This is an open thread and the goal is to solicit comments on what the best web scraping service may look like. Please go ahead a type away and write down the ideas or requirements…
The traditional understanding of extracting data from the internet is manually copy-pasting the required data. But imagine extracting data from the internet without spending hours copying and pasting data to your spreadsheet. That is what web scraping is about.
But what is web scraping?
Web scraping, otherwise called data scraping, provides a streamlined, automated method to extract data from websites. While the internet overflows with vast quantities of data, accessing this in a structured and efficient way can be challenging. With web scraping, you can collect thousands (or even millions) of web pages on autopilot.
This guide will help you understand everything you need to know about web scraping, exploring what it is, how it works, and the different fields where it can be utilized.
Let’s get started.
What is Web Scraping? How Can it be Used to Extract Data from Websites?
Web scraping, or data scraping or data extraction, is a digital process used for extracting data from websites. This method involves automatically accessing web pages and collecting the data you need from them.
Web scraping can be used in various ways, such as gathering product information from e-commerce sites, obtaining real-time data for analysis, or collecting contact information for business purposes. The process simplifies and automates what would otherwise be a time-consuming task of manually copying and pasting information, making data collection efficient and consistent.
If you don't like or want to code, ScrapeHero Cloud is just right for you!
Skip the hassle of installing software, programming and maintaining the code. Download this data using ScrapeHero cloud within seconds.
Get Started for FreeHow Does Web Scraping Work?
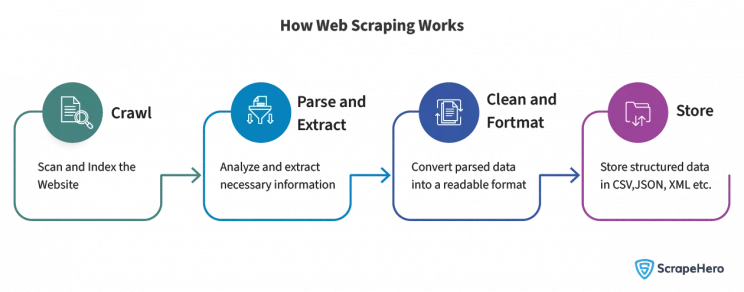
As mentioned, a web scraper extracts data from websites and converts them into readable form. This definition is simple, but there’s much more to it. Keep reading for a step-by-step explanation.
Crawl
Crawl is the initial phase in web scraping, which involves scanning and indexing the website. A web crawler, also known as a spider or bot, systematically browses the website and identifies all the pages that need to be scraped.
For example, if you were to crawl our website, it would start at our homepage, www.scrapehero.com. From there, the crawler would crawl the site by following each link from our homepage. The goal of a web crawler is to learn what’s on a web page and retrieve the data you want.
We’ll discuss the difference between web crawling and data scraping later in this post.
Parse and Extract
Once the website has been crawled, the next step is to analyze the pages and extract the necessary information. Parsing means analyzing the raw data and choosing the essential information you need.
During this stage, web scrapers use data selectors, like CSS selectors or XPath queries, to locate and retrieve the specific data required from the website’s HTML code.
There are different types of parsing techniques. Some include:
- Regular expressions
- HTML parsing
- DOM parsing (using a headless browser)
- Automatic extraction using artificial intelligence
Clean and Format
The data extracted from websites is often raw and unstructured. This step converts the parsed data into a readable and usable format. It involves cleaning the data by removing any irrelevant content or formatting issues and then organizing it into a structured form, such as a table or a list.
These are some of the methods used by web scraping tools to clean up the data:
- Regular expressions
- String manipulation
- Search methods
Store
The final step in extracting data from websites is to store the structured data in a format that is convenient for future use or analysis. Common formats include CSV, JSON, and XML. The data can be stored in the cloud using services like Dropbox or Google Drive. You could even put large data in databases, data warehouses, or even simple spreadsheet files, depending on the user’s needs.
Methods to Extract Data from Websites Using Web Scraping
Now you know what web scraping is and how it works. Let’s understand how to scrape data from a website using the various methods available to do so.
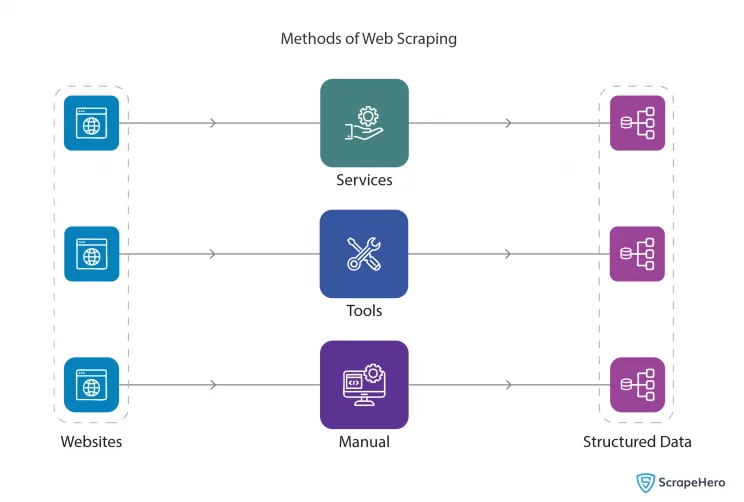
Custom Web Scraping Services
These are custom web scraping services provided by companies that handle the entire process of web scraping for you. They offer tailored solutions for your specific data needs, managing complexities such as large-scale data extraction, handling CAPTCHAs, rotating IPs, and all other methods websites use to block web scraping.
These services are ideal for businesses that require data at scale but do not have the in-house technical expertise or infrastructure to perform web scraping. Custom services can provide data in various formats and often come with support and maintenance options.
Web Scraping Tools and Software
Web scraping tools offer a user-friendly interface that allows users to select the data they want to scrape with point-and-click ease. Some tools require minimal programming knowledge, while others might offer advanced features for users with more technical expertise.
They are suitable for individuals or businesses that need to scrape data on a smaller scale or those who want to have more control over the scraping process without fully building a solution from scratch.
ScrapeHero Cloud offers many pre-built scrapers that facilitate the scraping of relevant data without the need for software installation or programming expertise. Using our cloud software, you can access the scraper and data from all IP addresses and deliver findings to DropBox. This means your desktop won’t run out of storage from scraping.
Web Scraping on Your Own
Web scraping on your own involves writing code to extract data from websites. It provides the most flexibility and customization but requires a good understanding of programming and knowledge of web technologies such as HTML, CSS, and possibly JavaScript.
Commonly used languages for writing web scraping scripts include Python and JavaScript. Open-source scraping tools like BeautifulSoup and Scrapy are also opted by developers. Learning to scrape on your own by relying on reliable web scraping tutorials will be beneficial if you are interested in it.
This method is cost-effective and can be a valuable skill for data scientists, developers, or anyone comfortable with coding. However, it also means that you are responsible for handling all aspects of the scraping process, including data extraction, error handling, and maintaining the code when website layouts change.
When you’re scraping data on your own, scalability can also become a significant issue due to several factors. As the amount of data you want to scrape increases, the demand for your system’s resources also grows. In that case, the better choice would be to rely on a web scraping service provider.
A time-saving approach to scraping data yourself is to prompt large language models such as ChatGPT to generate scraping scripts.
Why Extract Data from Websites: Popular Use Cases of Web Scraping
Why should you extract data from websites is a question as relevant as understanding what is data scraping. Let us discuss some of the popular use cases of web scraping.
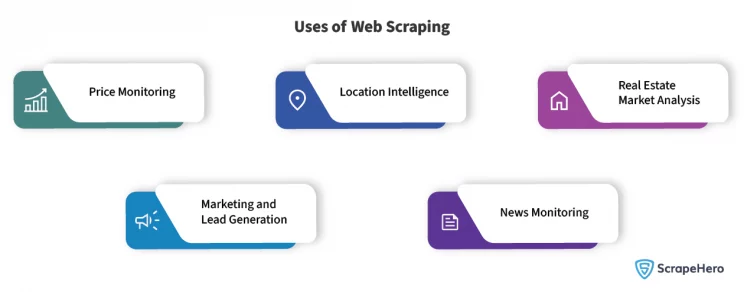
Web Scraping can be used for extracting data for many different purposes. Some of these include:
- Price monitoring
- Location Intelligence
- Real Estate Market Analysis
- Marketing and lead generation
- News Monitoring
Price Monitoring
In the e-commerce sector, price monitoring is a strategy used to keep track of competitors‘ pricing and products. By utilizing web scraping, businesses can gather data on prices, stock levels, and customer reviews from various retailers, such as Amazon, eBay, and Target, as well as other online stores.
This information is crucial for benchmarking products against competitors and can lead to enhanced online sales.
Achieving Competitive Pricing
Businesses can employ web scraping to adjust their pricing in response to competitive market trends, thereby capturing customer interest. For example, if a company selling beauty products notices through data that competitors have higher prices, they can reduce their prices to increase sales potentially.
Capitalizing on Low Competition
During seasons of low competition for specific products, price monitoring can identify these opportunities. Recognizing this situation allows a company to increase its prices and maximize profits.
Understanding Customer Preferences
Price monitoring can also help understand customer preferences. If the demand for a product decreases consistently, it may indicate shifting consumer interests. With this knowledge, businesses can adapt and introduce these new products to their inventory.
Scheduling Timely Promotions
Running promotions at the wrong time can be detrimental, especially if competitors have recently reduced prices. With price monitoring, businesses can strategize their promotions based on market conditions. They can plan the timing, ensuring they offer competitive prices that attract customers.
Monitoring New Entrants in the Market
Web scraping can track new market entrants, providing businesses with the intelligence to adjust their strategies and remain competitive.
Location Data
For new businesses uncertain about where to establish themselves, web scraping can accumulate location data. Web scrapers can collect location data from publicly available sources for industries like
- Restaurants
- Hotels
- Franchisees
- Retailers
- Warehouse management
Analyzing this data helps determine the most favorable business locations.
Real Estate Market Analysis
The real estate industry greatly benefits from web scraping, not just for listing properties but also for gathering information on foreclosures, estate agents, and permits.
Use cases of real estate data include:
Strategic Real Estate Investing
Investors can spot potential hotspots for profitable investments using scraped real estate data for specific areas or zip codes, like average property prices, historical property values, and neighborhood details. Insights into market trends and future property price projections can help investors manage risks and boost the likelihood of substantial investment returns.
Informed Home Purchasing
Buyers can use real estate data to compare the prices of similar properties in their preferred areas, comprehend value trends, and evaluate the proximity of amenities such as schools, retail areas, and parks. This information can support home buyers in making informed decisions that align with their financial capacities and lifestyle requirements.
Empowering Real Estate Professionals
Real estate agents and brokers can utilize real estate data to understand a specific market segment fully. This includes comprehending average property pricing, buyer preferences, historical data on property sales, and more for a chosen location. With this data, agents can effectively pair their properties with potential buyers and set competitive prices for the properties they handle.
Guiding Property Developers and Builders
For developers and builders, real estate data can provide insights into the types of properties in demand within a particular area or zip code. By recognizing trends in housing demand, developers can make strategic decisions about what properties to construct.
Informing Government Planning and Policy-Making
Policymakers can use data to make informed decisions about housing policies and zoning regulations. For example, if data reveals a shortage of affordable housing in a specific region, policymakers might act to encourage developers to create more budget-friendly housing options.
Marketing and Lead Generation
Web scraping aids in several marketing practices by collecting relevant data from the web.
Competitor Analysis
In competitive marketing, understanding what your rivals are doing is crucial. Web scraping allows marketers to extract data from competitor websites to gain insights into pricing strategies, promotional campaigns, and new product launches.
Sentiment Analysis
Marketers can use web scraping to gauge public sentiment about their products or brands with the vast data generated on social media platforms. By scraping data from social media posts, reviews, and comments, marketers can identify patterns and trends in consumer attitudes, helping them adjust their strategies based on real-time feedback.
SEO Optimization
Marketers can extract data from search engine results pages (SERPs) to understand how search engines rank websites based on specific keywords. This can help businesses optimize their content and meta tags to improve their own rankings, driving more organic traffic to their website.
Content Marketing
By scraping trending topics, popular keywords, and viral content from various digital platforms, marketers can gain insights into what type of content resonates with their target audience. This knowledge can be used to create compelling and engaging content that is more likely to attract and retain customers.
Also Read: Web Scraping For Content Marketing
Lead Generation
With web scraping, marketers can gather data from directories, social media platforms, and industry forums to identify potential leads. This data can include contact information, company details, and more, providing marketers with a rich source of potential customers to target with personalized marketing campaigns.
Also Read: The Advantages of Web Scraping Flight Data
News Monitoring
Scraping the news allows businesses, researchers, and individuals to access vast amounts of news data in a structured format, making information more manageable and meaningful.
Use cases of news scraping include
Crisis Management
Businesses can scrape data from news sites to get alerts about negative press coverage immediately after publication. This early warning system allows businesses to respond swiftly, manage the narrative, and mitigate potential damage to their brand image.
Tracking Regulatory Changes
By setting up a web scraper to monitor government websites, legal news outlets, or regulatory bodies, businesses can get real-time updates on regulatory changes that could impact their operations. This enables them to adjust their strategies promptly and maintain compliance.
Verification of Information
Businesses can use web scraping to cross-check information across multiple sources, helping ensure the accuracy of the data they base their decisions on. For instance, a company can scrape data from trusted news outlets and fact-checking websites to verify the validity of a piece of news before acting on it.
Audience Perception Analysis
Understanding how your brand or products are being perceived by your audience is critical for any business. News scraping can provide valuable insights by tracking news articles, blog posts, and online reviews that mention your company or products. By analyzing the sentiment and topics of these mentions, businesses can better understand their audience’s perception, identify potential issues, and develop strategies to enhance their brand image.
Content Creation and Strategy
By scraping trending news topics, companies can identify what content is resonating with their audience. By tracking which articles receive the most shares or comments, businesses can gain insights into what type of content is most likely to go viral, helping them improve their content strategy.
Closing Thoughts
This guide has navigated us through the essentials of web scraping, from understanding what is data scraping to the basics of its operation to its diverse applications across various industries.
It’s clear that this is an important tool in the digital age. Its ability to efficiently gather large volumes of data from the web opens numerous possibilities for businesses, researchers, and individuals.
As we move forward, it is crucial to navigate this field with an understanding of its capabilities, challenges, and ethical implications. By embracing the evolving nature of web scraping, it is possible to unlock the full potential of the vast amounts of data available on the internet.
Frequently Asked Questions
1. What is the difference between web scraping and web crawling?
Web scraping and web crawling are terms often used interchangeably. Although they both extract data from websites, they serve different functions.
Web crawling involves downloading and saving data from websites by following their links. This process is automated by bots, known as crawlers, which can move through pages independently. These crawlers are fundamental for search engines like Google, Bing, and Yahoo.
In contrast, web scraping focuses on the specific structure of a website. It uses this structure to extract specific pieces of information from the site. A web scraper targets precise data such as prices, stock market figures, and business contacts, unlike a web crawler that covers a broader scope.
To put it in simple words, web crawlers scan and index web pages, whereas web scrapers collect specific data from these pages.
2. Is web scraping legal?
Web scraping is a topic of debate, particularly concerning legal issues related to copyright and terms of service. However, proving copyright infringement in web scraping is challenging because only certain types of data are legally protected. Therefore, in many cases, web scrapers can extract data from websites without violating copyright laws.
3. How much does web scraping cost?
The cost of hiring a web scraping service for a simple website ranges from $250 to $500 per month. This price can vary depending on whether the service charges hourly or has a fixed rate.
If you’re considering setting up your own team for web scraping, it’s important to weigh the costs. Although creating an in-house team might seem beneficial, it can be more expensive. Large-scale scraping projects often require at least five full-time employees, meaning you’d be paying five salaries for work best done by outsourcing.
For individuals who are thinking about doing the scraping themselves, the decision depends on their skills and time. If you’re a developer working on a personal project, it might be feasible. However, if time is limited, it might be better to either outsource the task or use a user-friendly tool like ScrapeHero Cloud.
4. How long does web scraping take?
If you manage a company, setting up web scraping, particularly for a continuous project, can take several months. This includes gathering the necessary tools and hiring employees.
For developers, the time it takes to start web scraping varies based on their skills and the amount of data involved. It could range from a few hours to several months.
On the other hand, most web scraping services, such as ScrapeHero, can prepare your website and begin delivering data in a week or less. Since these services specialize in data scraping, they usually have a faster turnaround time.
5. How do I practice ethical web scraping?
Practicing ethical web scraping involves adhering to a set of principles and guidelines to ensure that your web scraping activities are respectful, legal, and responsible. It is important to be mindful of the frequency and volume of your requests to avoid overloading a website’s server, which could disrupt its normal operations.
Ethical web scraping is about being considerate, lawful, and transparent in your data collection efforts.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data