FB08TBF4S42%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB08TBF4S42%26pd_rd_w%3Dt8wKG%26content-id%3Damzn1.sym.386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_p%3D386c274b-4bfe-4421-9052-a1a56db557ab%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWxfdGhlbWF0aWM"
},
{
"asin": "B0DB569DF6",
"image_url": "https://m.media-amazon.com/images/I/41MclnC9X4L._AC_UF480,480_SR480,480_.jpg",
"price": "$32.99",
"product_name": "UHURU Dual Wireless Gaming Headset with Microphone for PS5 PS4 PC: Gaming Headphones with Stereo Sound - 32Hr Battery - Cool RGB",
"rating": "4",
"reviews": "39",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDY2OTI4MzQ1MDgwMjo6Ojo&url=%2Fdp%2FB0DB569DF6%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB0DB569DF6%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B081415GCS",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$119.99",
"product_name": "Logitech G733 Lightspeed Wireless Gaming Headset with Suspension Headband, Lightsync RGB, Blue VO!CE mic technology and PRO-G audio drivers - Black",
"rating": "4",
"reviews": "17,266",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDAwMDUyNjA0NjMwMjo6Ojo&url=%2Fdp%2FB081415GCS%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB081415GCS%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDAwMDUyNjA0NjMwMjo6Ojo&url=%2Fdp%2FB081415GCS%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB081415GCS%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B096VRK6J5",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$33.99",
"product_name": "BINNUNE Wireless Gaming Headset with Microphone for PC PS4 PS5, 2.4G Wireless Bluetooth USB Gamer Headphones with Mic for Laptop Computer",
"rating": "4",
"reviews": "11,435",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDMxMDA0NTQ3MTUwMjo6Ojo&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwyhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDMxMDA0NTQ3MTUwMjo6Ojo&url=%2Fdp%2FB096VRK6J5%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB096VRK6J5%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0D4QVXY78",
"image_url": "https://m.media-amazon.com/images/I/31IcWSpdOAL._AC_UF480,480_SR480,480_.jpg",
"price": "$79.99",
"product_name": "OXS Storm G2 Wireless Gaming Headsets, 7.1 Virtual Surround Sound, 3 EQ Modes, 2.4G Low Latency, 50mm Driver, 40H Playtime, RGB Light, Bluetooth 5.3, Compatible with PC, Console, Mobile, Black",
"rating": "4",
"reviews": "74",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDI4OTgyODE3NzIwMjo6Ojo&url=%2Fdp%2FB0D4QVXY78%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0D4QVXY78%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B09ZW52XSQ",
"image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$212.95",
"product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360° Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch",
"rating": "4",
"reviews": "1,280",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B07PRVS98X",
"image_url": "https://m.media-amazon.com/images/I/41hWVo9yTRL._AC_UF480,480_SR480,480_.jpg",
"price": "$49.99",
"product_name": "EKSA E900 Pro USB Gaming Headset for PC - Computer Headset with Detachable Noise Cancelling Mic, 7.1 Surround Sound, 50MM Driver - Headphones with Microphone for PS4/PS5, Xbox One, Laptop, Office",
"rating": "4",
"reviews": "5,119",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDA4MDI0MzYzOTgwMjo6Ojo&url=%2Fdp%2FB07PRVS98X%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB07PRVS98X%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B07XHGLSGF",
"image_url": "https://m.media-amazon.com/images/I/41Y-4PruWZL._AC_UF480,480_SR480,480_.jpg",
"price": "$32.99",
"product_name": "EKSA E1000 USB Gaming Headset for PC, Computer Headphones with Microphone/Mic Noise Cancelling, 7.1 Surround Sound, RGB Light - Wired Headphones for PS4, PS5 Console, Laptop, Call Center",
"rating": "4",
"reviews": "12,179",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4NDg0NTcxNjc4ODg0MzA6MTczOTkwNjMwNTpzcF9kZXRhaWwyOjMwMDU5NzUwMjE2MzkwMjo6Ojo&url=%2Fdp%2FB07XHGLSGF%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB07XHGLSGF%26pd_rd_w%3DvJQZ3%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3D8KT0SM3BRFVCJ5RGEAAM%26pd_rd_wg%3DbWzoq%26pd_rd_r%3Daeb6806a-1441-45f8-a210-46d399390451%26s%3Dpc%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
}
],
"url": "https://www.amazon.com/Razer-Kraken-Wired-Gaming-Headset/dp/B0BSJYM8FF/ref=sr_1_13?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-13&th=1",
"variation_asin": [
{
"asin": "B09HJYCX5X",
"color_name": "Black"
},
{
"asin": "B0D54V8N2K",
"color_name": "Fortnite Edition"
},
{
"asin": "B09HJC1X9P",
"color_name": "Black"
},
{
"asin": "B0BSJYM8FF",
"color_name": "Black"
},
{
"asin": "B09HJYCX5X",
"style_name": "Kraken V3"
},
{
"asin": "B0D54V8N2K",
"style_name": "Kraken V3 X"
},
{
"asin": "B09HJC1X9P",
"style_name": "Kraken V3 HyperSense"
},
{
"asin": "B0BSJYM8FF",
"style_name": "Kraken V3 X"
}
]
},
{
"asin": "B0DB96KTGL",
"attributes": "edition: Stealth 700 XB, color: Cobalt",
"availability_status": "In Stock",
"available_quantity": null,
"brand": "Turtle Beach",
"category": [
{
"level": 1,
"name": "Video Games",
"url": "/computer-video-games-hardware-accessories/b/ref=dp_bc_aui_C_1?ie=UTF8&node=468642"
},
{
"level": 2,
"name": "Xbox One",
"url": "/Xbox-One-Games-Consoles-Accessories-Hardware/b/ref=dp_bc_aui_C_2?ie=UTF8&node=6469269011"
},
{
"level": 3,
"name": "Accessories",
"url": "/Xbox-One-Hardware-Accessories/b/ref=dp_bc_aui_C_3?ie=UTF8&node=6469270011"
},
{
"level": 4,
"name": "Headsets",
"url": "/Xbox-One-Headsets/b/ref=dp_bc_aui_C_4?ie=UTF8&node=6469291011"
}
],
"currency": "USD",
"frequently_bought_together": [
{
"link": "https://www.amazon.com/High-Performance-Wireless-Controller-Licensed-Xbox-X/dp/B0CJVQFZ1S/ref=pd_bxgy_d_sccl_1/139-3471011-9068846?pd_rd_w=5bw0d&content-id=amzn1.sym.de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_p=de9a1315-b9df-4c24-863c-7afcb2e4cc0a&pf_rd_r=V9NQ5JPN2WB7W3HWZYDM&pd_rd_wg=MOkSO&pd_rd_r=6803a5fa-0bba-4a1a-996a-8c96a480b9ad&pd_rd_i=B0CJVQFZ1S&psc=1",
"price": "$169.99",
"title": "Turtle Beach Stealth Ultra High-Performance Wireless Gaming Controller Licensed for Xbox Series X|S, Xbox One, Windows PC & Android – LED Dashboard, Charge Dock, RGB Lighting, 30-Hr Battery, Bluetooth, Black"
}
],
"full_description": "The Turtle Beach Stealth 700 Gen 3 wireless multiplatform gaming headset officially licensed for Xbox Series X|S & Xbox One, and works great with PS5 & PS4, Windows PCs, Steam Deck and mobile is redesigned and feature-packed for a 3rd generation of premium gaming prowess. All-new, and exclusive for the Stealth 700 Gen 3, the CrossPlay Wireless Audio System includes two USB wireless transmitters, and using the CrossPlay button on the headset, you can easily switch between your favorite console and PC without having to move transmitters or connect cables. Plus, simultaneous Bluetooth 5.2 lets you connect directly to mobile devices while playing on console or PC so you can chat with friends on Discord or listen to your favorite music from your phone while still hearing game audio on your console or PC. Huge, 60mm Eclipse Dual Drivers are the largest speakers in their class – and the difference is clear with unparalleled acoustic precision and deep bass for immersive spatial audio on console and PC. The dual drivers are designed with a distinct woofer and tweeter to separate low and high frequencies for vastly improved audio detail over conventional drivers. A massive battery life of up to 80-hours is the best in its class for more gametime and less downtime, plus a quick 15-minute charge gets you back in action with 3 hours of battery life. Completely redesigned for the 3rd generation of the Stealth 700, the all-new uni-directional flip-to-mute microphone features A.I. noise reduction to ensure ultra-clear mic quality with the quietest background possible. Using the Swarm II companion app for desktop & mobile devices, you can adjust noise gate, sensitivity, monitoring levels, and choose from four different mic presets, or even make your own with a custom 10-band microphone EQ. And to dial in the 60mm Eclipse drivers to your liking you can use the Swarm II app to cycle through four audio EQ presets, create up to five custom presets with a 10-band audio EQ, adjust game & chat volume mix, chat boost, plus activate, or adjust Turtle Beach exclusive Advanced Superhuman Hearing sound setting. And for added customization, you can remap the wheel & mode button on the headset to different functions to better suit your gameplay. A redesigned headband & ear cushions let you dominate for hours with unmatched comfort. Plush memory foam ear cushions wrapped in a hybrid of leatherette & athletic-weave fabric keep your ears cool and lend to enhanced noise isolation. Plus, the cushions feature ProSpecs glasses relief technology, so whether you wear gaming or prescription glasses, you’ll enjoy the same great comfort. For long-lasting durability and adjustability, the Stealth 700 Gen 3 features a steel-reinforced headband, paired with an adjustable lay-flat design. CrossPlay Multi-platform Wireless Audio System Dual USB wireless transmitters and a single button on the headset allow you to quickly switch between your favorite console or PC without having to move transmitters or connect cables. Simultaneous Wireless + Bluetooth Connect to your gaming console or PC, as well as your smartphone or tablet at the same time with simultaneous 2.4GHz Wireless & Bluetooth 5.2. With dual wireless capabilities, you can chat with friends on Discord, or listen to your favorite music from your phone and still hear game audio from your console or PC. Plus, with independent volume controls, you can easily adjust and mix the levels of wireless and Bluetooth audio sources. Stunning Audio Clarity The largest in their class, our patented 60mm Eclipse dual drivers deliver immersive soundscapes with unparalleled precision and deep bass. The dual drivers are designed with a distinct woofer and tweeter to separate low and high frequencies for vastly improved audio detail over conventional drivers. Exceptional Microphone Performance Completely redesigned for the third generation of Stealth 700, the all-new uni-directional, flip-to-mute microphone features A.I. noise reduction to ensure the quietest background possible. Plus, using the Swarm II app for desktop & mobile, you can further refine microphone specs to dial-in your exact preferences. Unstoppable, 80-Hour Battery Life Power through gaming sessions with a massive battery life of up to 80 hours. Plus, with a quick-charge, you can get back in the action right away with 3 hours of battery life in just a 15-minute charge. Superb Comfort, Unmatched Durability Designed for a comfortable fit that’s built to last through every battle, the Stealth 700 Gen 3 features hybrid leatherette & athletic-weave fabric wrapped memory foam cushions, and durable steel-reinforced construction. Plus, the cushions feature ProSpecs glasses relief technology so every gamer can enjoy the same great comfort. Anywhere Audio Customization Connect to the Swarm II companion app for PC, iOS, or Android to access extensive audio enhancements* including a dynamic 10-band EQ with up to five custom presets you can design based on the type of games or music you listen to. You can also program the mappable wheel and mode button, adjust mic sensitivity, noise gate, monitoring levels and more. Additionally, Swarm II supports over the air firmware updates to ensure your Stealth 700 Gen 3 is always up to date. *Select advanced audio features may not be supported in Bluetooth mode. Remappable Wheel & Mode Button Customize your headset with a remappable wheel & mode button that can be assigned to distinct functions based on your gaming style using the Turtle Beach Swarm II app. Functions for the Mode button include EQ preset selection, multimedia controls on PC, noise gate and chat boost. And the secondary wheel can be reassigned to control Game/Chat Mix, Variable Mic Monitoring, Bass & Treble Boost levels and Noise Gate. Advanced Superhuman Hearing Advanced Superhuman Hearing brings the same great battlefield advantage of Superhuman Hearing, but now with additional adjustability. In the Swarm II app, toggle between three different preset levels and adjust the intensity of Superhuman Hearing, to dial-in the perfect sound for a wide range of games. Easy Access to Audio Presets & Variable Mic Monitoring Enhance your gameplay experience at the touch of a button with four Turtle Beach audio presets including Bass Boost, Signature Sound, Treble Boost, and Vocal Boost. Avoid shouting thanks to variable mic monitoring (or sidetone) which allows you to hear and adjust your voice through the headset while you chat.",
"highlighted_specifications": {
"Brand": "Turtle Beach",
"Color": "Cobalt",
"Ear Placement": "Over Ear",
"Form Factor": "Over Ear",
"Impedance": "33 Ohm"
},
"image_urls": [
"https://m.media-amazon.com/images/I/51I7-qv8A9L._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/61ay9UC1DJL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51YmHZbxedL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/61Lh4YWsiUL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51m0ulsaR+L._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/61tcNVjcLFL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/61JEY3nCh5L._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/61LkHSq2n4L._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51Z+x7xxqQL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51ps9csBFeL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51cs4O3NgjL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/511+gL8wBJL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51kEpHDEYEL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/71T81HAkPpL._AC_SL1500_.jpg",
"https://m.media-amazon.com/images/I/51kwm601mOL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/41CcoTIKdhL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/41XZ5xeNMPL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51gYjmTnzuL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51bCmY84IBL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/31Tt-aF2fYL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/41qo5tW8NUL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51y02pbenGL._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/51Jd6XVN76L._AC_SL1000_.jpg",
"https://m.media-amazon.com/images/I/41xKzUMgo+L._AC_SL1000_.jpg"
],
"model": "TBS-2101-25",
"name": "Turtle Beach Stealth 700 Gen 3 Wireless Multiplatform Amplified Gaming Headset for Xbox Series X|S, Xbox One, PC, PS5, Mobile – 60mm Drivers, AI Noise-Cancelling Mic, Bluetooth, 80-Hr Battery – Cobalt",
"product_category": "Video Games > Xbox One > Accessories > Headsets",
"product_information": {
"ASIN": "B0DB96KTGL",
"Age Range (Description)": "Teen, Adult",
"Amazon Best Sellers Rank": "#188 in Video Games , #6 in Xbox One Headsets , #11 in Xbox Series X & S Accessories",
"Audio Driver Size": "60 Millimeters",
"Audio Driver Type": "Dynamic Driver",
"Batteries": "1 Lithium Polymer batteries required. (included)",
"Battery Life": "80 Hours",
"Bluetooth Range": "60 Feet",
"Bluetooth Version": "5.2",
"Cable Feature": "Detachable",
"Charging Time": "4 Hours",
"Compatible Devices": "Cellphones, Gaming Consoles, Tablets, Laptops, Desktops",
"Connectivity Technology": "Wireless",
"Control Method": "App",
"Control Type": "Touch Control",
"Controller Type": "Button, Touch",
"Country of Origin": "Vietnam",
"Date First Available": "August 19, 2024",
"Earpiece Shape": "Oval",
"Frequency Range": "2 Hz - 20,000 Hz",
"Frequency Response": "20 KHz",
"Included Components": "Wireless Gaming Headset, 0.7m / 2.3ft Charging Cable (USB-A to USB-C), Two CrossPlay USB Wireless Transmitters, Quick Start Guide",
"Is Autographed": "No",
"Item Weight": "14.4 ounces",
"Item model number": "TBS-2101-25",
"Manufacturer": "Turtle Beach",
"Material": "Aluminum, Plastic, Metal, Thermoplastic Elastomer (TPE), Acrylonitrile Butadiene Styrene (ABS)",
"Model Name": "700XG3C",
"Noise Control": "Passive Noise Cancellation",
"Number of Items": "1",
"Number of Power Levels": "1",
"Number of USB 2 Ports": "1",
"Package Type": "Standard Packaging",
"Product Dimensions": "7.87 x 6.81 x 3.7 inches",
"Recommended Uses For Product": "Gaming",
"Sensitivity": "94 dB",
"Series Number": "3",
"Specific Uses For Product": "Gaming",
"Theme": "Video Game",
"UPC": "731855021062",
"Water Resistance Level": "Not Water Resistant",
"Wireless Communication Technology": "Bluetooth, Wi-Fi"
},
"product_reviews": [
{
"author_name": "Dylan De Koning",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEQQOXYFACJWX6VNJWZQCLYRBJLA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I was surprised. I used a Turtle Beach headset years ago and was not happy with my experience. You hear that Turtle Beaches are kinda looked down upon, like Alienware computers. I was happily surprised with the quality of the headset. I was using a Steel Series Arctics 7x for multiplatform and Bluetooth compatibilities. It was a small headset that was very uncomfortable to wear, especially with the headband pressing against my head all the time. The audio was not impressive at all either. With the stealth 700, I couldn't help but open the box with my jaw agape. The cushions are so nice to wear, the drivers are bass heavy and very pleasant to listen to while playing war games like Battlefield. The metal frame makes me feel safe when handling the headset, and it was pretty easy to set up. The firmware update took awhile, but so far no problems, even with connectivity. Overall, very satisfied with the product. Some people mention my mic quality went down, but I'm just happy it's not very sensitive and picking up on every single background noise like my other one. Highly recommend",
"review_title": "Actual Premium Headset",
"review_url": "https://www.amazon.com/gp/customer-reviews/RCGQYDQ9YSUVV/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DB96KTGL",
"reviewed_date": "January 20, 2025",
"reviewed_product_variant": "Color: Black | Edition: Stealth 700 XB"
},
{
"author_name": "Amazon Customer",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AHTLPVUQSJSPVQJQ2OKIQ2DT43KQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "This headset sounds great. I had the Steelseries Arctis 7x and my friends complained about the mic dropping out randomly. So I tried these out and the sound and mic is amazing. My friends even said it sounds more like me. Pros: Sound is punchy with deep bass and high treble. I reomend using the Bass and Treble preset. Sounds the best for footsteps. Comes with two dongles so I just have to hit a button to switch from Xbox to my PC. You can also have your phone connected to answer calls or listen to music while you game. The headset has 3 volume controls, the regular volume, chat to game mixer, and the Bluetooth volume. Last is the mic. My friend has the gen 2 version and it sounds like we are talking on the phone, he says I sound the same. This has been the best mic I've had on a headset. Cons: The app is terrible. There aren't numbers on the mixer so you have to figure it out on your own. This is very difficult to figure out if you're not a soundphile person. The presets aren't the greatest. The best I found is the bass and treble preset. The super human hearing setting is awful. It has legacy, gunfire, and footsteps. On the Xbox it just kills the sound, the footsteps and gunfire are punchier on the other presets with this feature turned off. The setting basically sounds like really bad earbuds. The other problem is firmware updates. This requires you to have the dongles plugged into both devices with them turned on. So if you don't have a PC, forget about updating the firmware. The last issue is where the volume controls are. When I wear a hoodie my hood will randomly change the chat mixer. Not a big problem but something to be aware of. Besides the app and firmware, this headset is great. It's the best one I have owned and sounds amazing on all fronts.",
"review_title": "Great sound and Mic.",
"review_url": "https://www.amazon.com/gp/customer-reviews/R12NSGVMBQKO7Y/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DB96KTGL",
"reviewed_date": "February 07, 2025",
"reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"
},
{
"author_name": "Lady A",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AEC5JUIE663DK3MF56YLHPRU7WEA/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I have owned 600s and 700s. The 600 were fine with less quality material but the disconnect issues for both the of them were so annoying. I read a review before getting these again and someone said that issue was fixed so i decided to take a chance. So far, so good. Good quality sound, material, and comfort for the price and zero drops unless I walk way too far to even be gaming. The only real issue was upgrading the firmware because you have to update the dongles and headset at the same time or it won't update. If you have a pc nearby your fine but I didn't. It took many attempts due to connection drops and after a full day, I finally got it to take! Since then, all good. Headset can be used for PS, Xbox, and PC, it has Bluetooth and separately dials for volume and chat/game sound. Charge last a long time too, I didn't have to recharge for a few days. So far, this is a winner! Now if they can last a few years I will be thoroughly impressed!",
"review_title": "So far so good!",
"review_url": "https://www.amazon.com/gp/customer-reviews/R302AALWQW0K5N/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DB96KTGL",
"reviewed_date": "December 18, 2024",
"reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"
},
{
"author_name": "Jocelyn",
"author_profile": "https://www.amazon.com/gp/profile/amzn1.account.AFVLUOBLN4OFDSILJ5HQQSCSDIEQ/ref=cm_cr_dp_d_gw_tr?ie=UTF8",
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "These are a really nice quality for the price. They work exactly as they should and fit comfortably. They even have a noise cancellation smart feature to where if you are chewing with the mic out, it will automatically cancel that noise so your buddies can't hear the sound. So if you like to snack while you game, that's a nice feature.",
"review_title": "Great Quality",
"review_url": "https://www.amazon.com/gp/customer-reviews/RYZAAOMHKB2LB/ref=cm_cr_dp_d_rvw_ttl?ie=UTF8&ASIN=B0DB96KTGL",
"reviewed_date": "January 14, 2025",
"reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"
},
{
"author_name": "Chad",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "I've owned Turtle Beach headsets for over a decade. This set is EASILY their best thus far! The 600 had great sound, this set is even better. It has two usb transmitters (dedicated xbox and pc) and there's a button the the set to swap between them. It's very seamless and works really well. The 600 series would lose connection as I walked around, this set does not. Conversations are very clear, both Bluetooth and in game. The major problem with TurtleBeach has always been longevity. The joints at the earcuffs have always broken away on me. This set is completely redesigned and very comfortable. I'll update in a year. So far, they're absolutely worth every cent!",
"review_title": "Best of Turtle Beach",
"review_url": null,
"reviewed_date": "January 17, 2025",
"reviewed_product_variant": "Color: Black | Edition: Stealth 700 XB"
},
{
"author_name": "Yony gilmart",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Los audífonos son muy perfectos Lo unció malo fue la paqueteria Fue todo un desastre Se atrasaron y perdieron el paquete Pero el producto funciona muy bien",
"review_title": "Audífonos",
"review_url": null,
"reviewed_date": "January 03, 2025",
"reviewed_product_variant": "Color: Black | Edition: Stealth 700 XB"
},
{
"author_name": "anthony salmon",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Used this with my xbox, and sound quality is brilliant, design is nice, mic and chat quaily is great as well, so easy to connect and can be used with multiple devices, I played my xbox one evening for 4 hours and they were super comfortable, my ears didn't sweat or start to hurt, overall this headset is excellent for the price and if your just a general gamer they are perfect, and with the super sound addition you can hear back ground noise like foot steps really clear, big help in games like call of duty.",
"review_title": "Great head set.",
"review_url": null,
"reviewed_date": "February 01, 2025",
"reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"
},
{
"author_name": "Dylan gierczynski",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Reçu à main propre niveau qualité impressionnante je recommande se produit.",
"review_title": "Recommande",
"review_url": null,
"reviewed_date": "January 18, 2025",
"reviewed_product_variant": "Color: Cobalt | Edition: Stealth 700 XB"
},
{
"author_name": "Simone Montana Lampo",
"author_profile": null,
"badge": "Verified Purchase",
"rating": "5.0",
"review_text": "Nel suo genere uniche bluetooth, xbox e pc insieme! Audio imbattibile acquisto consigliato!",
"review_title": "Cuffie perfette!",
"review_url": null,
"reviewed_date": "January 04, 2025",
"reviewed_product_variant": "Color: Black | Edition: Stealth 700 XB"
}
],
"product_variations": {
"color_name": [
"Black",
"Black/Arctic Camo",
"Cobalt",
"White"
],
"edition": [
"Stealth 500 XB",
"Stealth 600 XB",
"Stealth 700 XB"
]
},
"rating": "4.4",
"rating_histogram": {
"five_star": "74%",
"four_star": "9%",
"one_star": "8%",
"three_star": "5%",
"two_star": "4%"
},
"regular_price": "199.99",
"review_count": "701",
"sale_price": "188.37",
"seller": "Amazon.com",
"seller_url": null,
"shipping_charge": null,
"small_description": "CrossPlay Dual Transmitter Multiplatform Wireless Audio System - Simultaneous Low-latency 2.4GHz wireless + Bluetooth 5.2 - 60mm Eclipse Dual Drivers for Immersive Spatial Audio - Flip-to-Mute Mic with A.I.-Based Noise Reduction - Long-Lasting Battery Life of up to 80-Hours plus Quick-Charge - Memory Foam Cushions with Glasses-Friendly Technology - Lay-Flat, Steel-Reinforced Design - Swarm II Desktop & Mobile App with Advanced 10-Band EQ - Mappable Wheel & Mode Button for Customizable Functions - Built-in EQ modes plus Advanced Superhuman Hearing",
"sponsored_products": [
{
"asin": "B09ZW52XSQ",
"image_url": "https://m.media-amazon.com/images/I/419BM5TVzEL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$212.95",
"product_name": "SteelSeries Arctis Nova Pro for Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Hi-Res Audio - 360° Spatial - GameDAC Gen 2 - Stealth Retractable Mic - Xbox, PC, PS5/PS4, Switch",
"rating": "4",
"reviews": "1,280",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjIwMDA1OTU1NTkxMzg5ODo6Ojo&url=%2Fdp%2FB09ZW52XSQ%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB09ZW52XSQ%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"
},
{
"asin": "B0DB9Y81C1",
"image_url": "https://m.media-amazon.com/images/I/31+l4UYqQfL._AC_UF480,480_SR480,480_.jpg",
"price": "$171.23",
"product_name": "Turtle Beach Stealth 700 Gen 3 Wireless Multiplatform Amplified Gaming Headset for PC, PS5, PS4, Mobile – 24-bit Audio, 60mm Drivers, High-Bandwidth Microphone, Bluetooth, 80-Hr Battery – Black",
"rating": "4",
"reviews": "91",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjMwMDM4MzIwOTk4NDIwMjo6Ojo&url=%2Fdp%2FB0DB9Y81C1%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0DB9Y81C1%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"
},
{
"asin": "B0B15QM5LL",
"image_url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAYCAYAAADDLGwtAAAJT3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjarZhrkuM4DoT/8xR7BIIvkMfhM2JusMffD5Sruh5dMz0RW26bMi1RIDKRCbXb//3ruP/wF0rwLmWtpZXi+UsttdA5qP75a/dTfLqfz19/jfJ53snbRYGpyBifr/q6QDrz+dcFb6fL+Dzv6uuXUF8LyfvC9y/ane14fQyS+fDMS3ot1PZzUFrVj6GO10LzdeIN5fVO72E9g313nyaULK3MjWIIO0r09zM9EUR7S+yMz2cNdmTHIRZ3p9prMRLyaXtvo/cfE/QpyeWVS/c1++9HX5If+ms+fslleVuo/P4HyV/m4/ttwscbx9eRY/rTDyzUvm3n9T5n1XP2s7ueChktL0bdZMvbMpw4SHm8lxVeyjtzrPfVeFUIOYF8+ekHrylNAqgcJ0mWdDmy7zhlEmIKOyhjCBOgbK5GDS3Mi1iyl5ygscUVK5jNsF2MTIf3WOTet937TVi//BJODcJiwiU/vtzf/fhvXu6caSkSX588wQviCsZrwjDk7JOzAETOC7d8E/z2esHvP/AHqoJgvmmubLD78SwxsvziVrw4R87LjE8JidP1WoAUce9MMNA+iS8SsxTxGoKKkMcKQJ3IQ0xhgIDkHBZBhhRjCU4DJcO9uUblnhsyQmXTaBNA5Fiigk2LHbBSyvBHU4VDPceccs4la64ut9xLLKnkUooWE7muUZNmLapatWmvsaaaa6laa221t9AiGphbadpqa6334Do36qzVOb8zM8KII408ytBRRxt9Qp+ZZp5l6qyzzb7CiguZWGXpqqutvsVtlGKnnXfZuutuux+4duJJJ59y9NTTTn9HTV5l+/X1L1CTF2rhImXn6TtqzDrVtyXE5CQbZiAWkoC4GgIQOhhmvkpKwZAzzHwLFEUOBJkNG7fEEAPCtCXkI+/Y/ULuj3Bzuf4RbuGfkHMG3f8DOQd033H7DWrLtHlexJ4qtJz6SPWdQCKq62H0eshG5Vs3f/t57Gs3LbPp6MMSYntNGuduMpzkTb1Tair7TFwwJ9ZeWc+W3HZdh+iinsO99Ui0sdYef/1scUV1dnCeM/i9bZI+9iTrLWdJWQwiG1M2V/1hzL25LeS8s1Le9fje8LY0ds1JkNGQp+9z9NUP4XDLWTfJUkwglXWjTCWsoMO7HUePu7Ybcsqb6Lb2Nez7OmmxhaRnhnD0zsVV7nb26cVG3/cotU8XuCxP8l2Jw/K6a5zEcZPsfxojduHLE2Pe+ZzutsWcQu4ntUXadirsiXHsbZ7gZ1Zpx8OlvfYZMy2NkmfSsXxuAz5QLG05eNMOy5S0ICFrFFkoX8hplAlRoV9XHWoWc7RPNpRjh7hHEwHcCEeI3U0D69lTj7P/vCfW4pZhHgmTnOAVJwfLXu+57O3aTZ3Qvpwdz5wrlFj7oEbCqfFQsjO1HdagibC9AskRSNjik/oQT2E/xw1dEnYJg0JMhYrsPVbWAlI5PWsrii3bRQ2P3Fj/mPICnrreO+c61+7oURa2lZ89dE+b8Id7PXkcnx/kenblhlgWA3gRQcg4FDCtmOqQ0U/VBUH4ypdUqIZA8v2NsXRoKL22PV1ZaOE2nla5RDMDgro6BtSsiMk6uQhV1Utuq+VNfsrxe8KCRrpV4mSTrjeStWafnDVQzVdhhfCHW0Q7Ib8UN/YNEp4/5bsIp/7aXWvbquSggxLHJCida27fpp4ONTchFjbQDDWEYme9udLdBtQYq9FbAFPzcMCapJYR8qmYIfvEtY/WtfqQNijVEVpyYr5wyirzWN2YGgOsUUlNRFpb4U0tdKL7dgjQwHxVBjN6RmcHeMHoYbYgflovnYvuuUQPYeaYgCbV00MYZJ7S3Mm/EuFvNVZaieVqfORgHkMpge8RiG2tSUbz6du4Hl6QF5rPffjHsXYMpLZHh5NF5254tJDy6OFK2r4pYumlYjJzUVYnYo4xFfROmqJ8DRvg7YaP+4mYJvH0ynjKgLDD8n5Qz76OBzhqZWmngcE5m7AwfhswUJXRdAU3rOxG7GegjHNTuPs8FChQGMs8ycDGqsZLxGtb82vMOt2PQGiSXojKGNR15jCH3xs3wgN3iKOhTmktjJmc1YNCwqOJrShKmfetoWPPOygXhRnLqQl9W7VrHQE1pmlGOYB08xsOpmR/r+ggJTe92jLJidje4qMMWuixB09d69mTL/v7lt525D5viWi15jFJ0uMRyyofvz5zLEtjNjuvM7LNYVWKGBidD40WndvCyXyjKUAUClz2p7VaCKsBJrWQY6BPwHQGvobbCEmJbEV3kIGTsbPtkNtBzVNGKPypLIIeJDxldxQFNtKR0HnRxoy0CpoNqYTGC4XxgJwxDgwHg9RBRP6jfHxtH36Sk0MXtYUkoN9hOVi019UweH9CeRy30GddeaG7AdN6JS9moxnknGXtpZPgFZOaaiXkyBbiJCQQB8P0SkYyFt6WApdSZ5hqjduaJGSeZgxhb7Oi85pN/esLKPdFDX5TdrGJkC4ag4IJ07uWhy532Eovad8cZmN5YFswj/1ggrdZCFDulGw9yhYd6QxPO4kFk4dt5Du7zBIjnRf2fMQh1getXlas4HKOSZGm0TMPhkrJh7ox6skliJVXesxdUEHasT7naC+I6EZ+aPU+YxWIFC2W2+cg4eaoJcAgj+7CpaUOfFoPqbHusP8HWYbDw4+TMgjNl4cdMVkcJw3r+iQQ2+CJdvH0O/QRtlzluzD8UFUob0YPYuyNjnztTASCuYjDK5r5xm1tYQcU2zQWlNgONNgV96G8ympxoCH7kh9kxrLewCSa58KLWjKQmr9IYecbC/eIdbc2S7CckRp+HoyGh46r1Ak7afeFlfpp9oA+eXI/DkmlhiJFjB8jB6OW+fDooxP93YZBHMVwpC7RvGErav0EtbQ0UAwETtjQho7XrzxvyUqq0wL11Kzp70xWs7XxYEGjhbFsuM6WriGVgtCcq4141sJ1NYDvQWd6Hugv+2Z+EPdgyRrsATxWtyZ2kekyCvSmVaavrm92Vb+Uz2/KCWux/3dpNFrWBixuqJr8GSbRSBQQJCgE6bHZOebFZ8R6wJOWrWzTy/3WxDfaqvsIUUTuFC4t9OMkXiatPy14xPLCQ8w1wGrsJVTITrbbVjdmARUyRugIEscrdKb/1KS/d0R0kLQx/wOKrEbcxIRjWgAAAYVpQ0NQSUNDIHByb2ZpbGUAAHicfZE9SMNQFIVPU6VFKgp2KKKQoTpZEBVx1CoUoUKoFVp1MHnpHzRpSFpcHAXXgoM/i1UHF2ddHVwFQfAHxM3NSdFFSrwvKbSI8cLjfZx3z+G9+wChUWaa1TUOaHrVTCXiYia7KgZe4UMQ/YhgWGaWMSdJSXjW1z11U93FeJZ335/Vq+YsBvhE4llmmFXiDeLpzarBeZ84zIqySnxOPGbSBYkfua64/Ma54LDAM8NmOjVPHCYWCx2sdDArmhrxFHFU1XTKFzIuq5y3OGvlGmvdk78wlNNXlrlOawgJLGIJEkQoqKGEMqqI0a6TYiFF53EP/6Djl8ilkKsERo4FVKBBdvzgf/B7tlZ+csJNCsWB7hfb/hgBArtAs27b38e23TwB/M/Ald72VxrAzCfp9bYWPQL6toGL67am7AGXO0DkyZBN2ZH8tIR8Hng/o2/KAgO3QM+aO7fWOU4fgDTNKnkDHBwCowXKXvd4d7Bzbv/2tOb3Ay9kcozy2C0nAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH5QEIEBoNoDME2AAAAKBJREFUKM9jZDAw+89ABGAiRtHC2iriFAa4OhNWmBvoz8DHy0NYYYinG2E3GispMtiZmhBWGOvrTZyvA9xcCCuMdnJgkJeSJKwwzMudcIBLCQow+Dk7EVaYGuBLXBQGubkRVuhubMCgp6FGWGGUlxdxqSfA1ZmwQlgCIKgQlgDwKkROAHgVIicAvAqREwBOhegJAKdC9ASAFUg5uv0nBgAAnCk9i8O3r7cAAAAASUVORK5CYII=",
"price": "$153.99",
"product_name": "SteelSeries Arctis Nova 7 Wireless Multi-Platform Gaming Headset — Neodymium Magnetic Drivers — 2.4GHz + Mixable Bluetooth — 38Hr USB-C Battery — ClearCast Gen2 AI Mic — PC, PS5, Switch, VR, Mobile",
"rating": "4",
"reviews": "5,892",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjIwMDExMzMyNjMyNzQ5ODo6Ojo&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwhttps://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjIwMDExMzMyNjMyNzQ5ODo6Ojo&url=%2Fdp%2FB0B15QM5LL%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0B15QM5LL%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"
},
{
"asin": "B0DB7ZW7J4",
"image_url": "https://m.media-amazon.com/images/I/41CcIOb-fOL._AC_UF480,480_SR480,480_.jpg",
"price": "$279.99",
"product_name": "Logitech G Astro A50 Omni-Platform Wireless Gaming Headset + Base Station for PS5, Xbox, PC: PLAYSYNC Audio Switcher, <16 bit/48kHz (Console), <24 bit/48 kHz (PC), 24hr Battery, 2.4GHz & BT - Black",
"rating": "4",
"reviews": "633",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjMwMDUwNjk4OTYwMDEwMjo6Ojo&url=%2Fdp%2FB0DB7ZW7J4%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0DB7ZW7J4%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"
},
{
"asin": "B09ZWKD9TF",
"image_url": "https://m.media-amazon.com/images/I/312MvjLsRXL._AC_UF480,480_SR480,480_.jpghttps://m.media-amazon.com/images/I/216-OX9rBaL.png",
"price": "$306.99",
"product_name": "SteelSeries Arctis Nova Pro Wireless Xbox Multi-System Gaming Headset - Premium Hi-Fi Drivers - Active Noise Cancellation Infinity Power System - Stealth Mic - Xbox, PC, PS5, PS4, Switch, Mobile",
"rating": "4",
"reviews": "5,928",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjIwMDA1OTIyNzIxMDE5ODo6Ojo&url=%2Fdp%2FB09ZWKD9TF%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB09ZWKD9TF%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"
},
{
"asin": "B0CDHH595L",
"image_url": "https://m.media-amazon.com/images/I/41ahQMbSOEL._AC_UF480,480_SR480,480_.jpg",
"price": "$85.99",
"product_name": "RIG 600 PRO HX Dual Wireless Universal Gaming Headset with Bluetooth for Xbox Series X|S, Xbox One, Playstation PS4, PS5, Nintendo Switch, PC, USB & Mobile",
"rating": "4",
"reviews": "97",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjMwMDA4NTgzNzUxMzYwMjo6Ojo&url=%2Fdp%2FB0CDHH595L%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB0CDHH595L%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"
},
{
"asin": "B098TV8C93",
"image_url": "https://m.media-amazon.com/images/I/31XW2VYbH7L._AC_UF480,480_SR480,480_.jpg",
"price": "$89.99",
"product_name": "HyperX CloudX Stinger Core – Wireless Gaming Headset, for Xbox Series X|S and Xbox One, Memory foam & Premium Leatherette Ear Cushions, Noise-Cancelling,Black",
"rating": "4",
"reviews": "34,211",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo4MzkwNDE2NTE0NTQ5ODk0OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsOjMwMDE4NjEyOTQxOTYwMjo6Ojo&url=%2Fdp%2FB098TV8C93%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB098TV8C93%26pd_rd_w%3DmRoTa%26content-id%3Damzn1.sym.7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_p%3D7446a9d1-25fe-4460-b135-a60336bad2c9%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWw"
},
{
"asin": "B07NH6Q4LB",
"image_url": "https://m.media-amazon.com/images/I/311pg5gMKZL._AC_UF480,480_SR480,480_.jpg",
"price": "$34.95",
"product_name": "Turtle Beach Recon 70 Gaming Headset - Nintendo Switch, Xbox Series X|S, Xbox One, PS5, PS4, PlayStation, Mobile, & PC with 3.5mm - Flip-Up Mic, 40mm Speakers, Stereo – Black",
"rating": "4",
"reviews": "84,633",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA2MjQyOTgzODUzMDI6Ojo6&url=%2Fdp%2FB07NH6Q4LB%2Fref%3Dsspa_dk_detail_0%3Fpsc%3D1%26pd_rd_i%3DB07NH6Q4LB%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0CYWD9PSM",
"image_url": "https://m.media-amazon.com/images/I/31MVF59bG3L._AC_UF480,480_SR480,480_.jpg",
"price": "$89.99",
"product_name": "Turtle Beach Stealth 600 Gen 3 Wireless Multiplatform Amplified Gaming Headset for PS5, PS4, PC, Mobile – Bluetooth, 80-Hr Battery, AI Noise-Cancelling Flip-to-Mute Mic, 50mm Speakers – Black",
"rating": "4",
"reviews": "468",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAxNzA0MzQ2ODk1MDI6Ojo6&url=%2Fdp%2FB0CYWD9PSM%2Fref%3Dsspa_dk_detail_1%3Fpsc%3D1%26pd_rd_i%3DB0CYWD9PSM%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0DKS9NYZM",
"image_url": "https://m.media-amazon.com/images/I/31eb+eD9oVL._AC_UF480,480_SR480,480_.jpg",
"price": "$245.37",
"product_name": "Turtle Beach Victrix Pro KO Leverless All Button Fight Stick, Officially Licensed for Xbox Series X|S, Xbox One, Windows 10/11 PC, Customizable eSports Tournament Ready Controller, Gray",
"rating": "3",
"reviews": "8",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA1MTkzMzcwMzA0MDI6Ojo6&url=%2Fdp%2FB0DKS9NYZM%2Fref%3Dsspa_dk_detail_2%3Fpsc%3D1%26pd_rd_i%3DB0DKS9NYZM%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0CZX7MB48",
"image_url": "https://m.media-amazon.com/images/I/31DesTdt70L._AC_UF480,480_SR480,480_.jpg",
"price": "$87.00",
"product_name": "Turtle Beach Stealth 600 Gen 3 Wireless Multiplatform Amplified Gaming Headset for PC, PS5, PS4, Mobile – Bluetooth, 80-Hr Battery, AI Noise-Cancelling Flip-to-Mute Mic, Waves 3D Audio – Black",
"rating": "4",
"reviews": "293",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAxNzA0Mjg1OTgyMDI6Ojo6&url=%2Fdp%2FB0CZX7MB48%2Fref%3Dsspa_dk_detail_3%3Fpsc%3D1%26pd_rd_i%3DB0CZX7MB48%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B0CJVQFZ1S",
"image_url": "https://m.media-amazon.com/images/I/41x-FF2SXwL._AC_UF480,480_SR480,480_.jpg",
"price": "$169.99",
"product_name": "Turtle Beach Stealth Ultra High-Performance Wireless Gaming Controller Licensed for Xbox Series X|S, Xbox One, Windows PC & Android – LED Dashboard, Charge Dock, RGB Lighting, 30-Hr Battery, Bluetooth, Black",
"rating": "3",
"reviews": "1,512",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAwOTg2MjQ4OTQ5MDI6Ojo6&url=%2Fdp%2FB0CJVQFZ1S%2Fref%3Dsspa_dk_detail_4%3Fpsc%3D1%26pd_rd_i%3DB0CJVQFZ1S%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
},
{
"asin": "B09SQ2L5TN",
"image_url": "https://m.media-amazon.com/images/I/31fozsu8esL._AC_UF480,480_SR480,480_.jpg",
"price": "$110.45",
"product_name": "Turtle Beach Stealth 600 Gen 2 USB Wireless Amplified Gaming Headset - Licensed for Xbox - 24+ Hour Battery, 50mm Speakers, Flip-to-Mute Mic, Spatial Audio - Arctic Camo",
"rating": "4",
"reviews": "145",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDA2NTE4MjYyODk2MDI6Ojo6&url=%2Fdp%2FB09SQ2L5TN%2Fref%3Dsspa_dk_detail_5%3Fpsc%3D1%26pd_rd_i%3DB09SQ2L5TN%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy%26smid%3DA1FCRFKT22GDXL"
},
{
"asin": "B006W41W82",
"image_url": "https://m.media-amazon.com/images/I/41D0RxWgrYL._AC_UF480,480_SR480,480_.jpg",
"price": "$222.99",
"product_name": "Turtle Beach Ear Force XP300 Wireless Gaming Headset - Xbox 360",
"rating": "3",
"reviews": "278",
"url": "https://www.amazon.com/sspa/click?ie=UTF8&spc=MTo1NTQ0MDEwMjQ2MjMxMTk1OjE3Mzk5MDYyOTQ6c3BfZGV0YWlsMjozMDAwMTEwNDY2NjM3MDI6Ojo6&url=%2Fdp%2FB006W41W82%2Fref%3Dsspa_dk_detail_6%3Fpsc%3D1%26pd_rd_i%3DB006W41W82%26pd_rd_w%3DBrv5A%26content-id%3Damzn1.sym.953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_p%3D953c7d66-4120-4d22-a777-f19dbfa69309%26pf_rd_r%3DV9NQ5JPN2WB7W3HWZYDM%26pd_rd_wg%3DMOkSO%26pd_rd_r%3D6803a5fa-0bba-4a1a-996a-8c96a480b9ad%26s%3Dvideogames%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9kZXRhaWwy"
}
],
"url": "https://www.amazon.com/Turtle-Stealth-Wireless-Multiplatform-Amplified-Headset/dp/B0DB96KTGL/ref=sr_1_9?crid=2YJWXJ9P0M24X&dib=eyJ2IjoiMSJ9.oX9G_sVgqcJJO9XV5pAoCyLrrwpKF-Gnu_6hhezCxnolWNSnxVSiZ3y4jk5rbStSX3Z4dcJQcG4aQaPjflLCG_D0BS2Hcdv27z4Jz2cuovYlJqKvZgLDNQaX9XLAvVnGTwuY6idKjb9EuQZKL2ifD5GJp3VQwej_FMDNQobKf4hCFtvtZBgulAkeJXMmSlnipwL-AUILX0MPaMU-sjjOve-PfeaGxim_AYp8kiM-jyQ.UvPT60Xyv4Hq2ekKXmkKU_towb_KESzBBlDsMMWs-34&dib_tag=se&keywords=gaming%2Bheadphones&qid=1739906138&sprefix=gaming%2Bheadphones%2Caps%2C299&sr=8-9&th=1",
"variation_asin": [
{
"asin": "B0CYWLSCFW",
"edition": "Stealth 500 XB"
},
{
"asin": "B0DB9HZVZV",
"edition": "Stealth 700 XB"
},
{
"asin": "B0DB96KTGL",
"edition": "Stealth 700 XB"
},
{
"asin": "B0DVZ9ZDMD",
"edition": "Stealth 500 XB"
},
{
"asin": "B0CYWFH5Y9",
"edition": "Stealth 600 XB"
},
{
"asin": "B0CYWDPYF4",
"edition": "Stealth 600 XB"
},
{
"asin": "B0CYWLSCFW",
"color_name": "Black"
},
{
"asin": "B0DB9HZVZV",
"color_name": "Black"
},
{
"asin": "B0DB96KTGL",
"color_name": "Cobalt"
},
{
"asin": "B0DVZ9ZDMD",
"color_name": "Black/Arctic Camo"
},
{
"asin": "B0CYWFH5Y9",
"color_name": "Black"
},
{
"asin": "B0CYWDPYF4",
"color_name": "White"
}
]
}
]
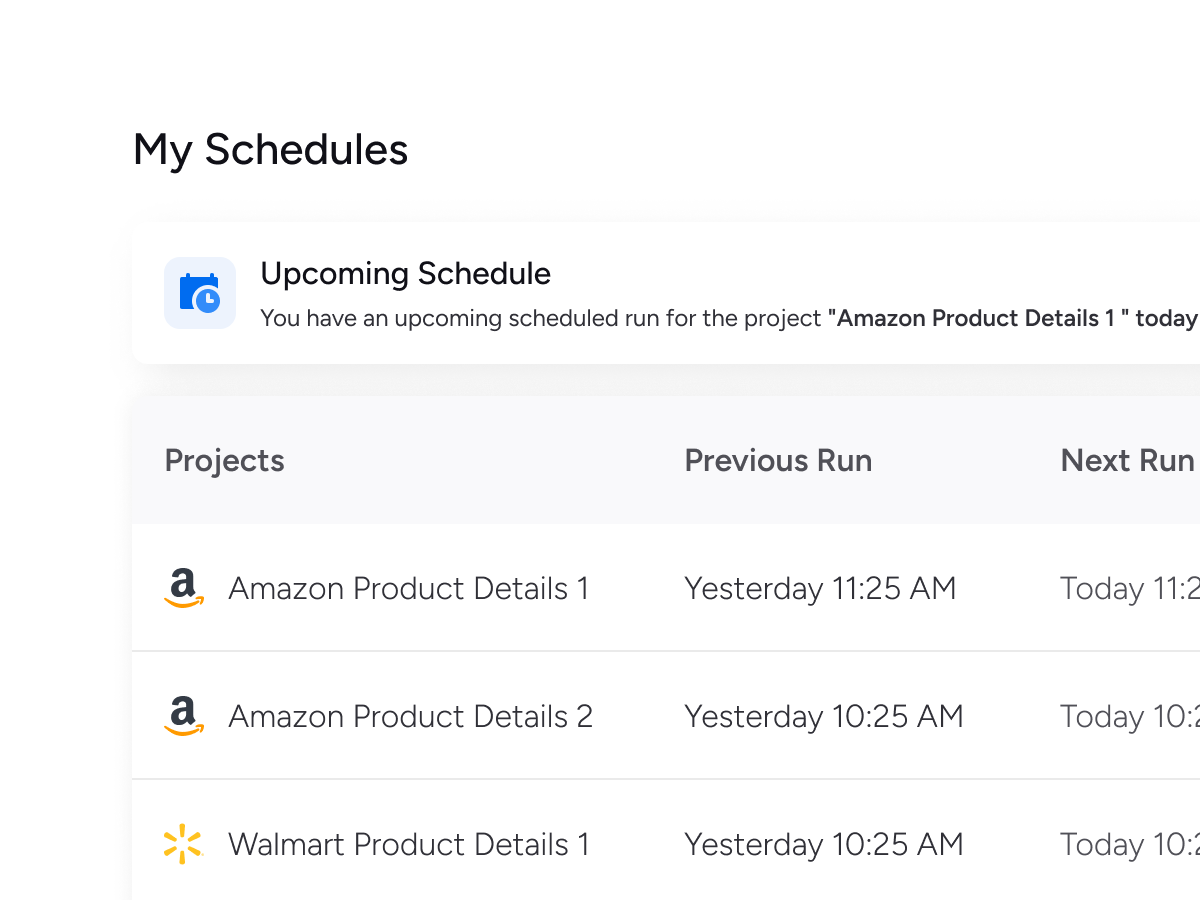
You can scrape Amazon product details within minutes using a few clicks. All you have to do is, provide product ASIN or URL.
This crawler should work for:
We have a wide variety of Amazon scrapers and Real-Time APIs available in our Marketplace. You can use these web scraping tools to extract more data from Amazon.
Does not renew
Compare all features &
choose what works best for you
Need More?
Contact us for a custom plan based on your needs.
Join 12400+ customers who love working with ScrapeHero
A few mouse clicks and copy/paste is all that it takes!
Get data like the pros without knowing programming at all.
The crawlers are easy to use, but we are here to help when you need help.

Schedule the crawlers to run hourly, daily, or weekly and get data delivered to your Dropbox.
We will take care of all website structure changes and blocking from websites.
Can’t find what you’re looking for? Check out Cloud Support for assistance!
All our plans require a subscription that renews monthly. If you only need to use our services for a month, you can subscribe to our service for one month and cancel your subscription in less than 30 days.
Yes. You can set up the crawler to run periodically by clicking and selecting your preferred schedule. You can schedule crawlers to run on a Monthly, Weekly, or Hourly interval.
No, We won’t use your IP address to scrape the website. We’ll use our proxies and get data for you. All you have to do is, provide the input and run the scraper.
Unfortunately, we will not be able to provide you a refund/data credits if you made a mistake.
Here are some common scenarios we have seen for quota refund requests
If you cancel, you’ll be billed for the current month, but you won’t be charged again. If you have any page credits, you can still use our service until it reaches its limit.
Some crawlers can collect multiple records from a single page, while others might need to go to 3 pages to get a single record. For example, our Amazon Bestsellers crawler collects 50 records from one page, while our Indeed crawler needs to go through a list of all jobs and then move into each job details page to get more data.
All our data credit reset at the end of the billing period. Any unused credits do not carry over to the next billing period and also are nonrefundable. This is consistent with most software subscription services.
Sure, we can build custom solutions for you. Please contact our Sales team using this link, and that will get us started. In your message, please describe in detail what you require.
Most sites will display product pricing, availability and delivery charges based on the user location. Our crawler uses locations from US states so that the pricing may vary. To get accurate results based on a location, please contact us.
Contact us to schedule a brief, introductory call with our experts and learn how we can assist your needs.

Legal Disclaimer: ScrapeHero is an equal opportunity data service provider, a conduit, just like an ISP. We just gather data for our customers responsibly and sensibly. We do not store or resell data. We only provide the technologies and data pipes to scrape publicly available data. The mention of any company names, trademarks or data sets on our site does not imply we can or will scrape them. They are listed only as an illustration of the types of requests we get. Any code provided in our tutorials is for learning only, we are not responsible for how it is used.

